 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial Media Authentication and Combating Deepfakes using Semi-fragile Invisible Image Watermarking
Oct 02, 2024With the significant advances in deep generative models for image and video synthesis, Deepfakes and manipulated media have raised severe societal concerns. Conventional machine learning classifiers for deepfake detection often fail to cope with evolving deepfake generation technology and are susceptible to adversarial attacks. Alternatively, invisible image watermarking is being researched as a proactive defense technique that allows media authentication by verifying an invisible secret message embedded in the image pixels. A handful of invisible image watermarking techniques introduced for media authentication have proven vulnerable to basic image processing operations and watermark removal attacks. In response, we have proposed a semi-fragile image watermarking technique that embeds an invisible secret message into real images for media authentication. Our proposed watermarking framework is designed to be fragile to facial manipulations or tampering while being robust to benign image-processing operations and watermark removal attacks. This is facilitated through a unique architecture of our proposed technique consisting of critic and adversarial networks that enforce high image quality and resiliency to watermark removal efforts, respectively, along with the backbone encoder-decoder and the discriminator networks. Thorough experimental investigations on SOTA facial Deepfake datasets demonstrate that our proposed model can embed a $64$-bit secret as an imperceptible image watermark that can be recovered with a high-bit recovery accuracy when benign image processing operations are applied while being non-recoverable when unseen Deepfake manipulations are applied. In addition, our proposed watermarking technique demonstrates high resilience to several white-box and black-box watermark removal attacks. Thus, obtaining state-of-the-art performance.
Facial Forgery-based Deepfake Detection using Fine-Grained Features
Oct 10, 2023

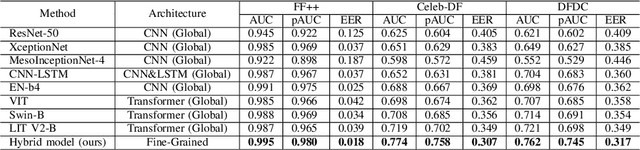

Facial forgery by deepfakes has caused major security risks and raised severe societal concerns. As a countermeasure, a number of deepfake detection methods have been proposed. Most of them model deepfake detection as a binary classification problem using a backbone convolutional neural network (CNN) architecture pretrained for the task. These CNN-based methods have demonstrated very high efficacy in deepfake detection with the Area under the Curve (AUC) as high as $0.99$. However, the performance of these methods degrades significantly when evaluated across datasets and deepfake manipulation techniques. This draws our attention towards learning more subtle, local, and discriminative features for deepfake detection. In this paper, we formulate deepfake detection as a fine-grained classification problem and propose a new fine-grained solution to it. Specifically, our method is based on learning subtle and generalizable features by effectively suppressing background noise and learning discriminative features at various scales for deepfake detection. Through extensive experimental validation, we demonstrate the superiority of our method over the published research in cross-dataset and cross-manipulation generalization of deepfake detectors for the majority of the experimental scenarios.
GBDF: Gender Balanced DeepFake Dataset Towards Fair DeepFake Detection
Jul 21, 2022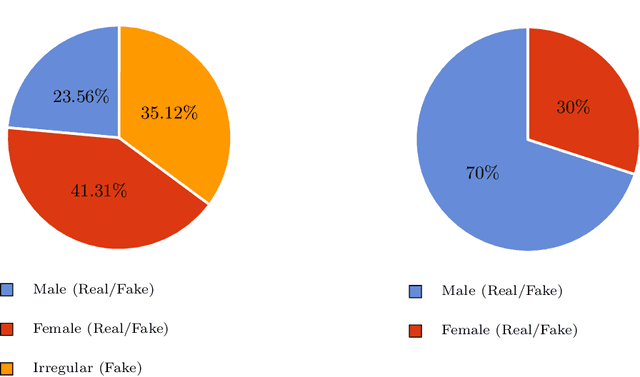
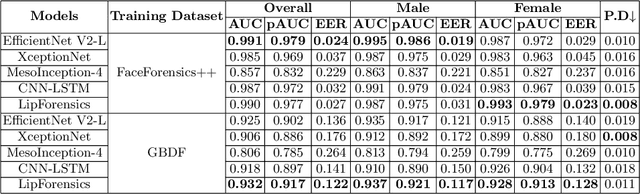
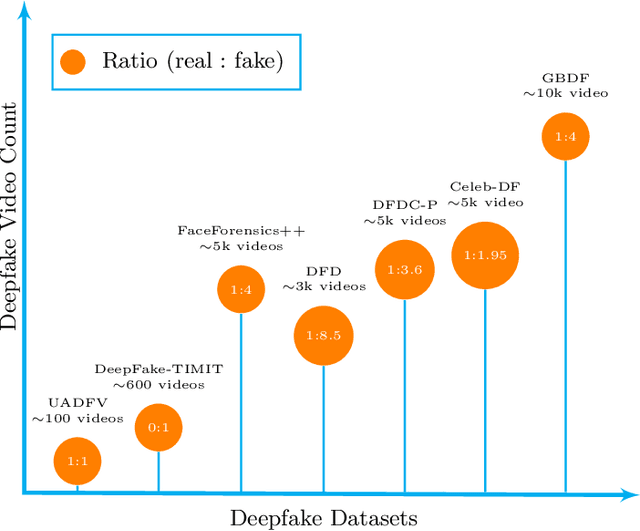
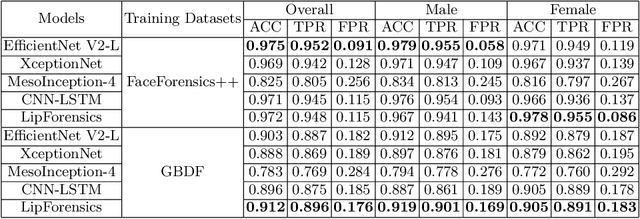
Facial forgery by deepfakes has raised severe societal concerns. Several solutions have been proposed by the vision community to effectively combat the misinformation on the internet via automated deepfake detection systems. Recent studies have demonstrated that facial analysis-based deep learning models can discriminate based on protected attributes. For the commercial adoption and massive roll-out of the deepfake detection technology, it is vital to evaluate and understand the fairness (the absence of any prejudice or favoritism) of deepfake detectors across demographic variations such as gender and race. As the performance differential of deepfake detectors between demographic subgroups would impact millions of people of the deprived sub-group. This paper aims to evaluate the fairness of the deepfake detectors across males and females. However, existing deepfake datasets are not annotated with demographic labels to facilitate fairness analysis. To this aim, we manually annotated existing popular deepfake datasets with gender labels and evaluated the performance differential of current deepfake detectors across gender. Our analysis on the gender-labeled version of the datasets suggests (a) current deepfake datasets have skewed distribution across gender, and (b) commonly adopted deepfake detectors obtain unequal performance across gender with mostly males outperforming females. Finally, we contributed a gender-balanced and annotated deepfake dataset, GBDF, to mitigate the performance differential and to promote research and development towards fairness-aware deep fake detectors. The GBDF dataset is publicly available at: https://github.com/aakash4305/GBDF
On Improving Cross-dataset Generalization of Deepfake Detectors
Apr 08, 2022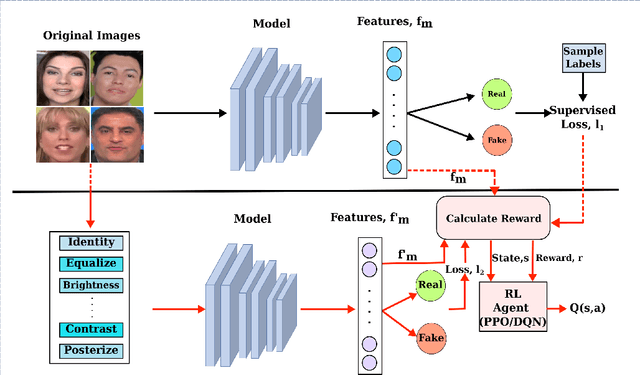
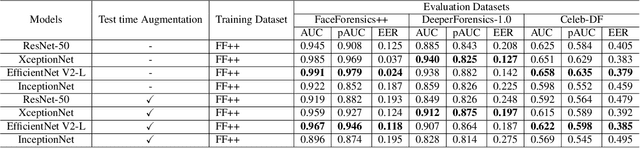
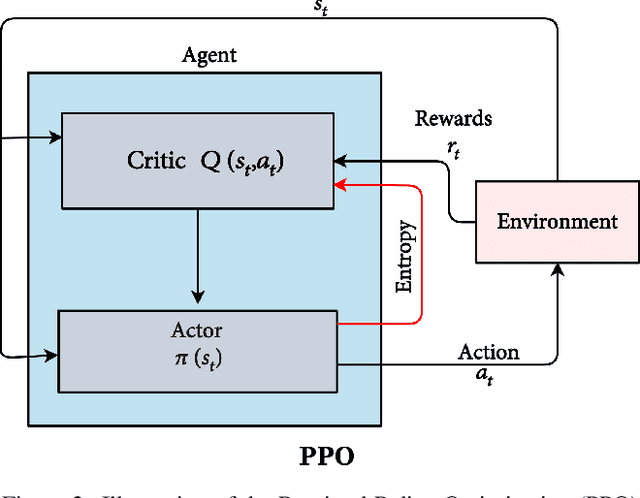
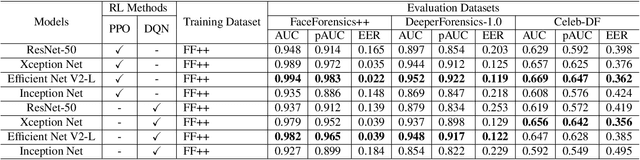
Facial manipulation by deep fake has caused major security risks and raised severe societal concerns. As a countermeasure, a number of deep fake detection methods have been proposed recently. Most of them model deep fake detection as a binary classification problem using a backbone convolutional neural network (CNN) architecture pretrained for the task. These CNN-based methods have demonstrated very high efficacy in deep fake detection with the Area under the Curve (AUC) as high as 0.99. However, the performance of these methods degrades significantly when evaluated across datasets. In this paper, we formulate deep fake detection as a hybrid combination of supervised and reinforcement learning (RL) to improve its cross-dataset generalization performance. The proposed method chooses the top-k augmentations for each test sample by an RL agent in an image-specific manner. The classification scores, obtained using CNN, of all the augmentations of each test image are averaged together for final real or fake classification. Through extensive experimental validation, we demonstrate the superiority of our method over existing published research in cross-dataset generalization of deep fake detectors, thus obtaining state-of-the-art performance.
Harnessing Unlabeled Data to Improve Generalization of Biometric Gender and Age Classifiers
Oct 09, 2021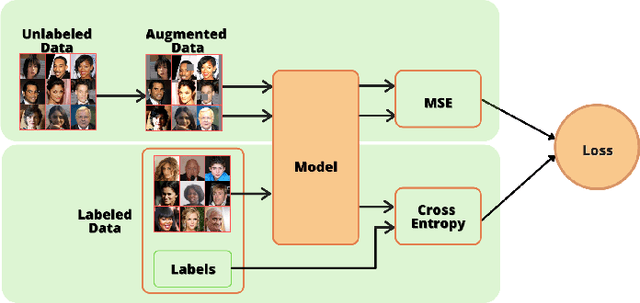
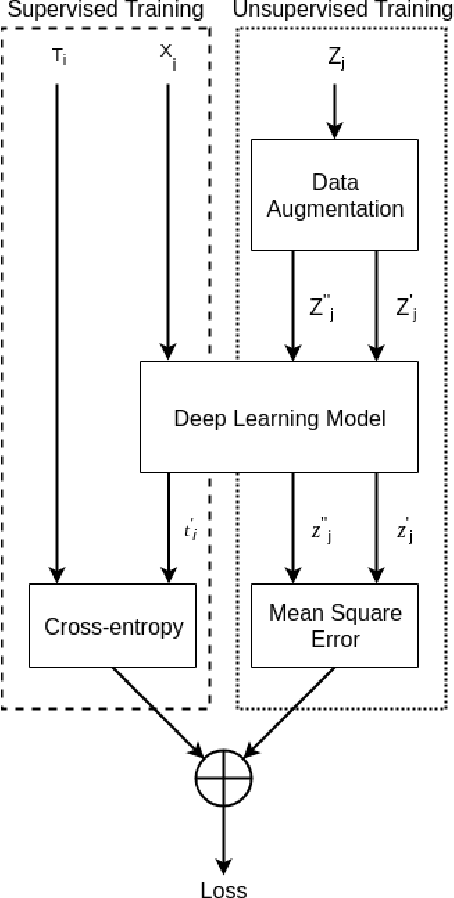


With significant advances in deep learning, many computer vision applications have reached the inflection point. However, these deep learning models need large amount of labeled data for model training and optimum parameter estimation. Limited labeled data for model training results in over-fitting and impacts their generalization performance. However, the collection and annotation of large amount of data is a very time consuming and expensive operation. Further, due to privacy and security concerns, the large amount of labeled data could not be collected for certain applications such as those involving medical field. Self-training, Co-training, and Self-ensemble methods are three types of semi-supervised learning methods that can be used to exploit unlabeled data. In this paper, we propose self-ensemble based deep learning model that along with limited labeled data, harness unlabeled data for improving the generalization performance. We evaluated the proposed self-ensemble based deep-learning model for soft-biometric gender and age classification. Experimental evaluation on CelebA and VISOB datasets suggest gender classification accuracy of 94.46% and 81.00%, respectively, using only 1000 labeled samples and remaining 199k samples as unlabeled samples for CelebA dataset and similarly,1000 labeled samples with remaining 107k samples as unlabeled samples for VISOB dataset. Comparative evaluation suggest that there is $5.74\%$ and $8.47\%$ improvement in the accuracy of the self-ensemble model when compared with supervised model trained on the entire CelebA and VISOB dataset, respectively. We also evaluated the proposed learning method for age-group prediction on Adience dataset and it outperformed the baseline supervised deep-learning learning model with a better exact accuracy of 55.55 $\pm$ 4.28 which is 3.92% more than the baseline.
An Experimental Evaluation on Deepfake Detection using Deep Face Recognition
Oct 04, 2021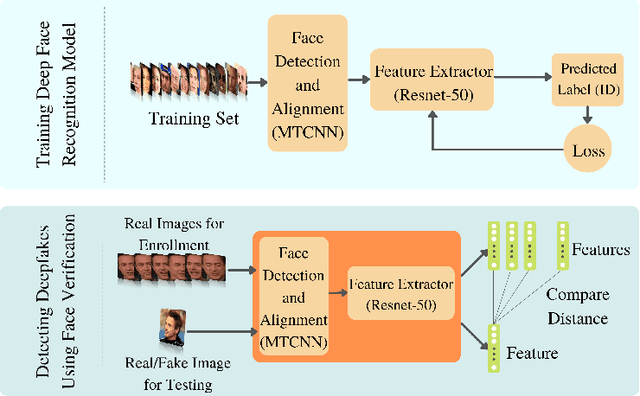
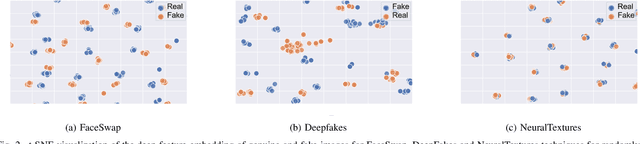
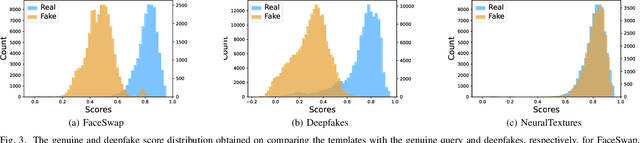
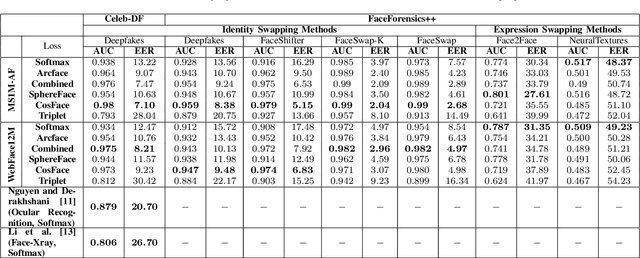
Significant advances in deep learning have obtained hallmark accuracy rates for various computer vision applications. However, advances in deep generative models have also led to the generation of very realistic fake content, also known as deepfakes, causing a threat to privacy, democracy, and national security. Most of the current deepfake detection methods are deemed as a binary classification problem in distinguishing authentic images or videos from fake ones using two-class convolutional neural networks (CNNs). These methods are based on detecting visual artifacts, temporal or color inconsistencies produced by deep generative models. However, these methods require a large amount of real and fake data for model training and their performance drops significantly in cross dataset evaluation with samples generated using advanced deepfake generation techniques. In this paper, we thoroughly evaluate the efficacy of deep face recognition in identifying deepfakes, using different loss functions and deepfake generation techniques. Experimental investigations on challenging Celeb-DF and FaceForensics++ deepfake datasets suggest the efficacy of deep face recognition in identifying deepfakes over two-class CNNs and the ocular modality. Reported results suggest a maximum Area Under Curve (AUC) of 0.98 and an Equal Error Rate (EER) of 7.1% in detecting deepfakes using face recognition on the Celeb-DF dataset. This EER is lower by 16.6% compared to the EER obtained for the two-class CNN and the ocular modality on the Celeb-DF dataset. Further on the FaceForensics++ dataset, an AUC of 0.99 and EER of 2.04% were obtained. The use of biometric facial recognition technology has the advantage of bypassing the need for a large amount of fake data for model training and obtaining better generalizability to evolving deepfake creation techniques.