 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Association Rules for Better Treatment of Missing Values
Paper and Code
Apr 21, 2009
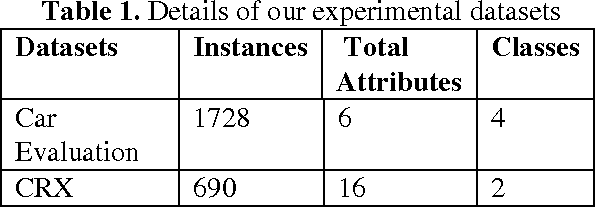


The quality of training data for knowledge discovery in databases (KDD) and data mining depends upon many factors, but handling missing values is considered to be a crucial factor in overall data quality. Today real world datasets contains missing values due to human, operational error, hardware malfunctioning and many other factors. The quality of knowledge extracted, learning and decision problems depend directly upon the quality of training data. By considering the importance of handling missing values in KDD and data mining tasks, in this paper we propose a novel Hybrid Missing values Imputation Technique (HMiT) using association rules mining and hybrid combination of k-nearest neighbor approach. To check the effectiveness of our HMiT missing values imputation technique, we also perform detail experimental results on real world datasets. Our results suggest that the HMiT technique is not only better in term of accuracy but it also take less processing time as compared to current best missing values imputation technique based on k-nearest neighbor approach, which shows the effectiveness of our missing values imputation technique.