 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Sparse Circuit Extraction from Billion-Parameter Language Models through Scalable Attribution Graph Decomposition
Jan 19, 2026Mechanistic interpretability seeks to reverse-engineer neural network computations into human-understandable algorithms, yet extracting sparse computational circuits from billion-parameter language models remains challenging due to exponential search complexity and pervasive polysemanticity. The proposed Hierarchical Attribution Graph Decomposition (HAGD) framework reduces circuit discovery complexity from O(2^n) exhaustive enumeration to O(n^2 log n) through multi-resolution abstraction hierarchies and differentiable circuit search. The methodology integrates cross-layer transcoders for monosemantic feature extraction, graph neural network meta-learning for topology prediction, and causal intervention protocols for validation. Empirical evaluation spans GPT-2 variants, Llama-7B through Llama-70B, and Pythia suite models across algorithmic tasks and natural language benchmarks. On modular arithmetic tasks, the framework achieves up to 91% behavioral preservation ($\pm$2.3\% across runs) while maintaining interpretable subgraph sizes. Cross-architecture transfer experiments suggest that discovered circuits exhibit moderate structural similarity (averaging 67%) across model families, indicating potential shared computational patterns. These results provide preliminary foundations for interpretability at larger model scales while identifying significant limitations in current attribution methodologies that require future advances.
Constraint-Aware Neurosymbolic Uncertainty Quantification with Bayesian Deep Learning for Scientific Discovery
Jan 18, 2026Scientific Artificial Intelligence (AI) applications require models that deliver trustworthy uncertainty estimates while respecting domain constraints. Existing uncertainty quantification methods lack mechanisms to incorporate symbolic scientific knowledge, while neurosymbolic approaches operate deterministically without principled uncertainty modeling. We introduce the Constraint-Aware Neurosymbolic Uncertainty Framework (CANUF), unifying Bayesian deep learning with differentiable symbolic reasoning. The architecture comprises three components: automated constraint extraction from scientific literature, probabilistic neural backbone with variational inference, and differentiable constraint satisfaction layer ensuring physical consistency. Experiments on Materials Project (140,000+ materials), QM9 molecular properties, and climate benchmarks show CANUF reduces Expected Calibration Error by 34.7% versus Bayesian neural networks while maintaining 99.2% constraint satisfaction. Ablations reveal constraint-guided recalibration contributes 18.3% performance gain, with constraint extraction achieving 91.4% precision. CANUF provides the first end-to-end differentiable pipeline simultaneously addressing uncertainty quantification, constraint satisfaction, and interpretable explanations for scientific predictions.
DriftGuard: A Hierarchical Framework for Concept Drift Detection and Remediation in Supply Chain Forecasting
Jan 13, 2026Supply chain forecasting models degrade over time as real-world conditions change. Promotions shift, consumer preferences evolve, and supply disruptions alter demand patterns, causing what is known as concept drift. This silent degradation leads to stockouts or excess inventory without triggering any system warnings. Current industry practice relies on manual monitoring and scheduled retraining every 3-6 months, which wastes computational resources during stable periods while missing rapid drift events. Existing academic methods focus narrowly on drift detection without addressing diagnosis or remediation, and they ignore the hierarchical structure inherent in supply chain data. What retailers need is an end-to-end system that detects drift early, explains its root causes, and automatically corrects affected models. We propose DriftGuard, a five-module framework that addresses the complete drift lifecycle. The system combines an ensemble of four complementary detection methods, namely error-based monitoring, statistical tests, autoencoder anomaly detection, and Cumulative Sum (CUSUM) change-point analysis, with hierarchical propagation analysis to identify exactly where drift occurs across product lines. Once detected, Shapley Additive Explanations (SHAP) analysis diagnoses the root causes, and a cost-aware retraining strategy selectively updates only the most affected models. Evaluated on over 30,000 time series from the M5 retail dataset, DriftGuard achieves 97.8% detection recall within 4.2 days and delivers up to 417 return on investment through targeted remediation.
SecureCAI: Injection-Resilient LLM Assistants for Cybersecurity Operations
Jan 12, 2026Large Language Models have emerged as transformative tools for Security Operations Centers, enabling automated log analysis, phishing triage, and malware explanation; however, deployment in adversarial cybersecurity environments exposes critical vulnerabilities to prompt injection attacks where malicious instructions embedded in security artifacts manipulate model behavior. This paper introduces SecureCAI, a novel defense framework extending Constitutional AI principles with security-aware guardrails, adaptive constitution evolution, and Direct Preference Optimization for unlearning unsafe response patterns, addressing the unique challenges of high-stakes security contexts where traditional safety mechanisms prove insufficient against sophisticated adversarial manipulation. Experimental evaluation demonstrates that SecureCAI reduces attack success rates by 94.7% compared to baseline models while maintaining 95.1% accuracy on benign security analysis tasks, with the framework incorporating continuous red-teaming feedback loops enabling dynamic adaptation to emerging attack strategies and achieving constitution adherence scores exceeding 0.92 under sustained adversarial pressure, thereby establishing a foundation for trustworthy integration of language model capabilities into operational cybersecurity workflows and addressing a critical gap in current approaches to AI safety within adversarial domains.
Cutting AI Research Costs: How Task-Aware Compression Makes Large Language Model Agents Affordable
Jan 08, 2026When researchers deploy large language models for autonomous tasks like reviewing literature or generating hypotheses, the computational bills add up quickly. A single research session using a 70-billion parameter model can cost around $127 in cloud fees, putting these tools out of reach for many academic labs. We developed AgentCompress to tackle this problem head-on. The core idea came from a simple observation during our own work: writing a novel hypothesis clearly demands more from the model than reformatting a bibliography. Why should both tasks run at full precision? Our system uses a small neural network to gauge how hard each incoming task will be, based only on its opening words, then routes it to a suitably compressed model variant. The decision happens in under a millisecond. Testing across 500 research workflows in four scientific fields, we cut compute costs by 68.3% while keeping 96.2% of the original success rate. For labs watching their budgets, this could mean the difference between running experiments and sitting on the sidelines
Meta-Learning Guided Pruning for Few-Shot Plant Pathology on Edge Devices
Jan 05, 2026Farmers in remote areas need quick and reliable methods for identifying plant diseases, yet they often lack access to laboratories or high-performance computing resources. Deep learning models can detect diseases from leaf images with high accuracy, but these models are typically too large and computationally expensive to run on low-cost edge devices such as Raspberry Pi. Furthermore, collecting thousands of labeled disease images for training is both expensive and time-consuming. This paper addresses both challenges by combining neural network pruning -- removing unnecessary parts of the model -- with few-shot learning, which enables the model to learn from limited examples. This paper proposes Disease-Aware Channel Importance Scoring (DACIS), a method that identifies which parts of the neural network are most important for distinguishing between different plant diseases, integrated into a three-stage Prune-then-Meta-Learn-then-Prune (PMP) pipeline. Experiments on PlantVillage and PlantDoc datasets demonstrate that the proposed approach reduces model size by 78\% while maintaining 92.3\% of the original accuracy, with the compressed model running at 7 frames per second on a Raspberry Pi 4, making real-time field diagnosis practical for smallholder farmers.
Cost-effective Deep Learning Infrastructure with NVIDIA GPU
Mar 14, 2025The growing demand for computational power is driven by advancements in deep learning, the increasing need for big data processing, and the requirements of scientific simulations for academic and research purposes. Developing countries like Nepal often struggle with the resources needed to invest in new and better hardware for these purposes. However, optimizing and building on existing technology can still meet these computing demands effectively. To address these needs, we built a cluster using four NVIDIA GeForce GTX 1650 GPUs. The cluster consists of four nodes: one master node that controls and manages the entire cluster, and three compute nodes dedicated to processing tasks. The master node is equipped with all necessary software for package management, resource scheduling, and deployment, such as Anaconda and Slurm. In addition, a Network File Storage (NFS) system was integrated to provide the additional storage required by the cluster. Given that the cluster is accessible via ssh by a public domain address, which poses significant cybersecurity risks, we implemented fail2ban to mitigate brute force attacks and enhance security. Despite the continuous challenges encountered during the design and implementation process, this project demonstrates how powerful computational clusters can be built to handle resource-intensive tasks in various demanding fields.
Murmur Detection Using Parallel Recurrent & Convolutional Neural Networks
Aug 13, 2018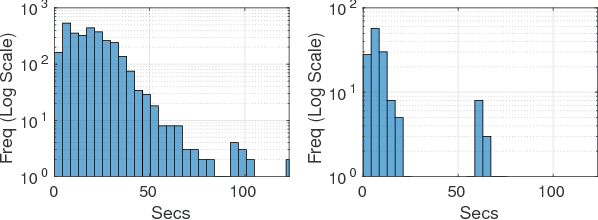
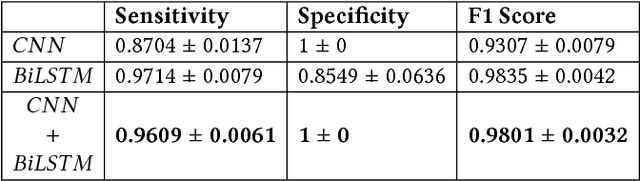
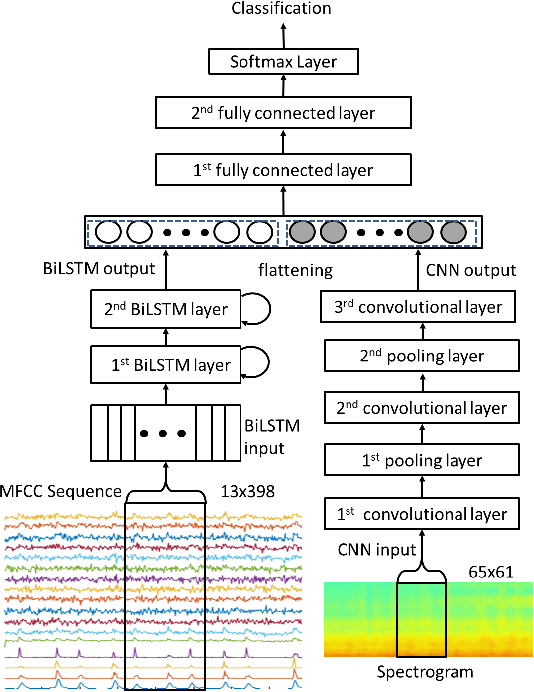
In this article, we propose a novel technique for classification of the Murmurs in heart sound. We introduce a novel deep neural network architecture using parallel combination of the Recurrent Neural Network (RNN) based Bidirectional Long Short-Term Memory (BiLSTM) & Convolutional Neural Network (CNN) to learn visual and time-dependent characteristics of Murmur in PCG waveform. Set of acoustic features are presented to our proposed deep neural network to discriminate between Normal and Murmur class. The proposed method was evaluated on a large dataset using 5-fold cross-validation, resulting in a sensitivity and specificity of 96 +- 0.6 % , 100 +- 0 % respectively and F1 Score of 98 +- 0.3 %.