 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Low-Resource Language Retrieval: Establishing Baselines for Urdu MS MARCO
Paper and Code
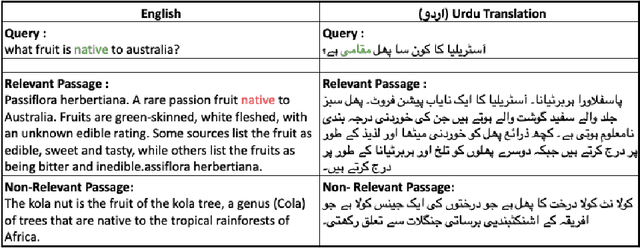
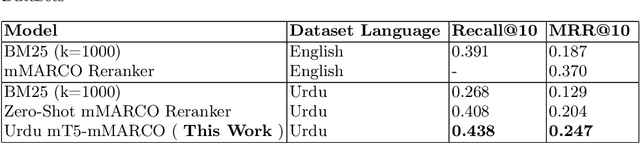
As the Information Retrieval (IR) field increasingly recognizes the importance of inclusivity, addressing the needs of low-resource languages remains a significant challenge. This paper introduces the first large-scale Urdu IR dataset, created by translating the MS MARCO dataset through machine translation. We establish baseline results through zero-shot learning for IR in Urdu and subsequently apply the mMARCO multilingual IR methodology to this newly translated dataset. Our findings demonstrate that the fine-tuned model (Urdu-mT5-mMARCO) achieves a Mean Reciprocal Rank (MRR@10) of 0.247 and a Recall@10 of 0.439, representing significant improvements over zero-shot results and showing the potential for expanding IR access for Urdu speakers. By bridging access gaps for speakers of low-resource languages, this work not only advances multilingual IR research but also emphasizes the ethical and societal importance of inclusive IR technologies. This work provides valuable insights into the challenges and solutions for improving language representation and lays the groundwork for future research, especially in South Asian languages, which can benefit from the adaptable methods used in this study.