 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSICNN: Soft Interference Cancellation Inspired Neural Network Equalizers
Aug 24, 2023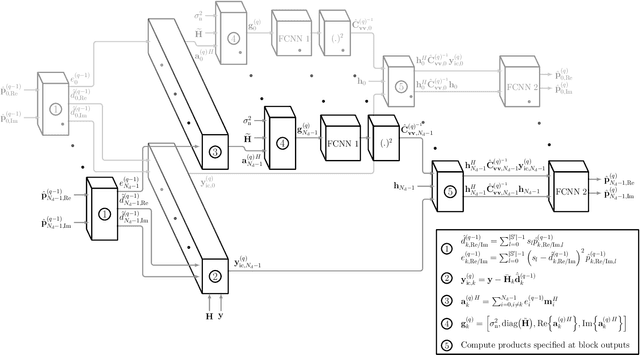
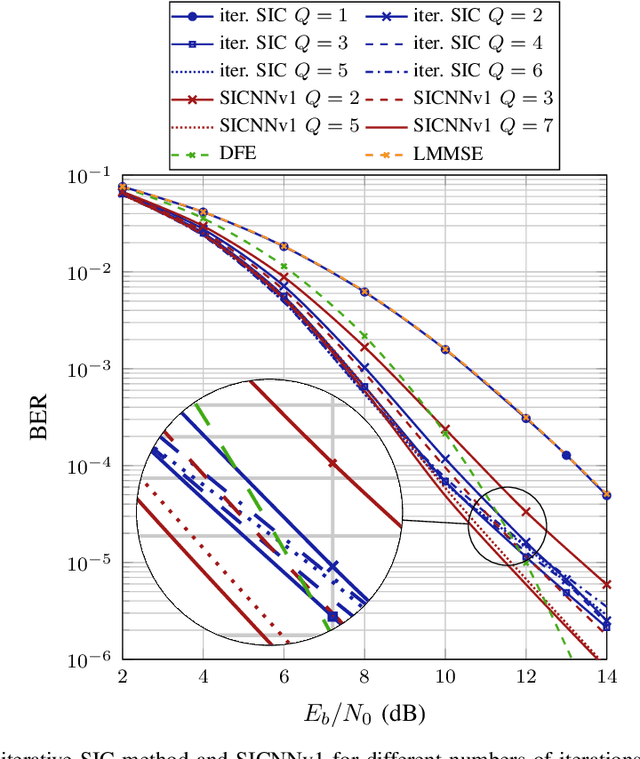
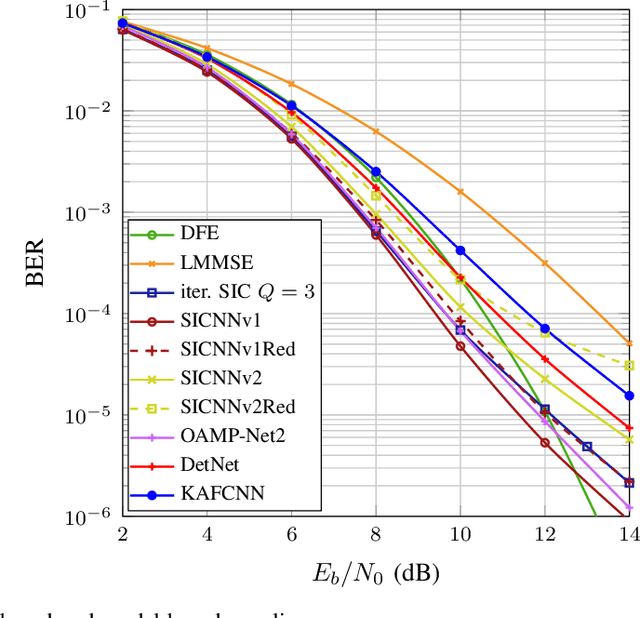
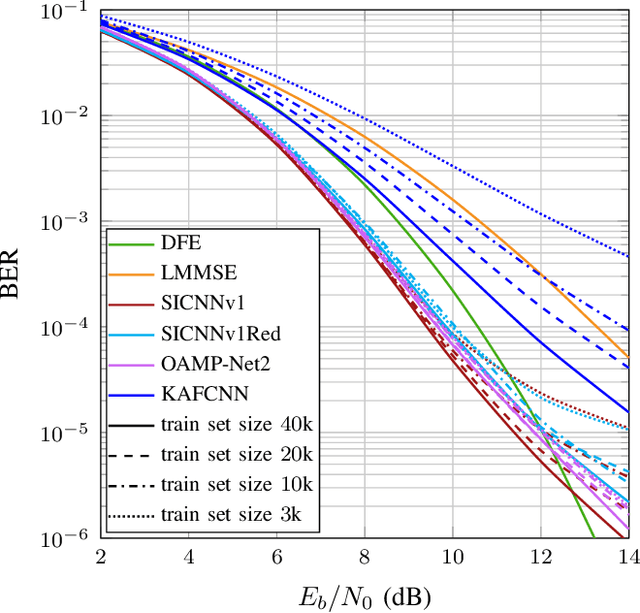
Equalization is an important task at the receiver side of a digital wireless communication system, which is traditionally conducted with model-based estimation methods. Among the numerous options for model-based equalization, iterative soft interference cancellation (SIC) is a well-performing approach since error propagation caused by hard decision data symbol estimation during the iterative estimation procedure is avoided. However, the model-based method suffers from high computational complexity and performance degradation due to required approximations. In this work, we propose a novel neural network (NN-)based equalization approach, referred to as SICNN, which is designed by deep unfolding of a model-based iterative SIC method, eliminating the main disadvantages of its model-based counterpart. We present different variants of SICNN. SICNNv1 is very similar to the model-based method, and is specifically tailored for single carrier frequency domain equalization systems, which is the communication system we regard in this work. The second variant, SICNNv2, is more universal, and is applicable as an equalizer in any communication system with a block-based data transmission scheme. We highlight the pros and cons of both variants. Moreover, for both SICNNv1 and SICNNv2 we present a version with a highly reduced number of learnable parameters. We compare the achieved bit error ratio performance of the proposed NN-based equalizers with state-of-the-art model-based and NN-based approaches, highlighting the superiority of SICNNv1 over all other methods. Also, we present a thorough complexity analysis of the proposed NN-based equalization approaches, and we investigate the influence of the training set size on the performance of NN-based equalizers.
Neural Network Approaches for Data Estimation in Unique Word OFDM Systems
Nov 11, 2022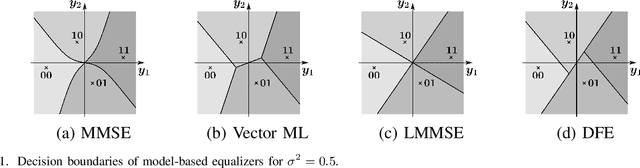
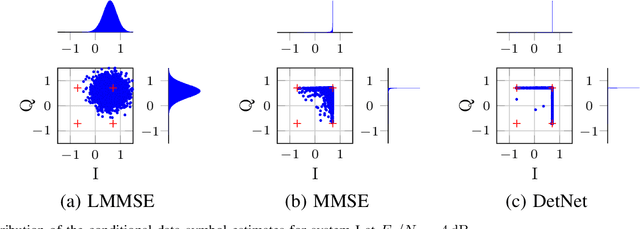
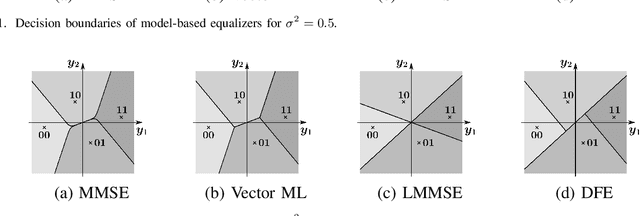
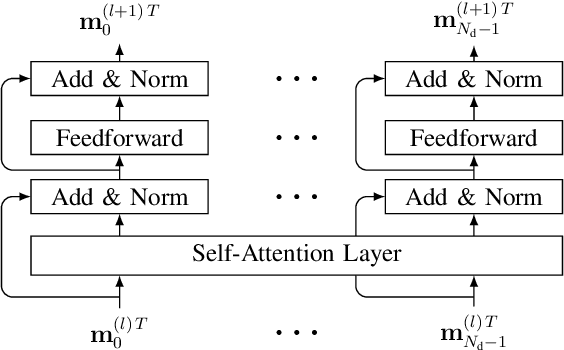
Data estimation is conducted with model-based estimation methods since the beginning of digital communications. However, motivated by the growing success of machine learning, current research focuses on replacing model-based data estimation methods by data-driven approaches, mainly neural networks (NNs). In this work, we particularly investigate the incorporation of existing model knowledge into data-driven approaches, which is expected to lead to complexity reduction and / or performance enhancement. We describe three different options, namely "model-inspired'' pre-processing, choosing an NN architecture motivated by the properties of the underlying communication system, and inferring the layer structure of an NN with the help of model knowledge. Most of the current publications on NN-based data estimation deal with general multiple-input multiple-output communication (MIMO) systems. In this work, we investigate NN-based data estimation for so-called unique word orthogonal frequency division multiplexing (UW-OFDM) systems. We highlight differences between UW-OFDM systems and general MIMO systems one has to be aware of when using NNs for data estimation, and we introduce measures for successful utilization of NN-based data estimators in UW-OFDM systems. Further, we investigate the use of NNs for data estimation when channel coded data transmission is conducted, and we present adaptions to be made, such that NN-based data estimators provide satisfying performance for this case. We compare the presented NNs concerning achieved bit error ratio performance and computational complexity, we show the peculiar distributions of their data estimates, and we also point out their downsides compared to model-based equalizers.
Efficient Majority Voting in Digital Hardware
Aug 09, 2021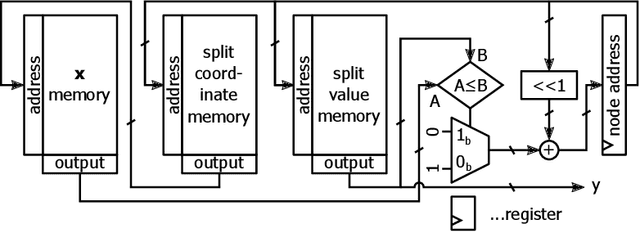
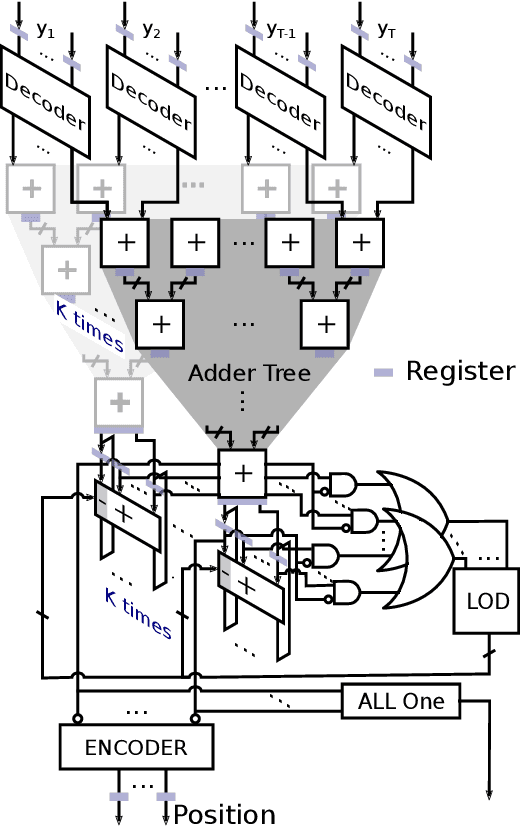
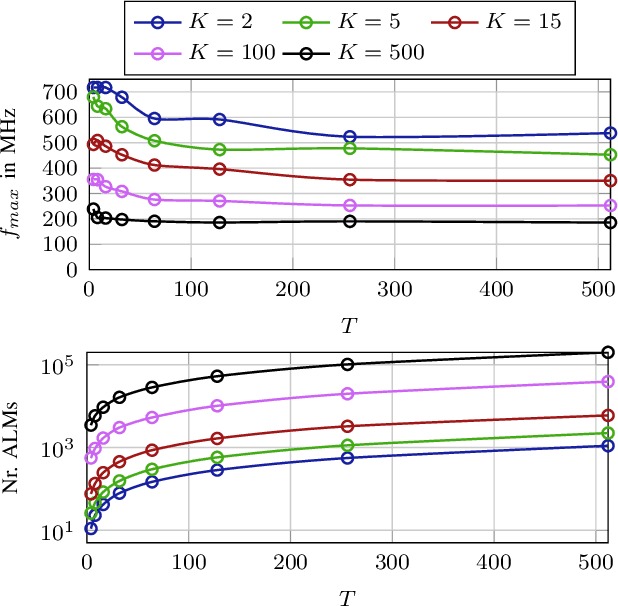
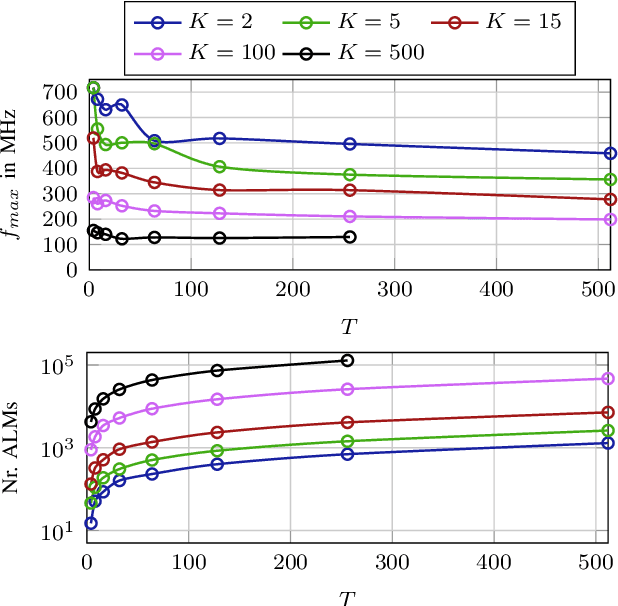
In recent years, machine learning methods became increasingly important for a manifold number of applications. However, they often suffer from high computational requirements impairing their efficient use in real-time systems, even when employing dedicated hardware accelerators. Ensemble learning methods are especially suitable for hardware acceleration since they can be constructed from individual learners of low complexity and thus offer large parallelization potential. For classification, the outputs of these learners are typically combined by majority voting, which often represents the bottleneck of a hardware accelerator for ensemble inference. In this work, we present a novel architecture that allows obtaining a majority decision in a number of clock cycles that is logarithmic in the number of inputs. We show, that for the example application of handwritten digit recognition a random forest processing engine employing this majority decision architecture implemented on an FPGA allows the classification of more than seven million images per second.