 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNano-ESG: Extracting Corporate Sustainability Information from News Articles
Dec 19, 2024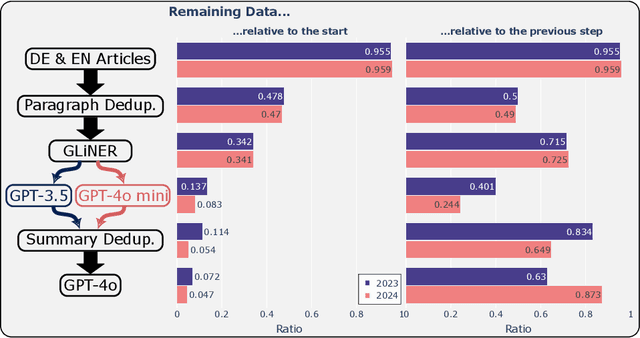

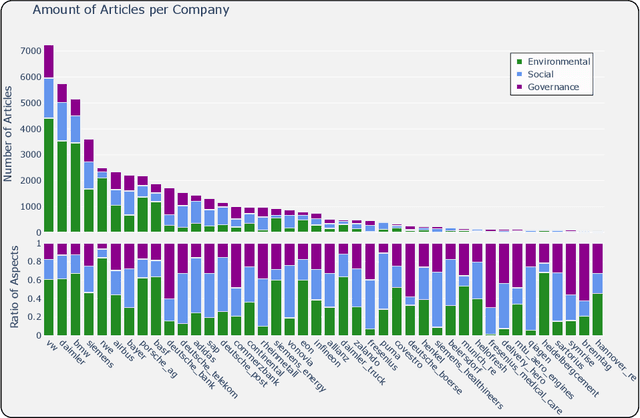

Determining the sustainability impact of companies is a highly complex subject which has garnered more and more attention over the past few years. Today, investors largely rely on sustainability-ratings from established rating-providers in order to analyze how responsibly a company acts. However, those ratings have recently been criticized for being hard to understand and nearly impossible to reproduce. An independent way to find out about the sustainability practices of companies lies in the rich landscape of news article data. In this paper, we explore a different approach to identify key opportunities and challenges of companies in the sustainability domain. We present a novel dataset of more than 840,000 news articles which were gathered for major German companies between January 2023 and September 2024. By applying a mixture of Natural Language Processing techniques, we first identify relevant articles, before summarizing them and extracting their sustainability-related sentiment and aspect using Large Language Models (LLMs). Furthermore, we conduct an evaluation of the obtained data and determine that the LLM-produced answers are accurate. We release both datasets at https://github.com/Bailefan/Nano-ESG.
Towards Fairness and Privacy: A Novel Data Pre-processing Optimization Framework for Non-binary Protected Attributes
Oct 01, 2024The reason behind the unfair outcomes of AI is often rooted in biased datasets. Therefore, this work presents a framework for addressing fairness by debiasing datasets containing a (non-)binary protected attribute. The framework proposes a combinatorial optimization problem where heuristics such as genetic algorithms can be used to solve for the stated fairness objectives. The framework addresses this by finding a data subset that minimizes a certain discrimination measure. Depending on a user-defined setting, the framework enables different use cases, such as data removal, the addition of synthetic data, or exclusive use of synthetic data. The exclusive use of synthetic data in particular enhances the framework's ability to preserve privacy while optimizing for fairness. In a comprehensive evaluation, we demonstrate that under our framework, genetic algorithms can effectively yield fairer datasets compared to the original data. In contrast to prior work, the framework exhibits a high degree of flexibility as it is metric- and task-agnostic, can be applied to both binary or non-binary protected attributes, and demonstrates efficient runtime.
Measuring and Mitigating Bias for Tabular Datasets with Multiple Protected Attributes
May 29, 2024



Motivated by the recital (67) of the current corrigendum of the AI Act in the European Union, we propose and present measures and mitigation strategies for discrimination in tabular datasets. We specifically focus on datasets that contain multiple protected attributes, such as nationality, age, and sex. This makes measuring and mitigating bias more challenging, as many existing methods are designed for a single protected attribute. This paper comes with a twofold contribution: Firstly, new discrimination measures are introduced. These measures are categorized in our framework along with existing ones, guiding researchers and practitioners in choosing the right measure to assess the fairness of the underlying dataset. Secondly, a novel application of an existing bias mitigation method, FairDo, is presented. We show that this strategy can mitigate any type of discrimination, including intersectional discrimination, by transforming the dataset. By conducting experiments on real-world datasets (Adult, Bank, Compas), we demonstrate that de-biasing datasets with multiple protected attributes is achievable. Further, the transformed fair datasets do not compromise any of the tested machine learning models' performances significantly when trained on these datasets compared to the original datasets. Discrimination was reduced by up to 83% in our experimentation. For most experiments, the disparity between protected groups was reduced by at least 7% and 27% on average. Generally, the findings show that the mitigation strategy used is effective, and this study contributes to the ongoing discussion on the implementation of the European Union's AI Act.
Trusting Fair Data: Leveraging Quality in Fairness-Driven Data Removal Techniques
May 21, 2024In this paper, we deal with bias mitigation techniques that remove specific data points from the training set to aim for a fair representation of the population in that set. Machine learning models are trained on these pre-processed datasets, and their predictions are expected to be fair. However, such approaches may exclude relevant data, making the attained subsets less trustworthy for further usage. To enhance the trustworthiness of prior methods, we propose additional requirements and objectives that the subsets must fulfill in addition to fairness: (1) group coverage, and (2) minimal data loss. While removing entire groups may improve the measured fairness, this practice is very problematic as failing to represent every group cannot be considered fair. In our second concern, we advocate for the retention of data while minimizing discrimination. By introducing a multi-objective optimization problem that considers fairness and data loss, we propose a methodology to find Pareto-optimal solutions that balance these objectives. By identifying such solutions, users can make informed decisions about the trade-off between fairness and data quality and select the most suitable subset for their application.
Sense disambiguation of compound constituents
Apr 01, 2022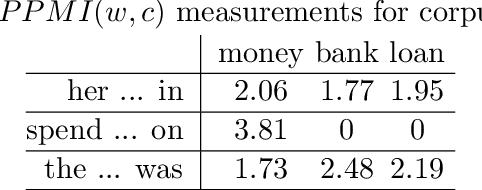

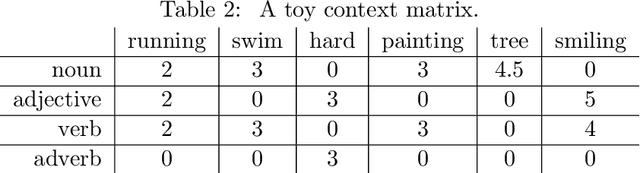
In distributional semantic accounts of the meaning of noun-noun compounds (e.g. starfish, bank account, houseboat) the important role of constituent polysemy remains largely unaddressed(cf. the meaning of star in starfish vs. star cluster vs. star athlete). Instead of semantic vectors that average over the different meanings of a constituent, disambiguated vectors of the constituents would be needed in order to see what these more specific constituent meanings contribute to the meaning of the compound as a whole. This paper presents a novel approach to this specific problem of word sense disambiguation: set expansion. We build on the approach developed by Mahabal et al. (2018) which was originally designed to solve the analogy problem. We modified their method in such a way that it can address the problem of sense disambiguation of compound constituents. The results of experiments with a data set of almost 9000 compounds (LADEC, Gagn\'e et al. 2019) suggest that this approach is successful, yet the success is sensitive to the frequency with which the compounds are attested.
Fast Multi-Level Foreground Estimation
Jun 26, 2020

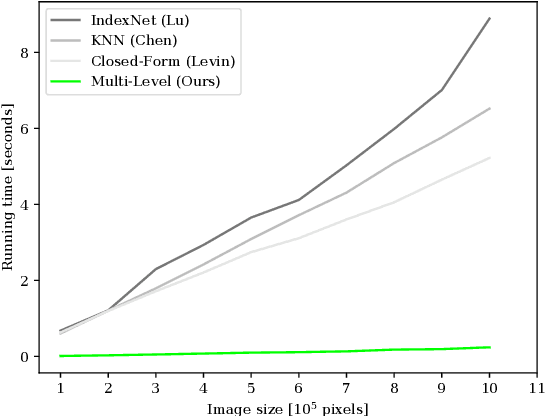
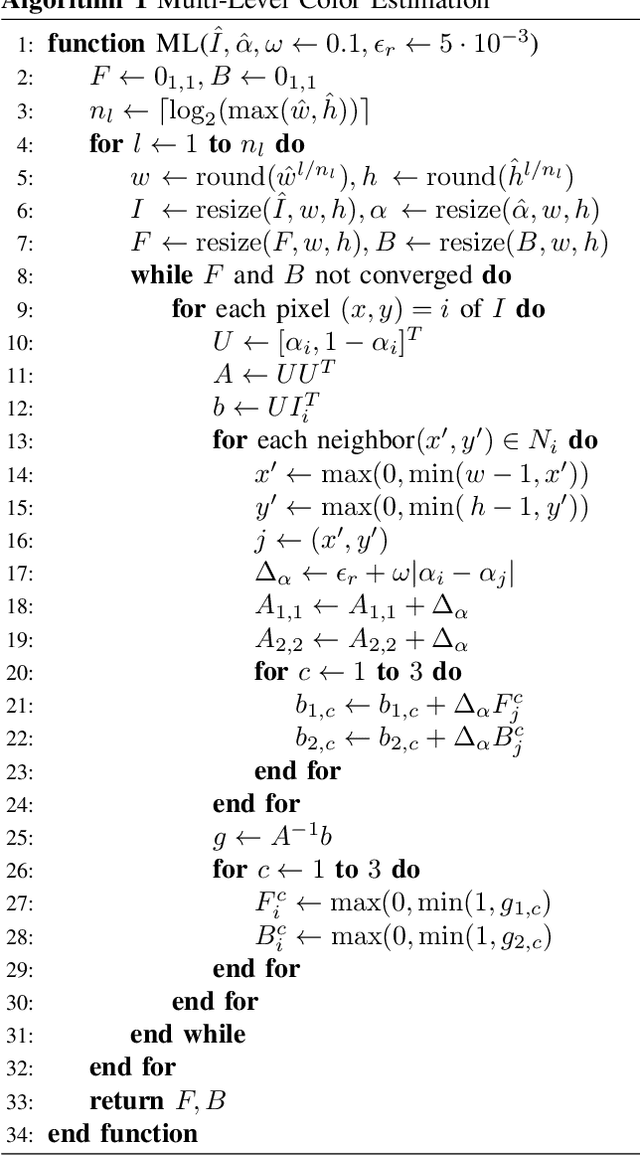
Alpha matting aims to estimate the translucency of an object in a given image. The resulting alpha matte describes pixel-wise to what amount foreground and background colors contribute to the color of the composite image. While most methods in literature focus on estimating the alpha matte, the process of estimating the foreground colors given the input image and its alpha matte is often neglected, although foreground estimation is an essential part of many image editing workflows. In this work, we propose a novel method for foreground estimation given the alpha matte. We demonstrate that our fast multi-level approach yields results that are comparable with the state-of-the-art while outperforming those methods in computational runtime and memory usage.
PyMatting: A Python Library for Alpha Matting
Mar 25, 2020
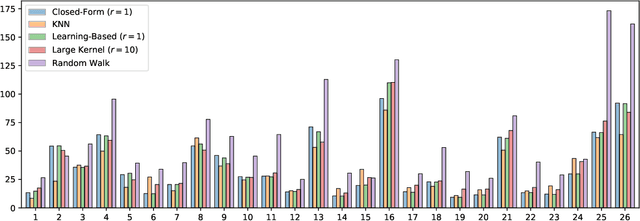
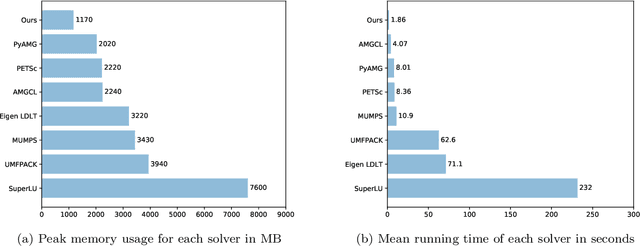
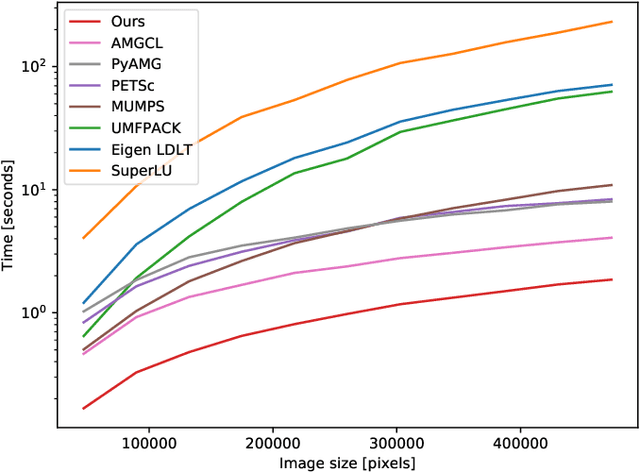
An important step of many image editing tasks is to extract specific objects from an image in order to place them in a scene of a movie or compose them onto another background. Alpha matting describes the problem of separating the objects in the foreground from the background of an image given only a rough sketch. We introduce the PyMatting package for Python which implements various approaches to solve the alpha matting problem. Our toolbox is also able to extract the foreground of an image given the alpha matte. The implementation aims to be computationally efficient and easy to use. The source code of PyMatting is available under an open-source license at https://github.com/pymatting/pymatting.
On (Commercial) Benefits of Automatic Text Summarization Systems in the News Domain: A Case of Media Monitoring and Media Response Analysis
Jan 03, 2017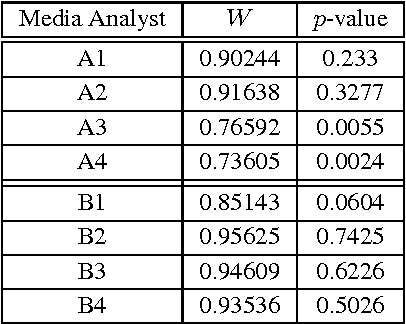
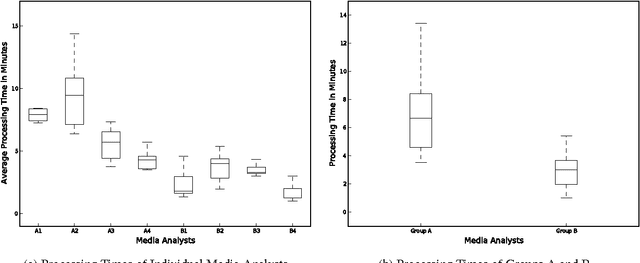
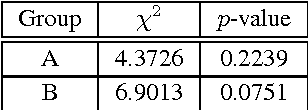
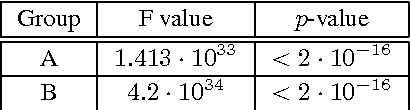
In this work, we present the results of a systematic study to investigate the (commercial) benefits of automatic text summarization systems in a real world scenario. More specifically, we define a use case in the context of media monitoring and media response analysis and claim that even using a simple query-based extractive approach can dramatically save the processing time of the employees without significantly reducing the quality of their work.