 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Driving Behavior Analysis using Representation Learning and Exploiting Group-based Training
May 12, 2022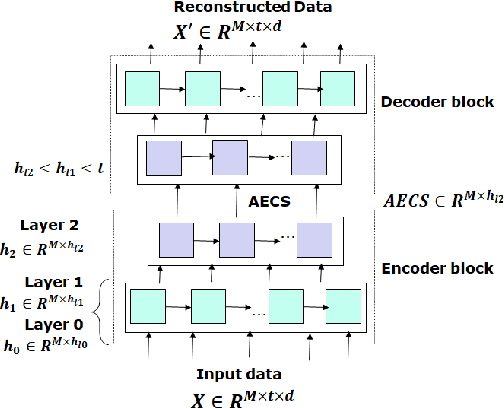


Driving behavior monitoring plays a crucial role in managing road safety and decreasing the risk of traffic accidents. Driving behavior is affected by multiple factors like vehicle characteristics, types of roads, traffic, but, most importantly, the pattern of driving of individuals. Current work performs a robust driving pattern analysis by capturing variations in driving patterns. It forms consistent groups by learning compressed representation of time series (Auto Encoded Compact Sequence) using a multi-layer seq-2-seq autoencoder and exploiting hierarchical clustering along with recommending the choice of best distance measure. Consistent groups aid in identifying variations in driving patterns of individuals captured in the dataset. These groups are generated for both train and hidden test data. The consistent groups formed using train data, are exploited for training multiple instances of the classifier. Obtained choice of best distance measure is used to select the best train-test pair of consistent groups. We have experimented on the publicly available UAH-DriveSet dataset considering the signals captured from IMU sensors (accelerometer and gyroscope) for classifying driving behavior. We observe proposed method, significantly outperforms the benchmark performance.
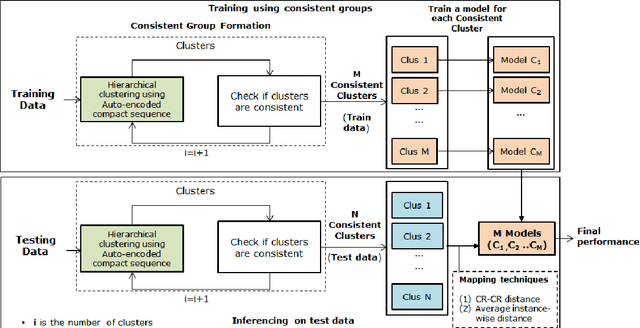
Automated Label Generation for Time Series Classification with Representation Learning: Reduction of Label Cost for Training
Jul 12, 2021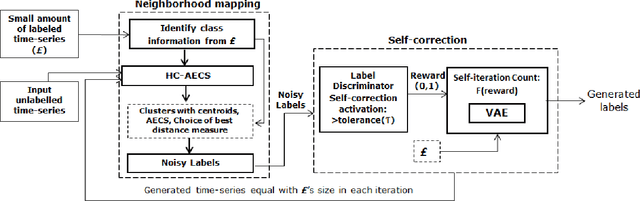
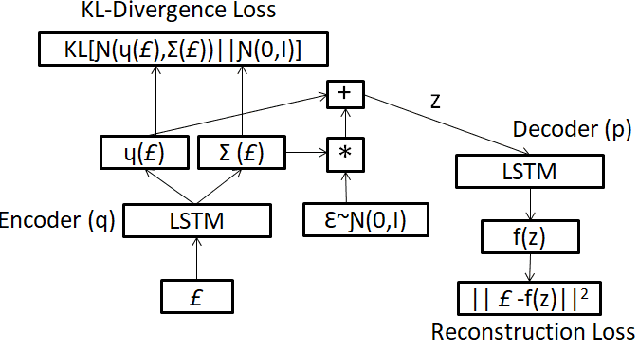
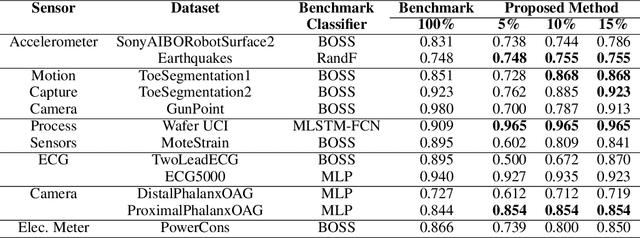
Time-series generated by end-users, edge devices, and different wearables are mostly unlabelled. We propose a method to auto-generate labels of un-labelled time-series, exploiting very few representative labelled time-series. Our method is based on representation learning using Auto Encoded Compact Sequence (AECS) with a choice of best distance measure. It performs self-correction in iterations, by learning latent structure, as well as synthetically boosting representative time-series using Variational-Auto-Encoder (VAE) to improve the quality of labels. We have experimented with UCR and UCI archives, public real-world univariate, multivariate time-series taken from different application domains. Experimental results demonstrate that the proposed method is very close to the performance achieved by fully supervised classification. The proposed method not only produces close to benchmark results but outperforms the benchmark performance in some cases.
Hierarchical Clustering using Auto-encoded Compact Representation for Time-series Analysis
Jan 11, 2021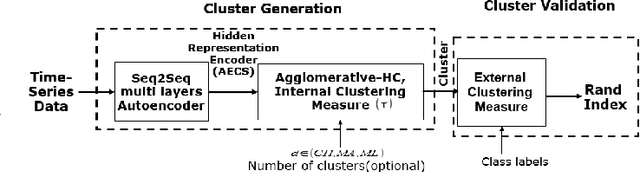
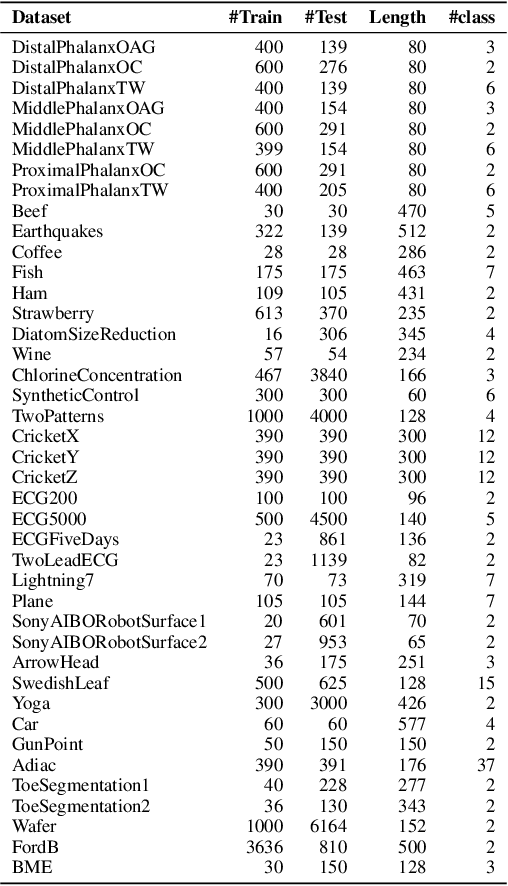
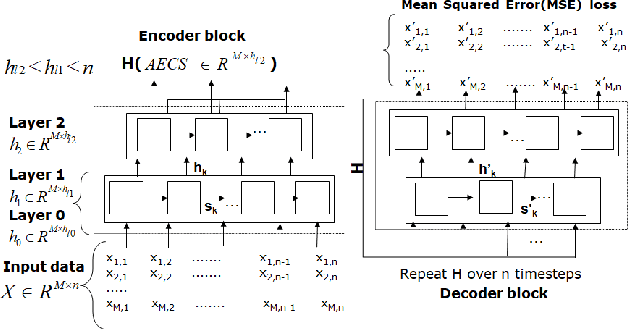
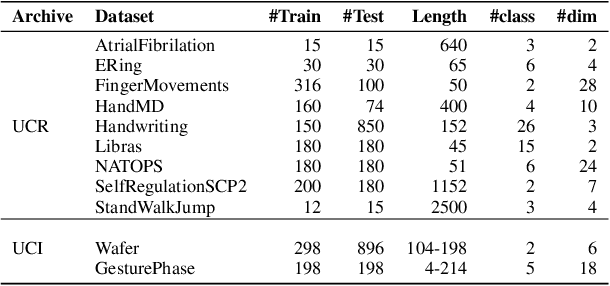
Getting a robust time-series clustering with best choice of distance measure and appropriate representation is always a challenge. We propose a novel mechanism to identify the clusters combining learned compact representation of time-series, Auto Encoded Compact Sequence (AECS) and hierarchical clustering approach. Proposed algorithm aims to address the large computing time issue of hierarchical clustering as learned latent representation AECS has a length much less than the original length of time-series and at the same time want to enhance its performance.Our algorithm exploits Recurrent Neural Network (RNN) based under complete Sequence to Sequence(seq2seq) autoencoder and agglomerative hierarchical clustering with a choice of best distance measure to recommend the best clustering. Our scheme selects the best distance measure and corresponding clustering for both univariate and multivariate time-series. We have experimented with real-world time-series from UCR and UCI archive taken from diverse application domains like health, smart-city, manufacturing etc. Experimental results show that proposed method not only produce close to benchmark results but also in some cases outperform the benchmark.
Murmur Detection Using Parallel Recurrent & Convolutional Neural Networks
Aug 13, 2018
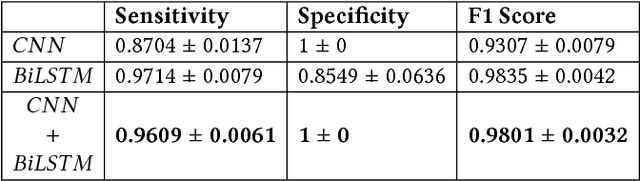
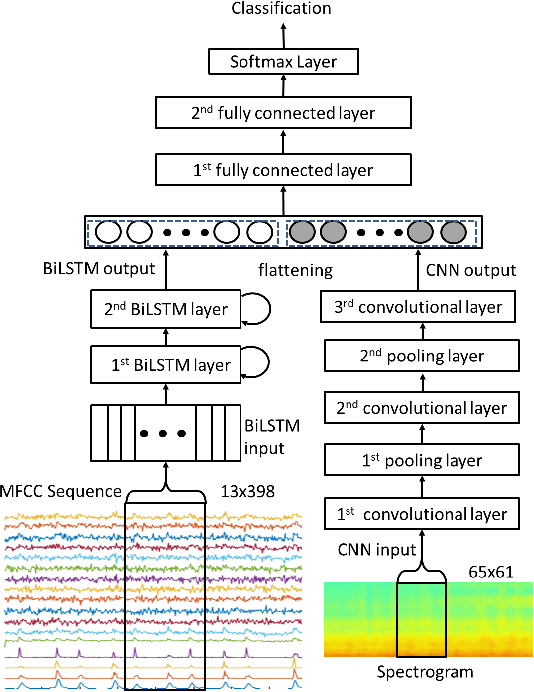
In this article, we propose a novel technique for classification of the Murmurs in heart sound. We introduce a novel deep neural network architecture using parallel combination of the Recurrent Neural Network (RNN) based Bidirectional Long Short-Term Memory (BiLSTM) & Convolutional Neural Network (CNN) to learn visual and time-dependent characteristics of Murmur in PCG waveform. Set of acoustic features are presented to our proposed deep neural network to discriminate between Normal and Murmur class. The proposed method was evaluated on a large dataset using 5-fold cross-validation, resulting in a sensitivity and specificity of 96 +- 0.6 % , 100 +- 0 % respectively and F1 Score of 98 +- 0.3 %.