 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShort-term Renewable Energy Forecasting in Greece using Prophet Decomposition and Tree-based Ensembles
Jul 08, 2021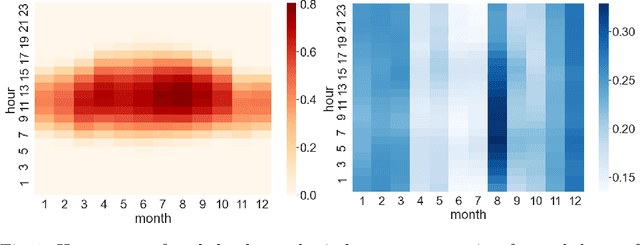
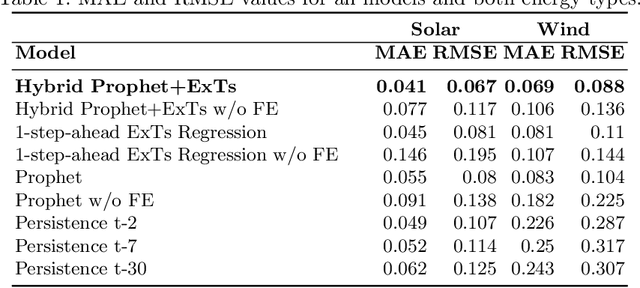
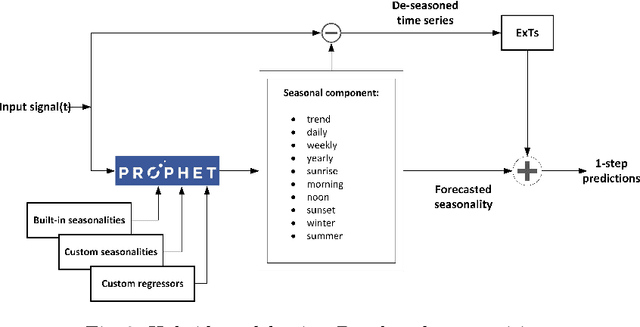
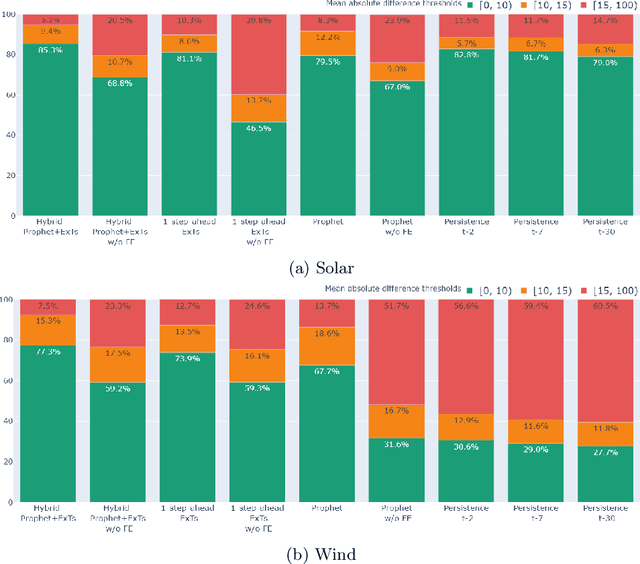
Energy production using renewable sources exhibits inherent uncertainties due to their intermittent nature. Nevertheless, the unified European energy market promotes the increasing penetration of renewable energy sources (RES) by the regional energy system operators. Consequently, RES forecasting can assist in the integration of these volatile energy sources, since it leads to higher reliability and reduced ancillary operational costs for power systems. This paper presents a new dataset for solar and wind energy generation forecast in Greece and introduces a feature engineering pipeline that enriches the dimensional space of the dataset. In addition, we propose a novel method that utilizes the innovative Prophet model, an end-to-end forecasting tool that considers several kinds of nonlinear trends in decomposing the energy time series before a tree-based ensemble provides short-term predictions. The performance of the system is measured through representative evaluation metrics, and by estimating the model's generalization under an industryprovided scheme of absolute error thresholds. The proposed hybrid model competes with baseline persistence models, tree-based regression ensembles, and the Prophet model, managing to outperform them, presenting both lower error rates and more favorable error distribution.
ETHOS: an Online Hate Speech Detection Dataset
Jun 11, 2020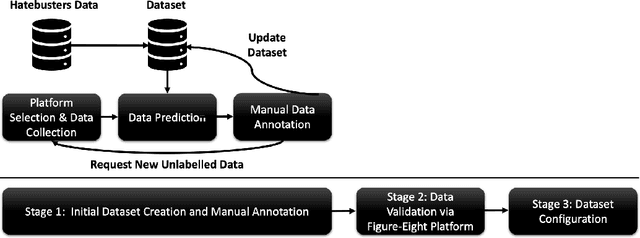
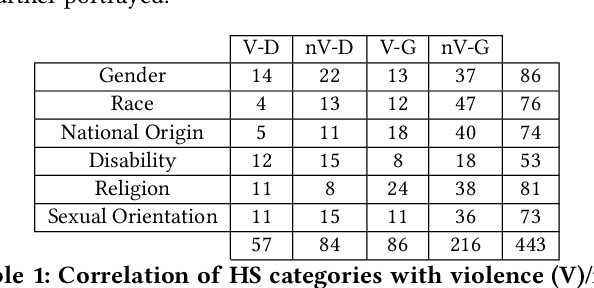
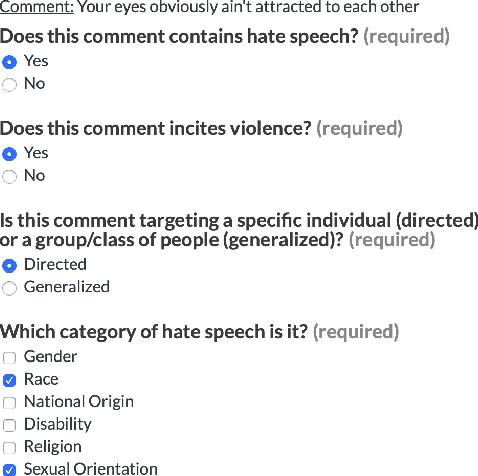

Online hate speech is a newborn problem in our modern society which is growing at a steady rate exploiting weaknesses of the corresponding regimes that characterise several social media platforms. Therefore, this phenomenon is mainly cultivated through such comments, either during users' interaction or on posted multimedia context. Nowadays, giant companies own platforms where many millions of users log in daily. Thus, protection of their users from exposure to similar phenomena for keeping up with the corresponding law, as well as for retaining a high quality of offered services, seems mandatory. Having a robust and reliable mechanism for identifying and preventing the uploading of related material would have a huge effect on our society regarding several aspects of our daily life. On the other hand, its absence would deteriorate heavily the total user experience, while its erroneous operation might raise several ethical issues. In this work, we present a protocol for creating a more suitable dataset, regarding its both informativeness and representativeness aspects, favouring the safer capture of hate speech occurrence, without at the same time restricting its applicability to other classification problems. Moreover, we produce and publish a textual dataset with two variants: binary and multi-label, called `ETHOS', based on YouTube and Reddit comments validated through figure-eight crowdsourcing platform. Our assumption about the production of more compatible datasets is further investigated by applying various classification models and recording their behaviour over several appropriate metrics.