 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward-Free Policy Space Compression for Reinforcement Learning
Feb 22, 2022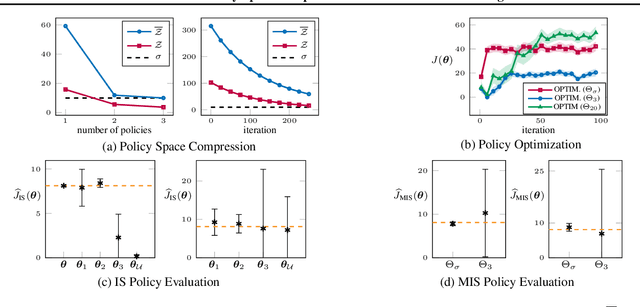

In reinforcement learning, we encode the potential behaviors of an agent interacting with an environment into an infinite set of policies, the policy space, typically represented by a family of parametric functions. Dealing with such a policy space is a hefty challenge, which often causes sample and computation inefficiencies. However, we argue that a limited number of policies are actually relevant when we also account for the structure of the environment and of the policy parameterization, as many of them would induce very similar interactions, i.e., state-action distributions. In this paper, we seek for a reward-free compression of the policy space into a finite set of representative policies, such that, given any policy $\pi$, the minimum R\'enyi divergence between the state-action distributions of the representative policies and the state-action distribution of $\pi$ is bounded. We show that this compression of the policy space can be formulated as a set cover problem, and it is inherently NP-hard. Nonetheless, we propose a game-theoretic reformulation for which a locally optimal solution can be efficiently found by iteratively stretching the compressed space to cover an adversarial policy. Finally, we provide an empirical evaluation to illustrate the compression procedure in simple domains, and its ripple effects in reinforcement learning.