 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Confidence: Training Better Classifiers from Soft Labels
Sep 24, 2024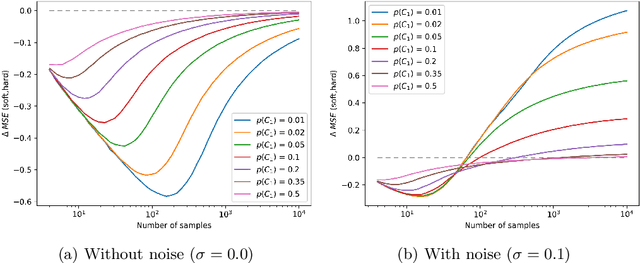
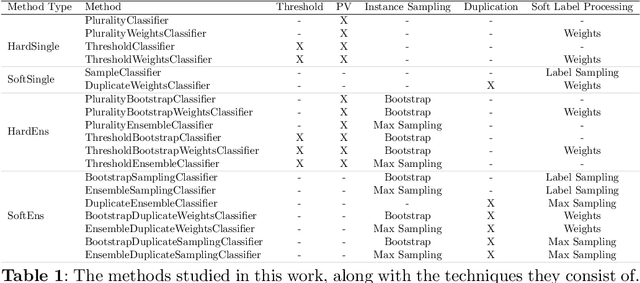
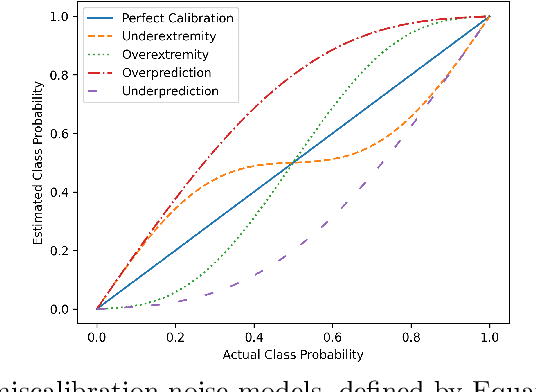

In supervised machine learning, models are typically trained using data with hard labels, i.e., definite assignments of class membership. This traditional approach, however, does not take the inherent uncertainty in these labels into account. We investigate whether incorporating label uncertainty, represented as discrete probability distributions over the class labels -- known as soft labels -- improves the predictive performance of classification models. We first demonstrate the potential value of soft label learning (SLL) for estimating model parameters in a simulation experiment, particularly for limited sample sizes and imbalanced data. Subsequently, we compare the performance of various wrapper methods for learning from both hard and soft labels using identical base classifiers. On real-world-inspired synthetic data with clean labels, the SLL methods consistently outperform hard label methods. Since real-world data is often noisy and precise soft labels are challenging to obtain, we study the effect that noisy probability estimates have on model performance. Alongside conventional noise models, our study examines four types of miscalibration that are known to affect human annotators. The results show that SLL methods outperform the hard label methods in the majority of settings. Finally, we evaluate the methods on a real-world dataset with confidence scores, where the SLL methods are shown to match the traditional methods for predicting the (noisy) hard labels while providing more accurate confidence estimates.
Generating the Ground Truth: Synthetic Data for Label Noise Research
Sep 08, 2023Most real-world classification tasks suffer from label noise to some extent. Such noise in the data adversely affects the generalization error of learned models and complicates the evaluation of noise-handling methods, as their performance cannot be accurately measured without clean labels. In label noise research, typically either noisy or incomplex simulated data are accepted as a baseline, into which additional noise with known properties is injected. In this paper, we propose SYNLABEL, a framework that aims to improve upon the aforementioned methodologies. It allows for creating a noiseless dataset informed by real data, by either pre-specifying or learning a function and defining it as the ground truth function from which labels are generated. Furthermore, by resampling a number of values for selected features in the function domain, evaluating the function and aggregating the resulting labels, each data point can be assigned a soft label or label distribution. Such distributions allow for direct injection and quantification of label noise. The generated datasets serve as a clean baseline of adjustable complexity into which different types of noise may be introduced. We illustrate how the framework can be applied, how it enables quantification of label noise and how it improves over existing methodologies.