 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generalised Linear Model Framework for Variational Autoencoders based on Exponential Dispersion Families
Jun 11, 2020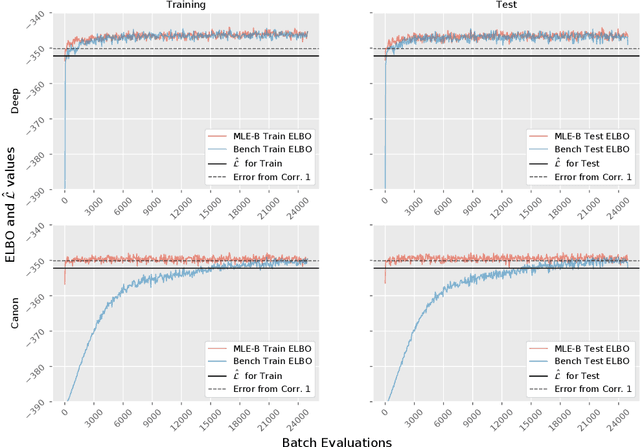


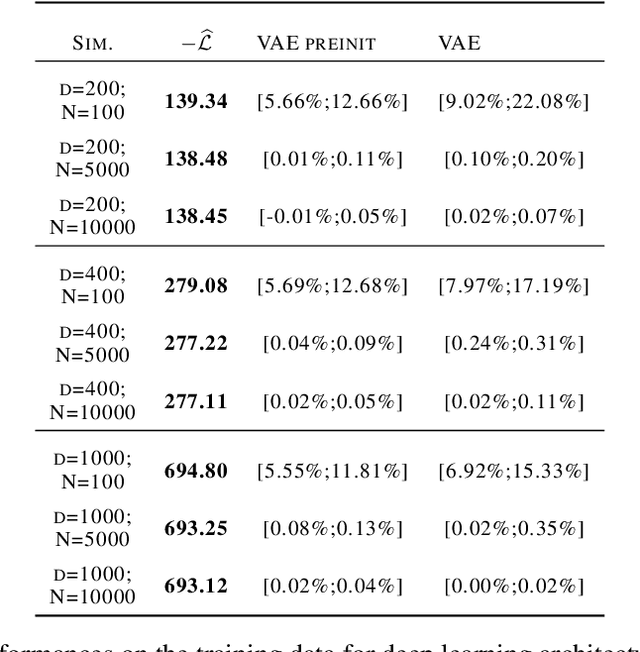
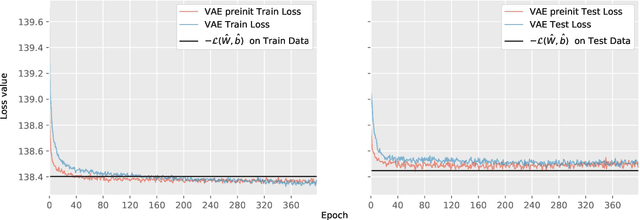
Although variational autoencoders (VAE) are successfully used to obtain meaningful low-dimensional representations for high-dimensional data, aspects of their loss function are not yet fully understood. We introduce a theoretical framework that is based on a connection between VAE and generalized linear models (GLM). The equality between the activation function of a VAE and the inverse of the link function of a GLM enables us to provide a systematic generalization of the loss analysis for VAE based on the assumption that the distribution of the decoder belongs to an exponential dispersion family (EDF). As a further result, we can initialize VAE nets by maximum likelihood estimates (MLE) that enhance the training performance on both synthetic and real world data sets.
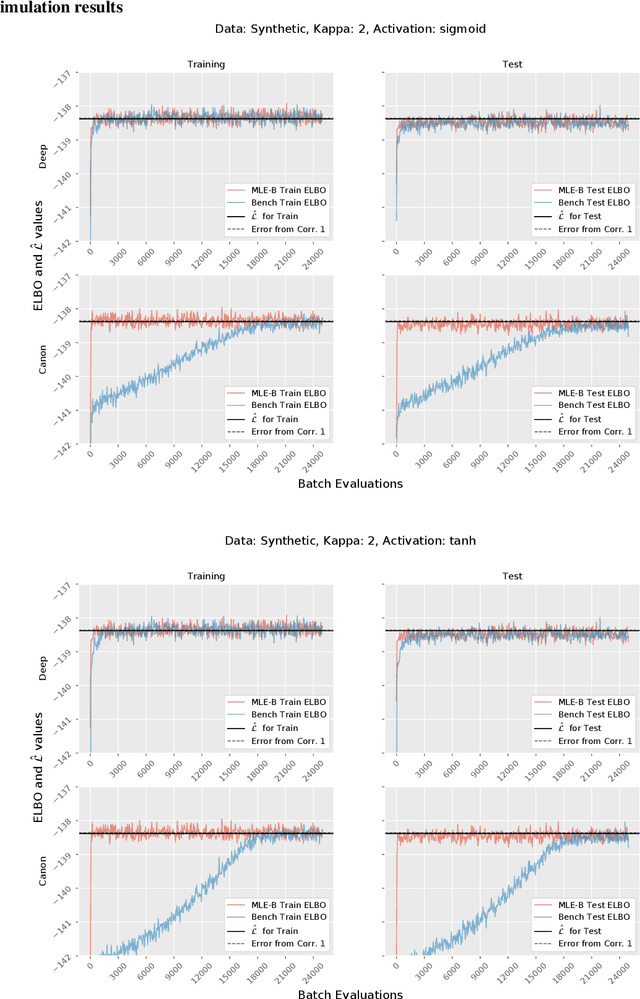
A lower bound for the ELBO of the Bernoulli Variational Autoencoder
Mar 26, 2020
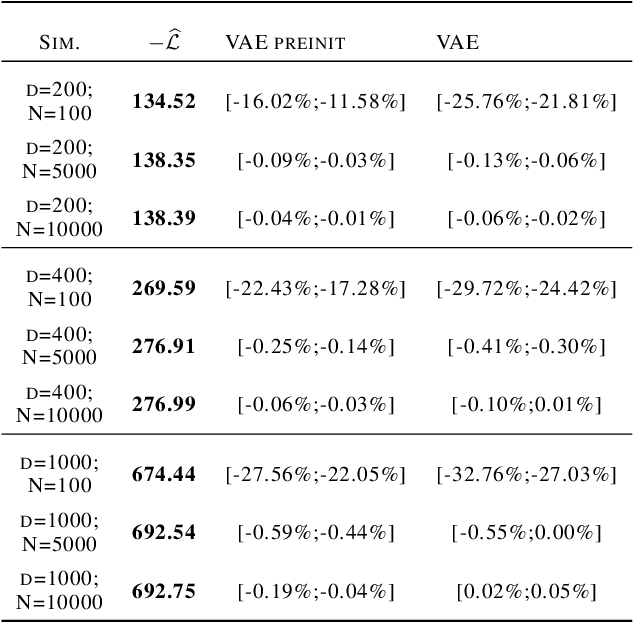
We consider a variational autoencoder (VAE) for binary data. Our main innovations are an interpretable lower bound for its training objective, a modified initialization and architecture of such a VAE that leads to faster training, and a decision support for finding the appropriate dimension of the latent space via using a PCA. Numerical examples illustrate our theoretical result and the performance of the new architecture.