Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCAT: Second Chance Autoencoder for Textual Data
May 11, 2020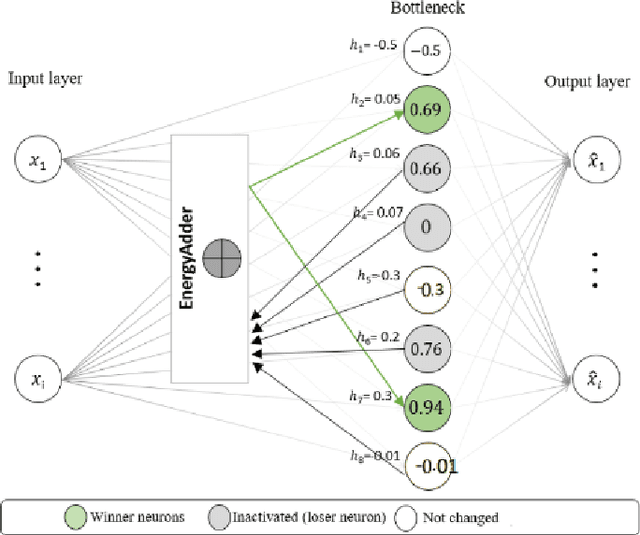
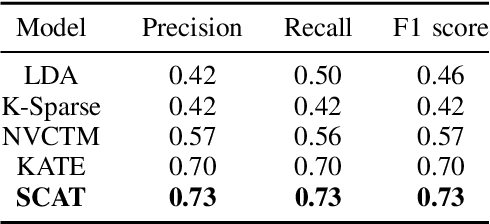
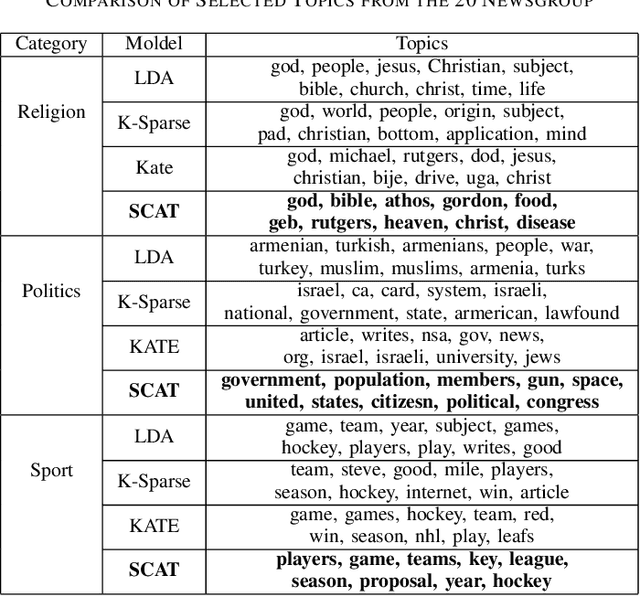
We present a k-competitive learning approach for textual autoencoders named Second Chance Autoencoder (SCAT). SCAT selects the $k$ largest and smallest positive activations as the winner neurons, which gain the activation values of the loser neurons during the learning process, and thus focus on retrieving well-representative features for topics. Our experiments show that SCAT achieves outstanding performance in classification, topic modeling, and document visualization compared to LDA, K-Sparse, NVCTM, and KATE.
Via