 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Confidence: Training Better Classifiers from Soft Labels
Paper and Code
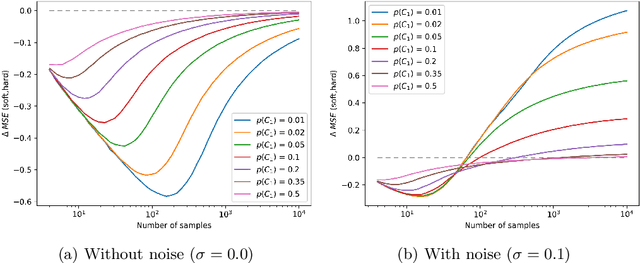
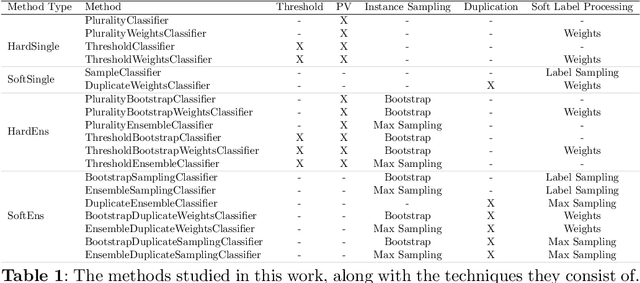
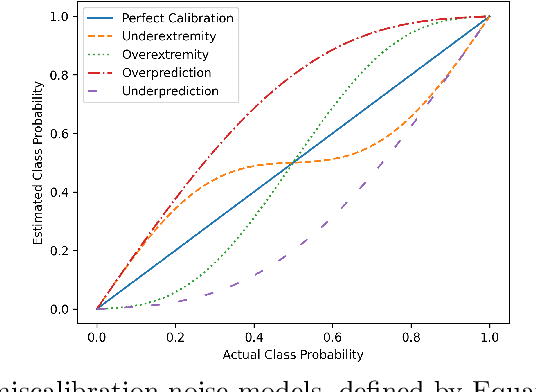

In supervised machine learning, models are typically trained using data with hard labels, i.e., definite assignments of class membership. This traditional approach, however, does not take the inherent uncertainty in these labels into account. We investigate whether incorporating label uncertainty, represented as discrete probability distributions over the class labels -- known as soft labels -- improves the predictive performance of classification models. We first demonstrate the potential value of soft label learning (SLL) for estimating model parameters in a simulation experiment, particularly for limited sample sizes and imbalanced data. Subsequently, we compare the performance of various wrapper methods for learning from both hard and soft labels using identical base classifiers. On real-world-inspired synthetic data with clean labels, the SLL methods consistently outperform hard label methods. Since real-world data is often noisy and precise soft labels are challenging to obtain, we study the effect that noisy probability estimates have on model performance. Alongside conventional noise models, our study examines four types of miscalibration that are known to affect human annotators. The results show that SLL methods outperform the hard label methods in the majority of settings. Finally, we evaluate the methods on a real-world dataset with confidence scores, where the SLL methods are shown to match the traditional methods for predicting the (noisy) hard labels while providing more accurate confidence estimates.