 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible Heteroscedastic Count Regression with Deep Double Poisson Networks
Jun 13, 2024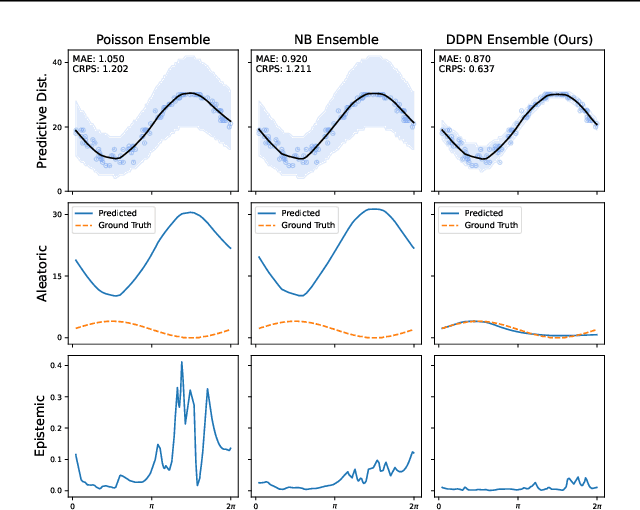

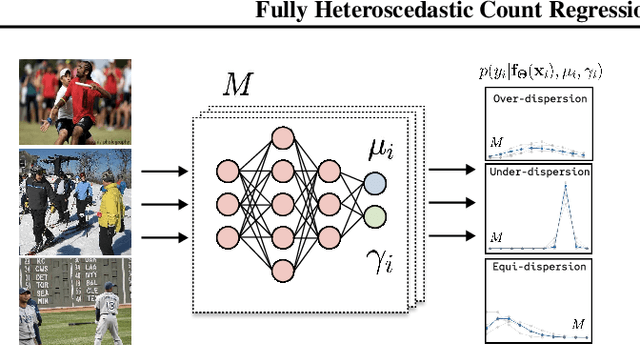

Neural networks that can produce accurate, input-conditional uncertainty representations are critical for real-world applications. Recent progress on heteroscedastic continuous regression has shown great promise for calibrated uncertainty quantification on complex tasks, like image regression. However, when these methods are applied to discrete regression tasks, such as crowd counting, ratings prediction, or inventory estimation, they tend to produce predictive distributions with numerous pathologies. We propose to address these issues by training a neural network to output the parameters of a Double Poisson distribution, which we call the Deep Double Poisson Network (DDPN). In contrast to existing methods that are trained to minimize Gaussian negative log likelihood (NLL), DDPNs produce a proper probability mass function over discrete output. Additionally, DDPNs naturally model under-, over-, and equi-dispersion, unlike networks trained with the more rigid Poisson and Negative Binomial parameterizations. We show DDPNs 1) vastly outperform existing discrete models; 2) meet or exceed the accuracy and flexibility of networks trained with Gaussian NLL; 3) produce proper predictive distributions over discrete counts; and 4) exhibit superior out-of-distribution detection. DDPNs can easily be applied to a variety of count regression datasets including tabular, image, point cloud, and text data.
On Measuring Calibration of Discrete Probabilistic Neural Networks
May 20, 2024



As machine learning systems become increasingly integrated into real-world applications, accurately representing uncertainty is crucial for enhancing their safety, robustness, and reliability. Training neural networks to fit high-dimensional probability distributions via maximum likelihood has become an effective method for uncertainty quantification. However, such models often exhibit poor calibration, leading to overconfident predictions. Traditional metrics like Expected Calibration Error (ECE) and Negative Log Likelihood (NLL) have limitations, including biases and parametric assumptions. This paper proposes a new approach using conditional kernel mean embeddings to measure calibration discrepancies without these biases and assumptions. Preliminary experiments on synthetic data demonstrate the method's potential, with future work planned for more complex applications.