 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-Aware Task Clustering for Federated Cooperative Multi-Task Semantic Communication
Jan 24, 2026Task-oriented semantic communication (SemCom) prioritizes task execution over accurate symbol reconstruction and is well-suited to emerging intelligent applications. Cooperative multi-task SemCom (CMT-SemCom) further improves task execution performance. However, [1] demonstrates that cooperative multi-tasking can be either constructive or destructive. Moreover, the existing CMT-SemCom framework is not directly applicable to distributed multi-user scenarios, such as non-terrestrial satellite networks, where each satellite employs an individual semantic encoder. In this paper, we extend our earlier CMT-SemCom framework to distributed settings by proposing a federated learning (FL) based CMT-SemCom that enables cooperative multi-tasking across distributed users. Moreover, to address performance degradation caused by negative information transfer among heterogeneous tasks, we propose a semantic-aware task clustering method integrated in the FL process to ensure constructive cooperation based on an information-theoretic approach. Unlike common clustering methods that rely on high-dimensional data or feature space similarity, our proposed approach operates in the low-dimensional semantic domain to identify meaningful task relationships. Simulation results based on a LEO satellite network setup demonstrate the effectiveness of our approach and performance gain over unclustered FL and individual single-task SemCom.
Integrating Semantic Communication and Human Decision-Making into an End-to-End Sensing-Decision Framework
Dec 06, 2024As early as 1949, Weaver defined communication in a very broad sense to include all procedures by which one mind or technical system can influence another, thus establishing the idea of semantic communication. With the recent success of machine learning in expert assistance systems where sensed information is wirelessly provided to a human to assist task execution, the need to design effective and efficient communications has become increasingly apparent. In particular, semantic communication aims to convey the meaning behind the sensed information relevant for Human Decision-Making (HDM). Regarding the interplay between semantic communication and HDM, many questions remain, such as how to model the entire end-to-end sensing-decision-making process, how to design semantic communication for the HDM and which information should be provided to the HDM. To address these questions, we propose to integrate semantic communication and HDM into one probabilistic end-to-end sensing-decision framework that bridges communications and psychology. In our interdisciplinary framework, we model the human through a HDM process, allowing us to explore how feature extraction from semantic communication can best support human decision-making. In this sense, our study provides new insights for the design/interaction of semantic communication with models of HDM. Our initial analysis shows how semantic communication can balance the level of detail with human cognitive capabilities while demanding less bandwidth, power, and latency.
Cooperative and Collaborative Multi-Task Semantic Communication for Distributed Sources
Nov 04, 2024



In this paper, we explore a multi-task semantic communication (SemCom) system for distributed sources, extending the existing focus on collaborative single-task execution. We build on the cooperative multi-task processing introduced in [1], which divides the encoder into a common unit (CU) and multiple specific units (SUs). While earlier studies in multi-task SemCom focused on full observation settings, our research explores a more realistic case where only distributed partial observations are available, such as in a production line monitored by multiple sensing nodes. To address this, we propose an SemCom system that supports multi-task processing through cooperation on the transmitter side via split structure and collaboration on the receiver side. We have used an information-theoretic perspective with variational approximations for our end-to-end data-driven approach. Simulation results demonstrate that the proposed cooperative and collaborative multi-task (CCMT) SemCom system significantly improves task execution accuracy, particularly in complex datasets, if the noise introduced from the communication channel is not limiting the task performance too much. Our findings contribute to a more general SemCom framework capable of handling distributed sources and multiple tasks simultaneously, advancing the applicability of SemCom systems in real-world scenarios.
Model-free Reinforcement Learning of Semantic Communication by Stochastic Policy Gradient
May 05, 2023



Motivated by the recent success of Machine Learning tools in wireless communications, the idea of semantic communication by Weaver from 1949 has gained attention. It breaks with Shannon's classic design paradigm by aiming to transmit the meaning, i.e., semantics, of a message instead of its exact version, allowing for information rate savings. In this work, we apply the Stochastic Policy Gradient (SPG) to design a semantic communication system by reinforcement learning, not requiring a known or differentiable channel model - a crucial step towards deployment in practice. Further, we motivate the use of SPG for both classic and semantic communication from the maximization of the mutual information between received and target variables. Numerical results show that our approach achieves comparable performance to a model-aware approach based on the reparametrization trick, albeit with a decreased convergence rate.
Robust Deep Reinforcement Learning Scheduling via Weight Anchoring
Apr 20, 2023Questions remain on the robustness of data-driven learning methods when crossing the gap from simulation to reality. We utilize weight anchoring, a method known from continual learning, to cultivate and fixate desired behavior in Neural Networks. Weight anchoring may be used to find a solution to a learning problem that is nearby the solution of another learning problem. Thereby, learning can be carried out in optimal environments without neglecting or unlearning desired behavior. We demonstrate this approach on the example of learning mixed QoS-efficient discrete resource scheduling with infrequent priority messages. Results show that this method provides performance comparable to the state of the art of augmenting a simulation environment, alongside significantly increased robustness and steerability.
Learning Resource Scheduling with High Priority Users using Deep Deterministic Policy Gradients
Apr 19, 2023Advances in mobile communication capabilities open the door for closer integration of pre-hospital and in-hospital care processes. For example, medical specialists can be enabled to guide on-site paramedics and can, in turn, be supplied with live vitals or visuals. Consolidating such performance-critical applications with the highly complex workings of mobile communications requires solutions both reliable and efficient, yet easy to integrate with existing systems. This paper explores the application of Deep Deterministic Policy Gradient~(\ddpg) methods for learning a communications resource scheduling algorithm with special regards to priority users. Unlike the popular Deep-Q-Network methods, the \ddpg is able to produce continuous-valued output. With light post-processing, the resulting scheduler is able to achieve high performance on a flexible sum-utility goal.
Semantic Communication: An Information Bottleneck View
Apr 28, 2022
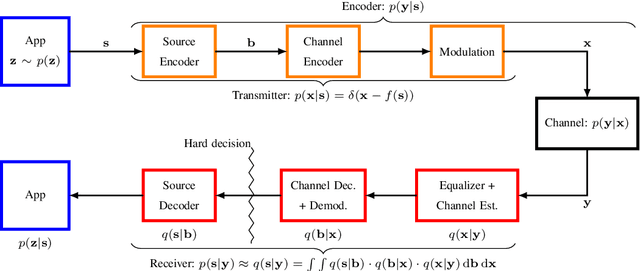


Motivated by recent success of machine learning tools at the PHY layer and driven by high bandwidth demands of the next wireless communication standard 6G, the old idea of semantic communication by Weaver from 1949 has received considerable attention. It breaks with the classic design paradigm according to Shannon by aiming to transmit the meaning of a message rather than its exact copy and thus potentially allows for savings in bandwidth. In this work, inspired by Weaver, we propose an information-theoretic framework where the semantic context is explicitly introduced into probabilistic models. In particular, for bandwidth efficient transmission, we define semantic communication system design as an Information Bottleneck optimization problem and consider important implementation aspects. Further, we uncover the restrictions of the classic 5G communication system design w.r.t. semantic context. Notably, based on the example of distributed image classification, we reveal the huge potential of a semantic communication system design. Numerical results show a tremendous saving in bandwidth of 20 dB with our proposed approach ISCNet compared to a classic PHY layer design.
Deep Reinforcement Model Selection for Communications Resource Allocation in On-Site Medical Care
Nov 12, 2021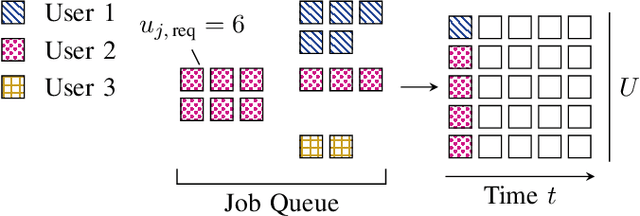


Greater capabilities of mobile communications technology enable interconnection of on-site medical care at a scale previously unavailable. However, embedding such critical, demanding tasks into the already complex infrastructure of mobile communications proves challenging. This paper explores a resource allocation scenario where a scheduler must balance mixed performance metrics among connected users. To fulfill this resource allocation task, we present a scheduler that adaptively switches between different model-based scheduling algorithms. We make use of a deep Q-Network to learn the benefit of selecting a scheduling paradigm for a given situation, combining advantages from model-driven and data-driven approaches. The resulting ensemble scheduler is able to combine its constituent algorithms to maximize a sum-utility cost function while ensuring performance on designated high-priority users.
ConCrete MAP: Learning a Probabilistic Relaxation of Discrete Variables for Soft Estimation with Low Complexity
Feb 25, 2021

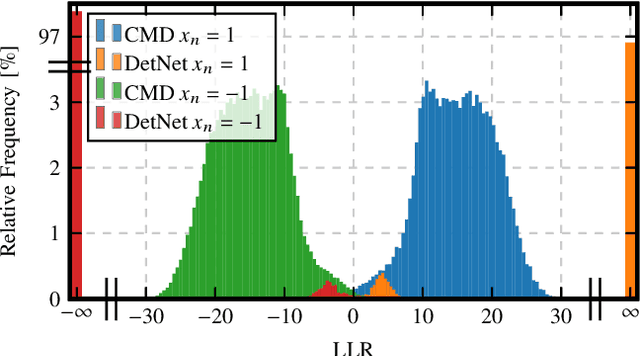

Following the great success of Machine Learning (ML), especially Deep Neural Networks (DNNs), in many research domains in 2010s, several learning-based approaches were proposed for detection in large inverse linear problems, e.g., massive MIMO systems. The main motivation behind is that the complexity of Maximum A-Posteriori (MAP) detection grows exponentially with system dimensions. Instead of using DNNs, essentially being a black-box in its most basic form, we take a slightly different approach and introduce a probabilistic Continuous relaxation of disCrete variables to MAP detection. Enabling close approximation and continuous optimization, we derive an iterative detection algorithm: ConCrete MAP Detection (CMD). Furthermore, by extending CMD to the idea of deep unfolding, we allow for (online) optimization of a small number of parameters to different working points while limiting complexity. In contrast to recent DNN-based approaches, we select the optimization criterion and output of CMD based on information theory and are thus able to learn approximate probabilities of the individual optimal detector. This is crucial for soft decoding in today's communication systems. Numerical simulation results in MIMO systems reveal CMD to feature a promising performance complexity trade-off compared to SotA. Notably, we demonstrate CMD's soft outputs to be reliable for decoders.