 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroducing Partial Matching Approach in Association Rules for Better Treatment of Missing Values
Apr 21, 2009



Handling missing values in training datasets for constructing learning models or extracting useful information is considered to be an important research task in data mining and knowledge discovery in databases. In recent years, lot of techniques are proposed for imputing missing values by considering attribute relationships with missing value observation and other observations of training dataset. The main deficiency of such techniques is that, they depend upon single approach and do not combine multiple approaches, that why they are less accurate. To improve the accuracy of missing values imputation, in this paper we introduce a novel partial matching concept in association rules mining, which shows better results as compared to full matching concept that we described in our previous work. Our imputation technique combines the partial matching concept in association rules with k-nearest neighbor approach. Since this is a hybrid technique, therefore its accuracy is much better than as compared to those techniques which depend upon single approach. To check the efficiency of our technique, we also provide detail experimental results on number of benchmark datasets which show better results as compared to previous approaches.
Using Association Rules for Better Treatment of Missing Values
Apr 21, 2009
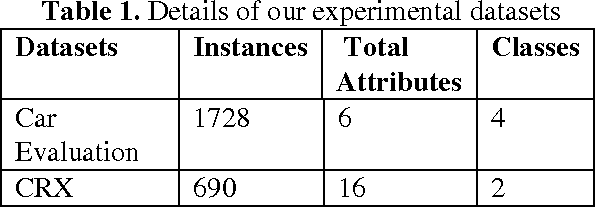


The quality of training data for knowledge discovery in databases (KDD) and data mining depends upon many factors, but handling missing values is considered to be a crucial factor in overall data quality. Today real world datasets contains missing values due to human, operational error, hardware malfunctioning and many other factors. The quality of knowledge extracted, learning and decision problems depend directly upon the quality of training data. By considering the importance of handling missing values in KDD and data mining tasks, in this paper we propose a novel Hybrid Missing values Imputation Technique (HMiT) using association rules mining and hybrid combination of k-nearest neighbor approach. To check the effectiveness of our HMiT missing values imputation technique, we also perform detail experimental results on real world datasets. Our results suggest that the HMiT technique is not only better in term of accuracy but it also take less processing time as compared to current best missing values imputation technique based on k-nearest neighbor approach, which shows the effectiveness of our missing values imputation technique.