 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEPPC-OASIS: Ontology-Aware Adaptation and Structured Inference Refinement for Electronic Patient-Provider Communication Mining in Secure Messages
May 22, 2026Secure patient-provider messages contain clinically important communication behaviors that are difficult to characterize manually at scale. The Electronic Patient-Provider Communication (EPPC) framework provides an ontology for coding these behaviors, but automated extraction remains challenging because predictions must preserve fine-grained code/sub-code structure while grounding annotations in message text. We developed EPPC-OASIS, an ontology-aware adaptation approach for structured EPPC extraction, and combined it with deployable inference-refinement procedures designed to improve the coherence of final annotations. EPPC-OASIS augments supervised fine-tuning with a Wasserstein alignment objective that encourages alignment between model representation neighborhoods and EPPC ontology-derived neighborhoods, while inference refinement uses verification, self-consistency, hybrid correction, and selection or ensembling to address residual prediction errors. We evaluated the framework on a de-identified corpus of secure patient-provider messages against prompting, supervised fine-tuning, preference-based, and robustness-oriented baselines across multiple open-weight language models. Across model families, the best deployable pipeline achieved 77.13% Code+Sub-code F1 and 63.83% Triplet F1, corresponding to modest but consistent absolute gains of +1.39 and +2.12 F1 points over the strongest supervised fine-tuning baseline. These results suggest that ontology-aware adaptation with structured inference refinement can support scalable retrospective EPPC mining, although external validation is needed before operational use.
STaR-DRO: Stateful Tsallis Reweighting for Group-Robust Structured Prediction
Apr 09, 2026Structured prediction requires models to generate ontology-constrained labels, grounded evidence, and valid structure under ambiguity, label skew, and heterogeneous group difficulty. We present a two-part framework for controllable inference and robust fine-tuning. First, we introduce a task-agnostic prompting strategy that combines XML-based instruction structure, disambiguation rules, verification-style reasoning, schema constraints, and self-validation to address format drift, label ambiguity, evidence hallucination, and metadata-conditioned confusion in in-context structured generation. Second, we introduce STaR-DRO, a stateful robust optimization method for group heterogeneity. It combines Tsallis mirror descent with momentum-smoothed, centered group-loss signals and bounded excess-only multipliers so that only persistently hard groups above a neutral baseline are upweighted, concentrating learning where it is most needed while avoiding volatile, dense exponentiated-gradient reweighting and unnecessary loss from downweighting easier groups. We evaluate the combined framework on EPPC Miner, a benchmark for extracting hierarchical labels and evidence spans from patient-provider secure messages. Prompt engineering improves zero-shot by +15.44 average F1 across Code, Sub-code, and Span over four Llama models. Building on supervised fine-tuning, STaR-DRO further improves the hardest semantic decisions: on Llama-3.3-70B-Instruct, Code F1 rises from 79.24 to 81.47 and Sub-code F1 from 67.78 to 69.30, while preserving Span performance and reducing group-wise validation cross-entropy by up to 29.6% on the most difficult clinical categories. Because these rare and difficult groups correspond to clinically consequential communication behaviors, these gains are not merely statistical improvements: they directly strengthen communication mining reliability for patient-centered care analysis.
A Self-Supervised Learning Pipeline for Demographically Fair Facial Attribute Classification
Jul 14, 2024



Published research highlights the presence of demographic bias in automated facial attribute classification. The proposed bias mitigation techniques are mostly based on supervised learning, which requires a large amount of labeled training data for generalizability and scalability. However, labeled data is limited, requires laborious annotation, poses privacy risks, and can perpetuate human bias. In contrast, self-supervised learning (SSL) capitalizes on freely available unlabeled data, rendering trained models more scalable and generalizable. However, these label-free SSL models may also introduce biases by sampling false negative pairs, especially at low-data regimes 200K images) under low compute settings. Further, SSL-based models may suffer from performance degradation due to a lack of quality assurance of the unlabeled data sourced from the web. This paper proposes a fully self-supervised pipeline for demographically fair facial attribute classifiers. Leveraging completely unlabeled data pseudolabeled via pre-trained encoders, diverse data curation techniques, and meta-learning-based weighted contrastive learning, our method significantly outperforms existing SSL approaches proposed for downstream image classification tasks. Extensive evaluations on the FairFace and CelebA datasets demonstrate the efficacy of our pipeline in obtaining fair performance over existing baselines. Thus, setting a new benchmark for SSL in the fairness of facial attribute classification.
Deep Generative Views to Mitigate Gender Classification Bias Across Gender-Race Groups
Aug 17, 2022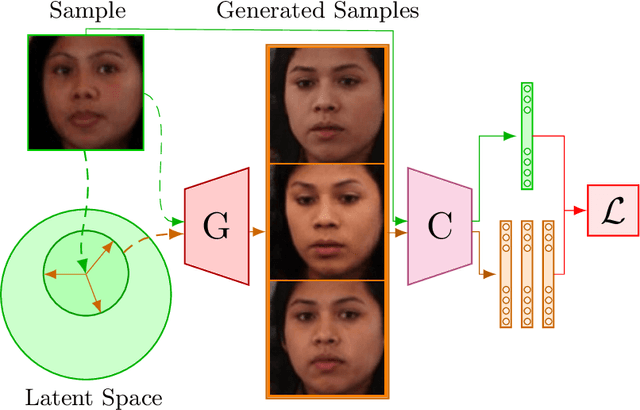



Published studies have suggested the bias of automated face-based gender classification algorithms across gender-race groups. Specifically, unequal accuracy rates were obtained for women and dark-skinned people. To mitigate the bias of gender classifiers, the vision community has developed several strategies. However, the efficacy of these mitigation strategies is demonstrated for a limited number of races mostly, Caucasian and African-American. Further, these strategies often offer a trade-off between bias and classification accuracy. To further advance the state-of-the-art, we leverage the power of generative views, structured learning, and evidential learning towards mitigating gender classification bias. We demonstrate the superiority of our bias mitigation strategy in improving classification accuracy and reducing bias across gender-racial groups through extensive experimental validation, resulting in state-of-the-art performance in intra- and cross dataset evaluations.
Harnessing Unlabeled Data to Improve Generalization of Biometric Gender and Age Classifiers
Oct 09, 2021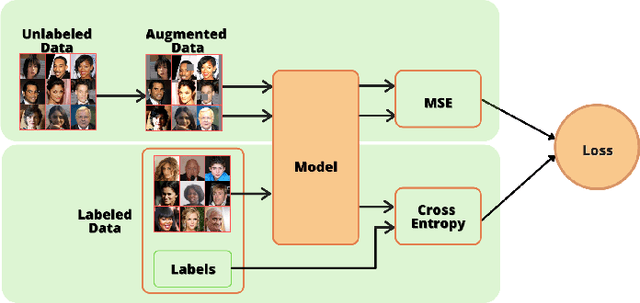
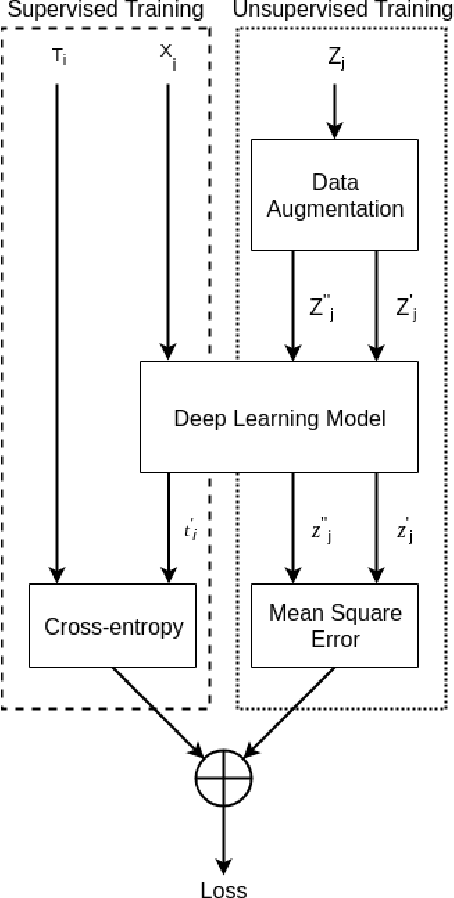


With significant advances in deep learning, many computer vision applications have reached the inflection point. However, these deep learning models need large amount of labeled data for model training and optimum parameter estimation. Limited labeled data for model training results in over-fitting and impacts their generalization performance. However, the collection and annotation of large amount of data is a very time consuming and expensive operation. Further, due to privacy and security concerns, the large amount of labeled data could not be collected for certain applications such as those involving medical field. Self-training, Co-training, and Self-ensemble methods are three types of semi-supervised learning methods that can be used to exploit unlabeled data. In this paper, we propose self-ensemble based deep learning model that along with limited labeled data, harness unlabeled data for improving the generalization performance. We evaluated the proposed self-ensemble based deep-learning model for soft-biometric gender and age classification. Experimental evaluation on CelebA and VISOB datasets suggest gender classification accuracy of 94.46% and 81.00%, respectively, using only 1000 labeled samples and remaining 199k samples as unlabeled samples for CelebA dataset and similarly,1000 labeled samples with remaining 107k samples as unlabeled samples for VISOB dataset. Comparative evaluation suggest that there is $5.74\%$ and $8.47\%$ improvement in the accuracy of the self-ensemble model when compared with supervised model trained on the entire CelebA and VISOB dataset, respectively. We also evaluated the proposed learning method for age-group prediction on Adience dataset and it outperformed the baseline supervised deep-learning learning model with a better exact accuracy of 55.55 $\pm$ 4.28 which is 3.92% more than the baseline.
An Experimental Evaluation on Deepfake Detection using Deep Face Recognition
Oct 04, 2021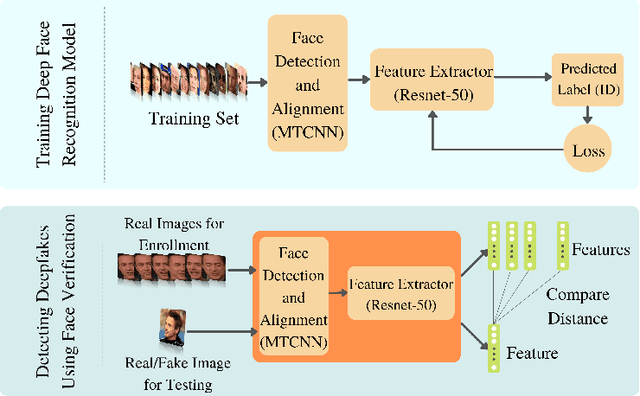
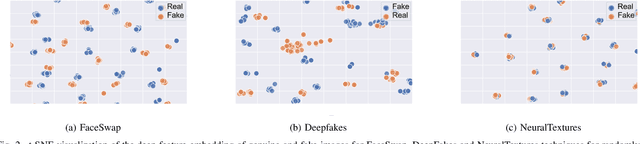
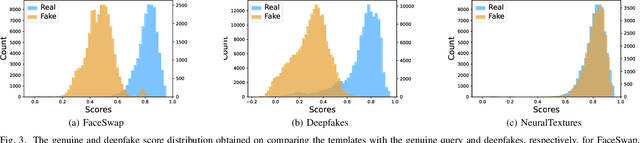
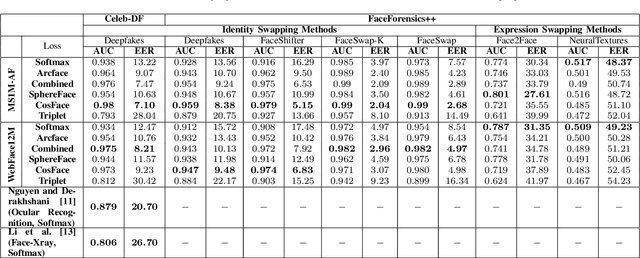
Significant advances in deep learning have obtained hallmark accuracy rates for various computer vision applications. However, advances in deep generative models have also led to the generation of very realistic fake content, also known as deepfakes, causing a threat to privacy, democracy, and national security. Most of the current deepfake detection methods are deemed as a binary classification problem in distinguishing authentic images or videos from fake ones using two-class convolutional neural networks (CNNs). These methods are based on detecting visual artifacts, temporal or color inconsistencies produced by deep generative models. However, these methods require a large amount of real and fake data for model training and their performance drops significantly in cross dataset evaluation with samples generated using advanced deepfake generation techniques. In this paper, we thoroughly evaluate the efficacy of deep face recognition in identifying deepfakes, using different loss functions and deepfake generation techniques. Experimental investigations on challenging Celeb-DF and FaceForensics++ deepfake datasets suggest the efficacy of deep face recognition in identifying deepfakes over two-class CNNs and the ocular modality. Reported results suggest a maximum Area Under Curve (AUC) of 0.98 and an Equal Error Rate (EER) of 7.1% in detecting deepfakes using face recognition on the Celeb-DF dataset. This EER is lower by 16.6% compared to the EER obtained for the two-class CNN and the ocular modality on the Celeb-DF dataset. Further on the FaceForensics++ dataset, an AUC of 0.99 and EER of 2.04% were obtained. The use of biometric facial recognition technology has the advantage of bypassing the need for a large amount of fake data for model training and obtaining better generalizability to evolving deepfake creation techniques.