 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Resource Transliteration for Roman-Urdu and Urdu Using Transformer-Based Models
Mar 27, 2025
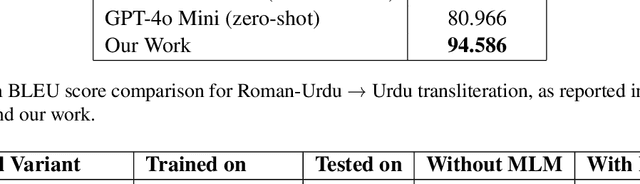
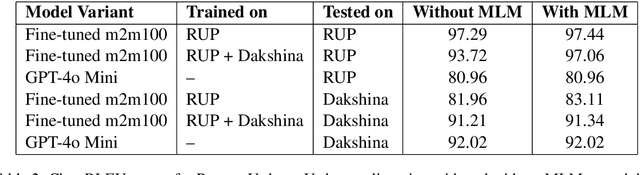
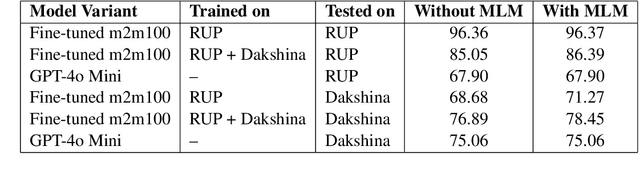
As the Information Retrieval (IR) field increasingly recognizes the importance of inclusivity, addressing the needs of low-resource languages remains a significant challenge. Transliteration between Urdu and its Romanized form, Roman Urdu, remains underexplored despite the widespread use of both scripts in South Asia. Prior work using RNNs on the Roman-Urdu-Parl dataset showed promising results but suffered from poor domain adaptability and limited evaluation. We propose a transformer-based approach using the m2m100 multilingual translation model, enhanced with masked language modeling (MLM) pretraining and fine-tuning on both Roman-Urdu-Parl and the domain-diverse Dakshina dataset. To address previous evaluation flaws, we introduce rigorous dataset splits and assess performance using BLEU, character-level BLEU, and CHRF. Our model achieves strong transliteration performance, with Char-BLEU scores of 96.37 for Urdu->Roman-Urdu and 97.44 for Roman-Urdu->Urdu. These results outperform both RNN baselines and GPT-4o Mini and demonstrate the effectiveness of multilingual transfer learning for low-resource transliteration tasks.
Enabling Low-Resource Language Retrieval: Establishing Baselines for Urdu MS MARCO
Dec 17, 2024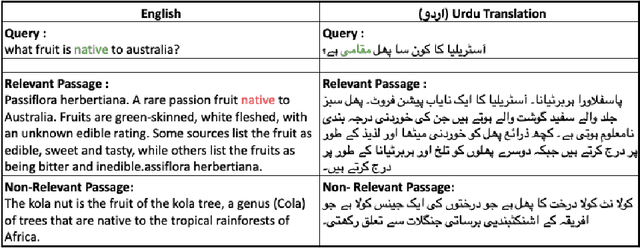
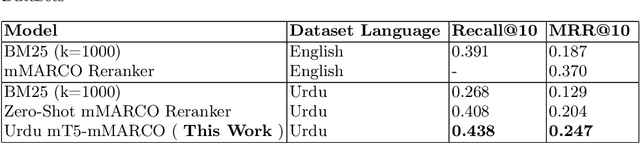
As the Information Retrieval (IR) field increasingly recognizes the importance of inclusivity, addressing the needs of low-resource languages remains a significant challenge. This paper introduces the first large-scale Urdu IR dataset, created by translating the MS MARCO dataset through machine translation. We establish baseline results through zero-shot learning for IR in Urdu and subsequently apply the mMARCO multilingual IR methodology to this newly translated dataset. Our findings demonstrate that the fine-tuned model (Urdu-mT5-mMARCO) achieves a Mean Reciprocal Rank (MRR@10) of 0.247 and a Recall@10 of 0.439, representing significant improvements over zero-shot results and showing the potential for expanding IR access for Urdu speakers. By bridging access gaps for speakers of low-resource languages, this work not only advances multilingual IR research but also emphasizes the ethical and societal importance of inclusive IR technologies. This work provides valuable insights into the challenges and solutions for improving language representation and lays the groundwork for future research, especially in South Asian languages, which can benefit from the adaptable methods used in this study.