 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisunited Nations? A Multiplex Network Approach to Detecting Preference Affinity Blocs using Texts and Votes
Feb 01, 2018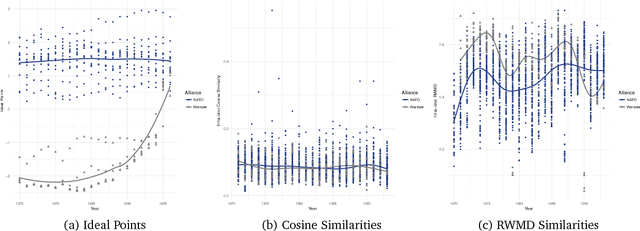
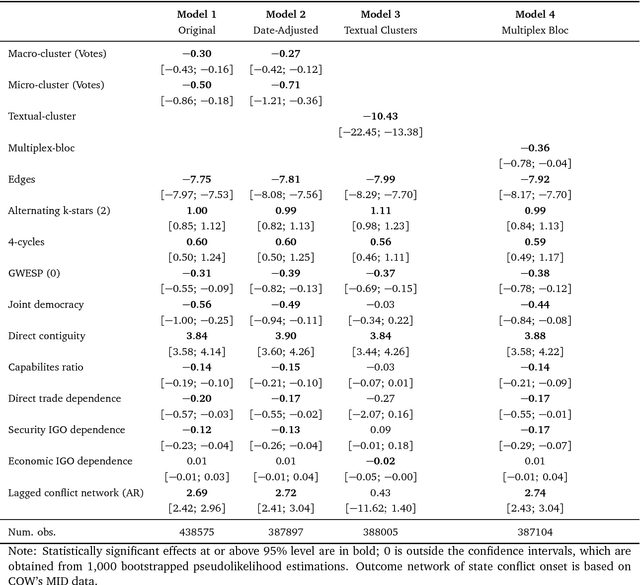
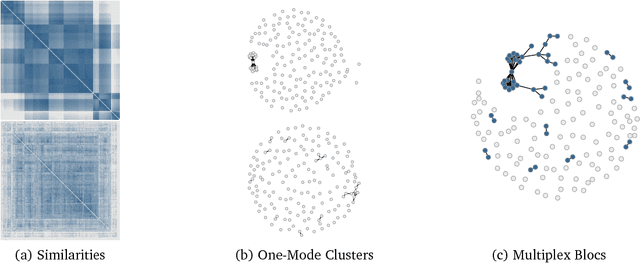
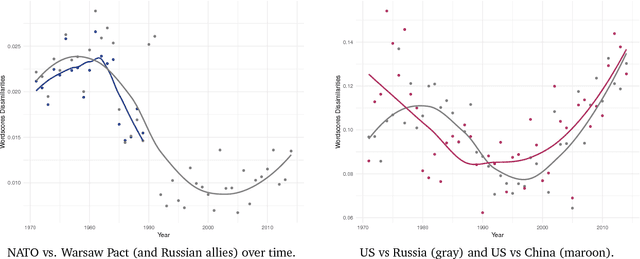
This paper contributes to an emerging literature that models votes and text in tandem to better understand polarization of expressed preferences. It introduces a new approach to estimate preference polarization in multidimensional settings, such as international relations, based on developments in the natural language processing and network science literatures -- namely word embeddings, which retain valuable syntactical qualities of human language, and community detection in multilayer networks, which locates densely connected actors across multiple, complex networks. We find that the employment of these tools in tandem helps to better estimate states' foreign policy preferences expressed in UN votes and speeches beyond that permitted by votes alone. The utility of these located affinity blocs is demonstrated through an application to conflict onset in International Relations, though these tools will be of interest to all scholars faced with the measurement of preferences and polarization in multidimensional settings.
Learning to Predict with Highly Granular Temporal Data: Estimating individual behavioral profiles with smart meter data
Nov 23, 2017
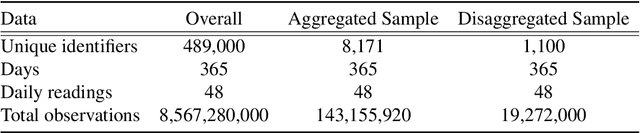
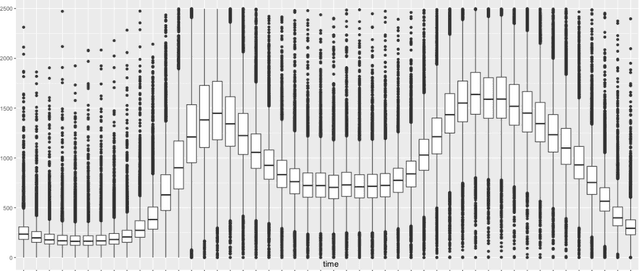
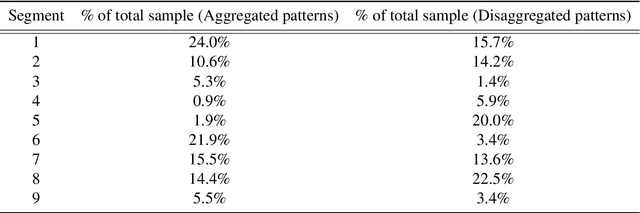
Big spatio-temporal datasets, available through both open and administrative data sources, offer significant potential for social science research. The magnitude of the data allows for increased resolution and analysis at individual level. While there are recent advances in forecasting techniques for highly granular temporal data, little attention is given to segmenting the time series and finding homogeneous patterns. In this paper, it is proposed to estimate behavioral profiles of individuals' activities over time using Gaussian Process-based models. In particular, the aim is to investigate how individuals or groups may be clustered according to the model parameters. Such a Bayesian non-parametric method is then tested by looking at the predictability of the segments using a combination of models to fit different parts of the temporal profiles. Model validity is then tested on a set of holdout data. The dataset consists of half hourly energy consumption records from smart meters from more than 100,000 households in the UK and covers the period from 2015 to 2016. The methodological approach developed in the paper may be easily applied to datasets of similar structure and granularity, for example social media data, and may lead to improved accuracy in the prediction of social dynamics and behavior.
Application of Natural Language Processing to Determine User Satisfaction in Public Services
Nov 21, 2017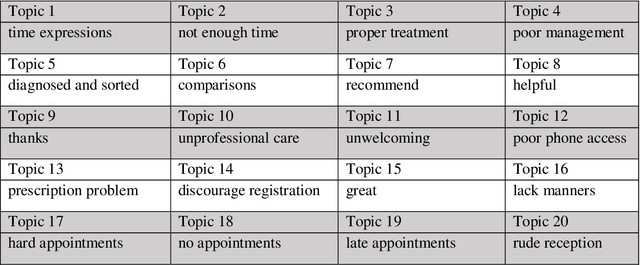
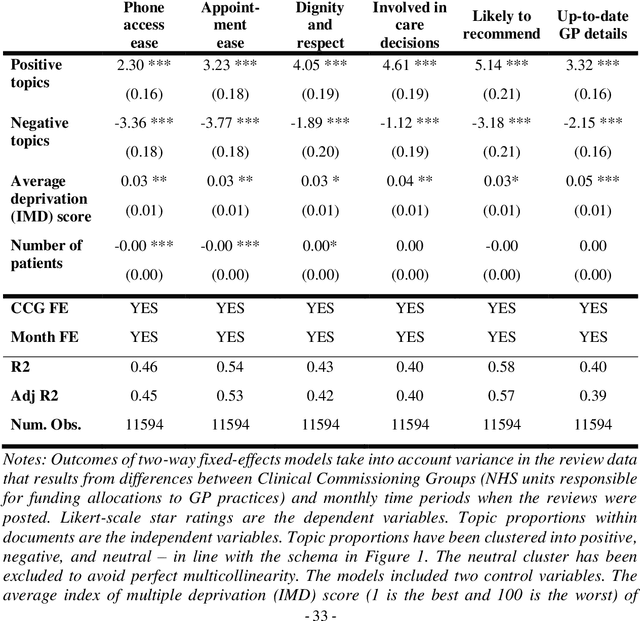
Research on customer satisfaction has increased substantially in recent years. However, the relative importance and relationships between different determinants of satisfaction remains uncertain. Moreover, quantitative studies to date tend to test for significance of pre-determined factors thought to have an influence with no scalable means to identify other causes of user satisfaction. The gaps in knowledge make it difficult to use available knowledge on user preference for public service improvement. Meanwhile, digital technology development has enabled new methods to collect user feedback, for example through online forums where users can comment freely on their experience. New tools are needed to analyze large volumes of such feedback. Use of topic models is proposed as a feasible solution to aggregate open-ended user opinions that can be easily deployed in the public sector. Generated insights can contribute to a more inclusive decision-making process in public service provision. This novel methodological approach is applied to a case of service reviews of publicly-funded primary care practices in England. Findings from the analysis of 145,000 reviews covering almost 7,700 primary care centers indicate that the quality of interactions with staff and bureaucratic exigencies are the key issues driving user satisfaction across England.
Data Innovation for International Development: An overview of natural language processing for qualitative data analysis
Sep 16, 2017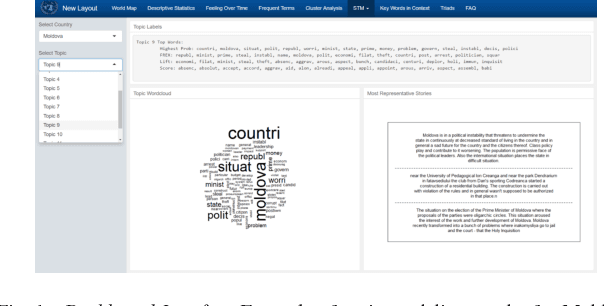
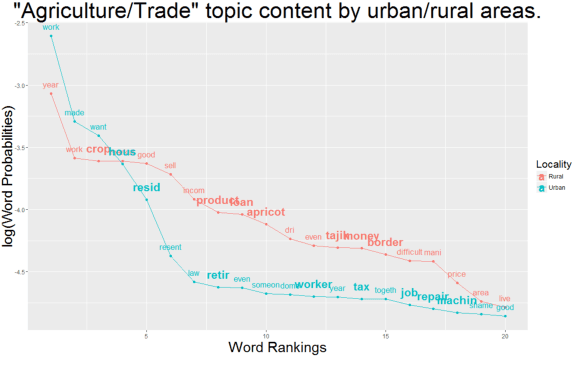

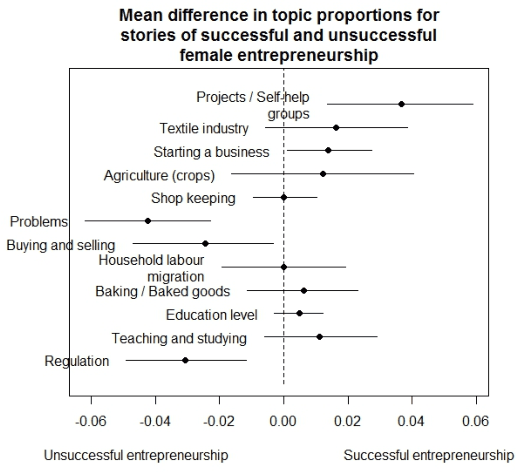
Availability, collection and access to quantitative data, as well as its limitations, often make qualitative data the resource upon which development programs heavily rely. Both traditional interview data and social media analysis can provide rich contextual information and are essential for research, appraisal, monitoring and evaluation. These data may be difficult to process and analyze both systematically and at scale. This, in turn, limits the ability of timely data driven decision-making which is essential in fast evolving complex social systems. In this paper, we discuss the potential of using natural language processing to systematize analysis of qualitative data, and to inform quick decision-making in the development context. We illustrate this with interview data generated in a format of micro-narratives for the UNDP Fragments of Impact project.
What Drives the International Development Agenda? An NLP Analysis of the United Nations General Debate 1970-2016
Aug 19, 2017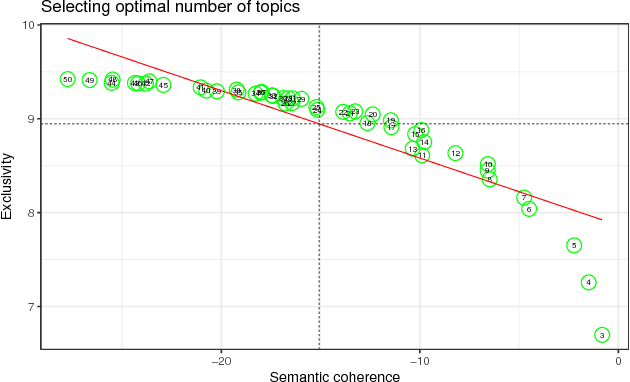



There is surprisingly little known about agenda setting for international development in the United Nations (UN) despite it having a significant influence on the process and outcomes of development efforts. This paper addresses this shortcoming using a novel approach that applies natural language processing techniques to countries' annual statements in the UN General Debate. Every year UN member states deliver statements during the General Debate on their governments' perspective on major issues in world politics. These speeches provide invaluable information on state preferences on a wide range of issues, including international development, but have largely been overlooked in the study of global politics. This paper identifies the main international development topics that states raise in these speeches between 1970 and 2016, and examine the country-specific drivers of international development rhetoric.
Database of Parliamentary Speeches in Ireland, 1919-2013
Aug 15, 2017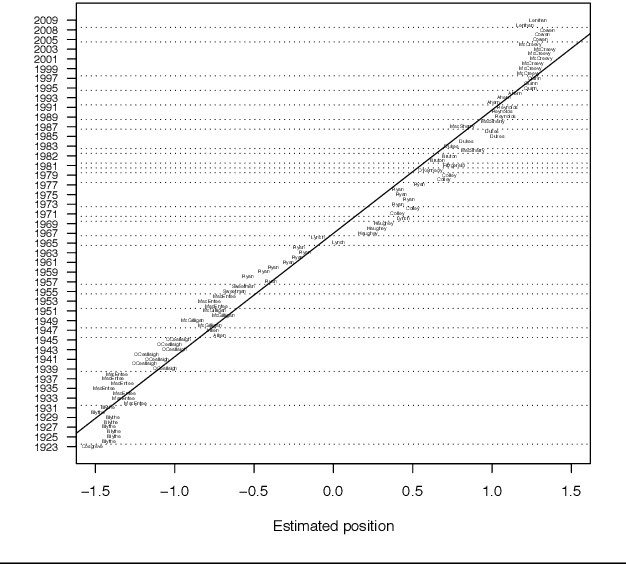
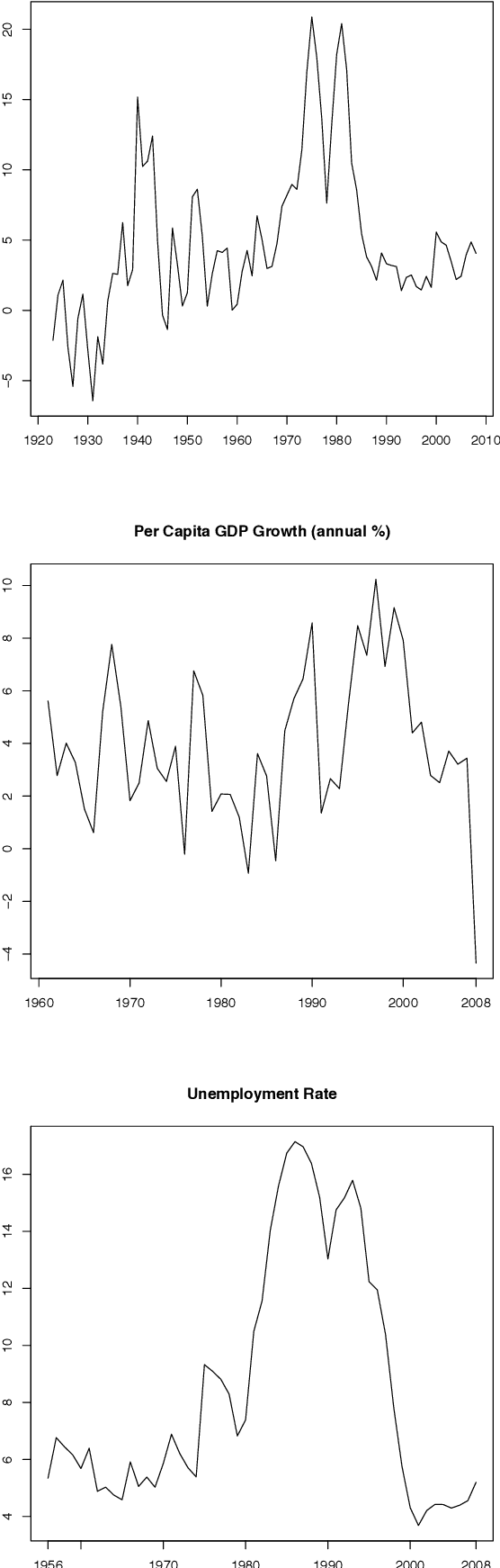
We present a database of parliamentary debates that contains the complete record of parliamentary speeches from D\'ail \'Eireann, the lower house and principal chamber of the Irish parliament, from 1919 to 2013. In addition, the database contains background information on all TDs (Teachta D\'ala, members of parliament), such as their party affiliations, constituencies and office positions. The current version of the database includes close to 4.5 million speeches from 1,178 TDs. The speeches were downloaded from the official parliament website and further processed and parsed with a Python script. Background information on TDs was collected from the member database of the parliament website. Data on cabinet positions (ministers and junior ministers) was collected from the official website of the government. A record linkage algorithm and human coders were used to match TDs and ministers.
Understanding State Preferences With Text As Data: Introducing the UN General Debate Corpus
Jul 10, 2017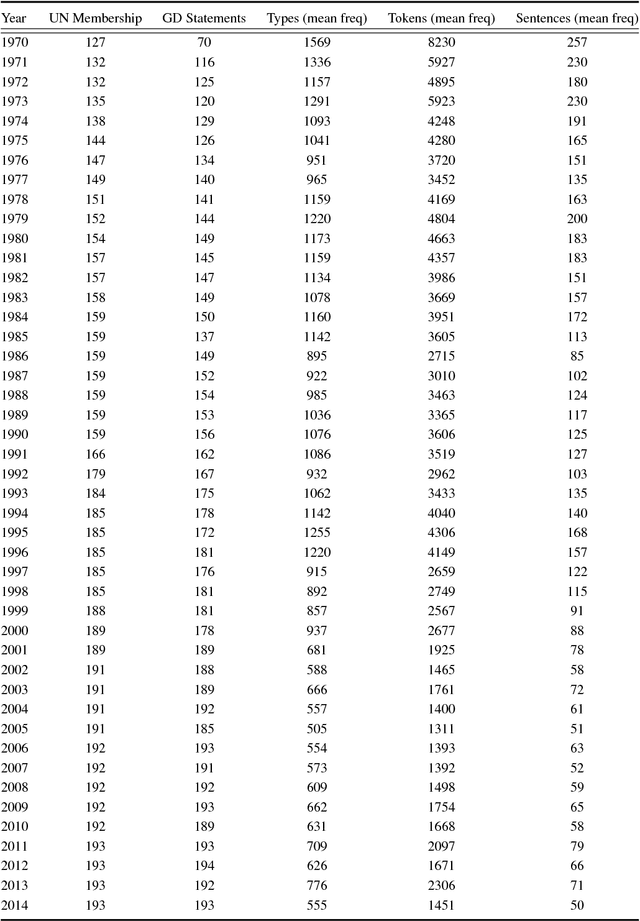
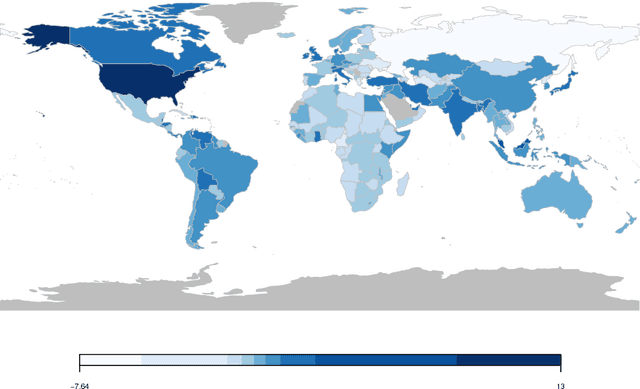

Every year at the United Nations, member states deliver statements during the General Debate discussing major issues in world politics. These speeches provide invaluable information on governments' perspectives and preferences on a wide range of issues, but have largely been overlooked in the study of international politics. This paper introduces a new dataset consisting of over 7,701 English-language country statements from 1970-2016. We demonstrate how the UN General Debate Corpus (UNGDC) can be used to derive country positions on different policy dimensions using text analytic methods. The paper provides applications of these estimates, demonstrating the contribution the UNGDC can make to the study of international politics.