 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepFix: A Fully Convolutional Neural Network for predicting Human Eye Fixations
Oct 10, 2015


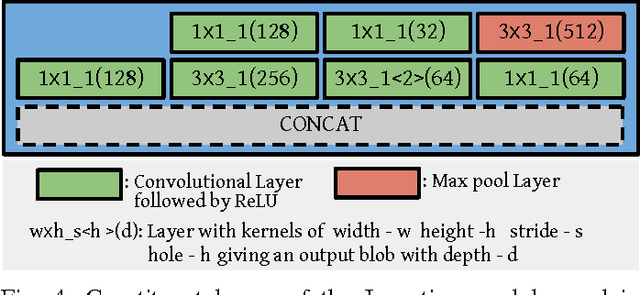
Understanding and predicting the human visual attentional mechanism is an active area of research in the fields of neuroscience and computer vision. In this work, we propose DeepFix, a first-of-its-kind fully convolutional neural network for accurate saliency prediction. Unlike classical works which characterize the saliency map using various hand-crafted features, our model automatically learns features in a hierarchical fashion and predicts saliency map in an end-to-end manner. DeepFix is designed to capture semantics at multiple scales while taking global context into account using network layers with very large receptive fields. Generally, fully convolutional nets are spatially invariant which prevents them from modeling location dependent patterns (e.g. centre-bias). Our network overcomes this limitation by incorporating a novel Location Biased Convolutional layer. We evaluate our model on two challenging eye fixation datasets -- MIT300, CAT2000 and show that it outperforms other recent approaches by a significant margin.
Crowd Flow Segmentation in Compressed Domain using CRF
Jun 19, 2015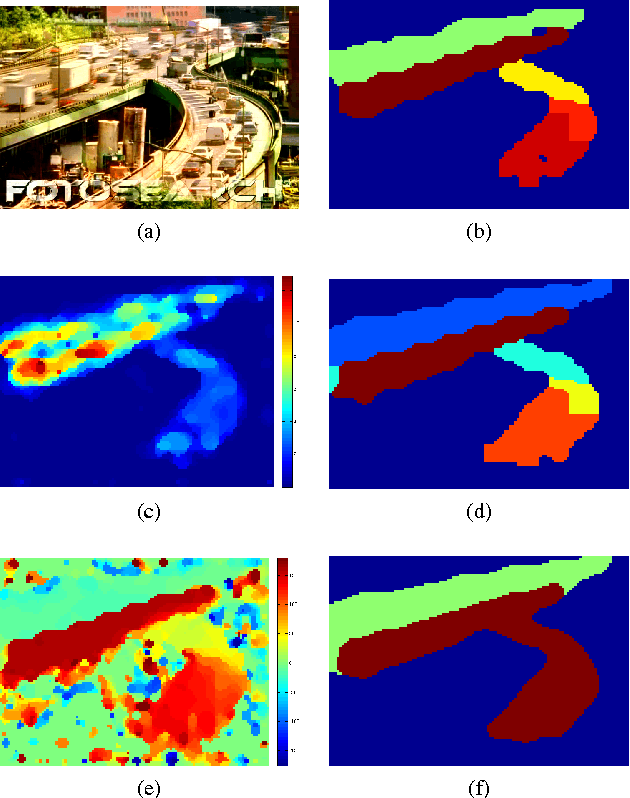



Crowd flow segmentation is an important step in many video surveillance tasks. In this work, we propose an algorithm for segmenting flows in H.264 compressed videos in a completely unsupervised manner. Our algorithm works on motion vectors which can be obtained by partially decoding the compressed video without extracting any additional features. Our approach is based on modelling the motion vector field as a Conditional Random Field (CRF) and obtaining oriented motion segments by finding the optimal labelling which minimises the global energy of CRF. These oriented motion segments are recursively merged based on gradient across their boundaries to obtain the final flow segments. This work in compressed domain can be easily extended to pixel domain by substituting motion vectors with motion based features like optical flow. The proposed algorithm is experimentally evaluated on a standard crowd flow dataset and its superior performance in both accuracy and computational time are demonstrated through quantitative results.