 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROAST: Review-level Opinion Aspect Sentiment Target Joint Detection
May 30, 2024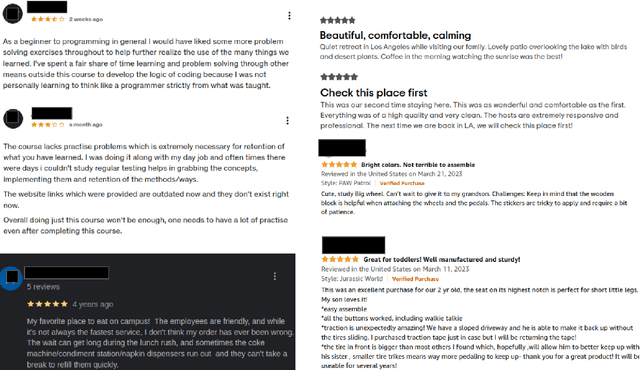
Aspect-Based Sentiment Analysis (ABSA) has experienced tremendous expansion and diversity due to various shared tasks spanning several languages and fields and organized via SemEval workshops and Germeval. Nonetheless, a few shortcomings still need to be addressed, such as the lack of low-resource language evaluations and the emphasis on sentence-level analysis. To thoroughly assess ABSA techniques in the context of complete reviews, this research presents a novel task, Review-Level Opinion Aspect Sentiment Target (ROAST). ROAST seeks to close the gap between sentence-level and text-level ABSA by identifying every ABSA constituent at the review level. We extend the available datasets to enable ROAST, addressing the drawbacks noted in previous research by incorporating low-resource languages, numerous languages, and a variety of topics. Through this effort, ABSA research will be able to cover more ground and get a deeper comprehension of the task and its practical application in a variety of languages and domains (https://github.com/RiTUAL-UH/ROAST-ABSA).
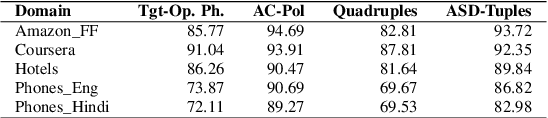
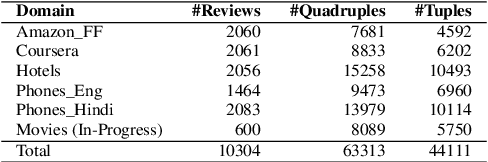
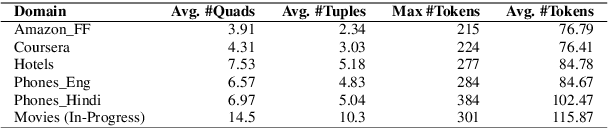
OATS: Opinion Aspect Target Sentiment Quadruple Extraction Dataset for Aspect-Based Sentiment Analysis
Sep 23, 2023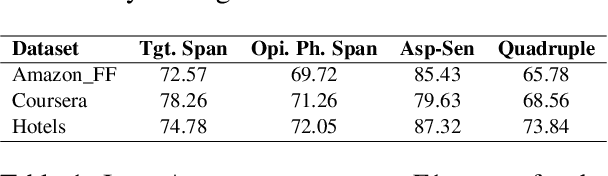
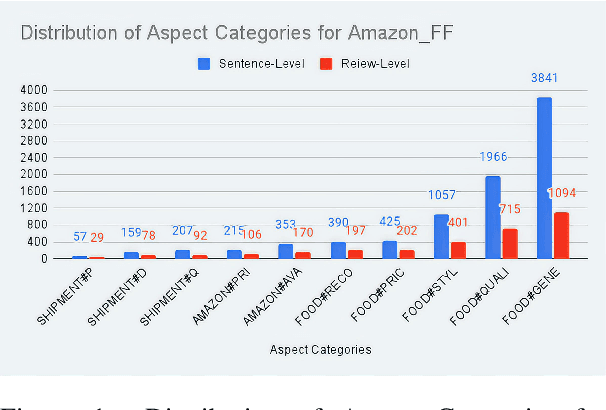
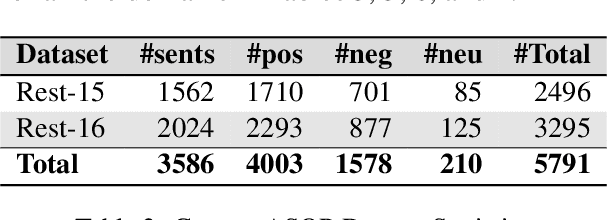
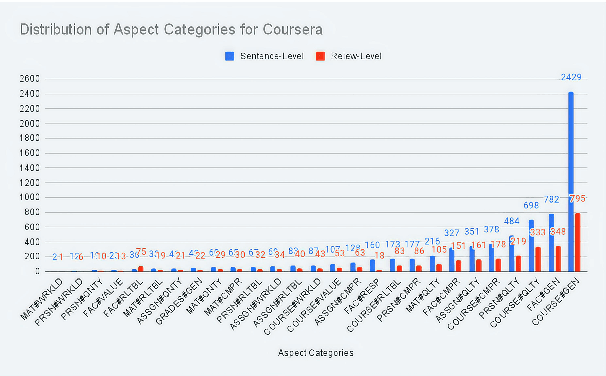
Aspect-based sentiment Analysis (ABSA) delves into understanding sentiments specific to distinct elements within textual content. It aims to analyze user-generated reviews to determine a) the target entity being reviewed, b) the high-level aspect to which it belongs, c) the sentiment words used to express the opinion, and d) the sentiment expressed toward the targets and the aspects. While various benchmark datasets have fostered advancements in ABSA, they often come with domain limitations and data granularity challenges. Addressing these, we introduce the OATS dataset, which encompasses three fresh domains and consists of 20,000 sentence-level quadruples and 13,000 review-level tuples. Our initiative seeks to bridge specific observed gaps: the recurrent focus on familiar domains like restaurants and laptops, limited data for intricate quadruple extraction tasks, and an occasional oversight of the synergy between sentence and review-level sentiments. Moreover, to elucidate OATS's potential and shed light on various ABSA subtasks that OATS can solve, we conducted in-domain and cross-domain experiments, establishing initial baselines. We hope the OATS dataset augments current resources, paving the way for an encompassing exploration of ABSA.
Survey of Aspect-based Sentiment Analysis Datasets
Apr 11, 2022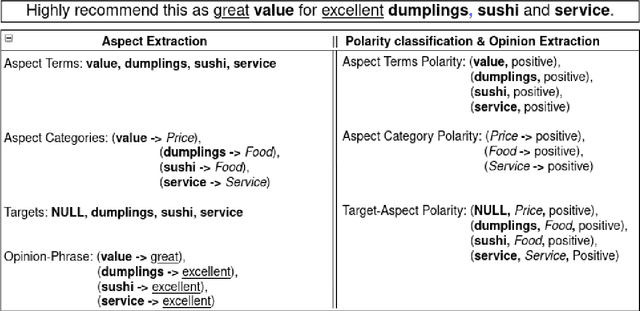
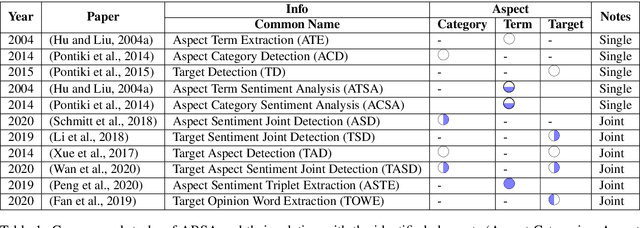
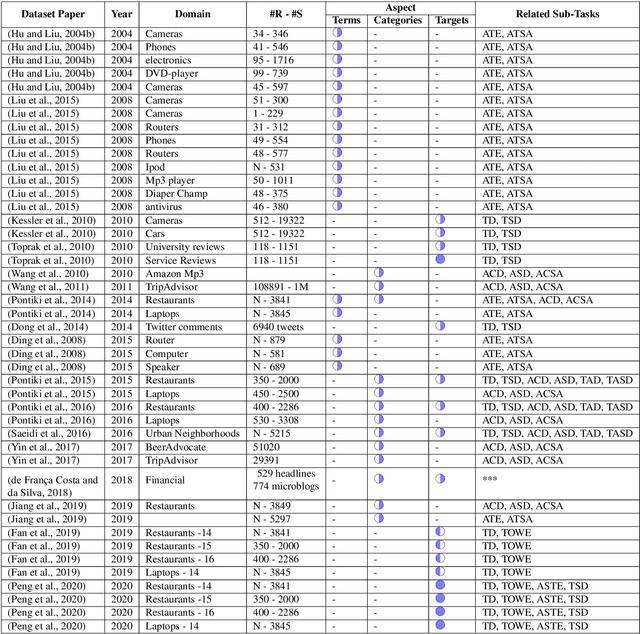
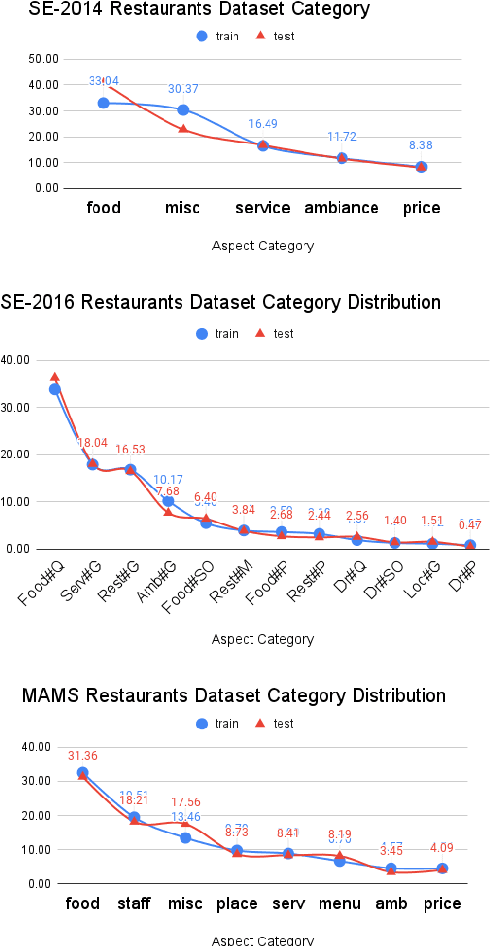
Aspect-based sentiment analysis (ABSA) is a natural language processing problem that requires analyzing user-generated reviews in order to determine: a) The target entity being reviewed, b) The high-level aspect to which it belongs, and c) The sentiment expressed toward the targets and the aspects. Numerous yet scattered corpora for ABSA make it difficult for researchers to quickly identify corpora best suited for a specific ABSA subtask. This study aims to present a database of corpora that can be used to train and assess autonomous ABSA systems. Additionally, we provide an overview of the major corpora concerning the various ABSA and its subtasks and highlight several corpus features that researchers should consider when selecting a corpus. We conclude that further large-scale ABSA corpora are required. Additionally, because each corpus is constructed differently, it is time-consuming for researchers to experiment with a novel ABSA algorithm on many corpora and often employ just one or a few corpora. The field would benefit from an agreement on a data standard for ABSA corpora. Finally, we discuss the advantages and disadvantages of current collection approaches and make recommendations for future ABSA dataset gathering.
Exploring Conditional Text Generation for Aspect-Based Sentiment Analysis
Oct 07, 2021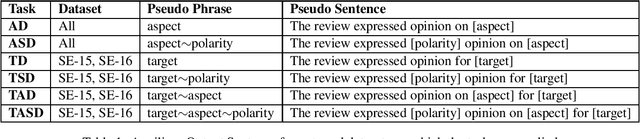
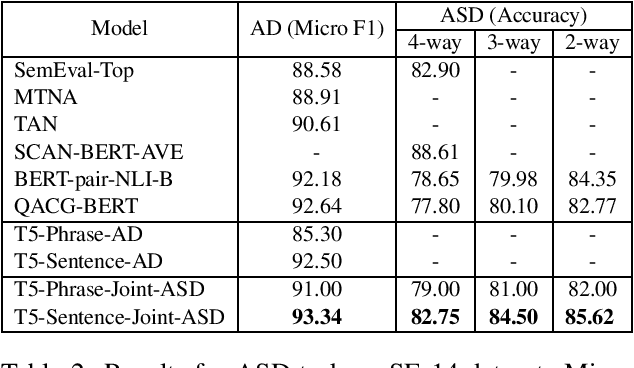
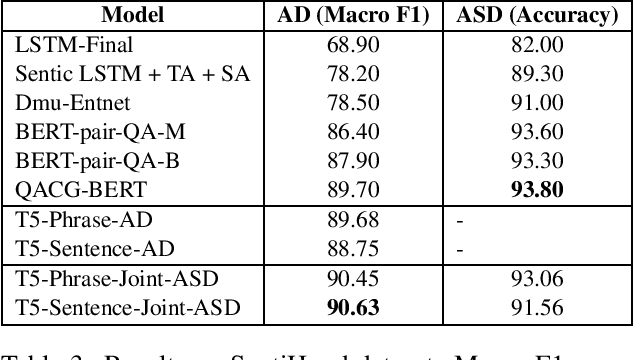
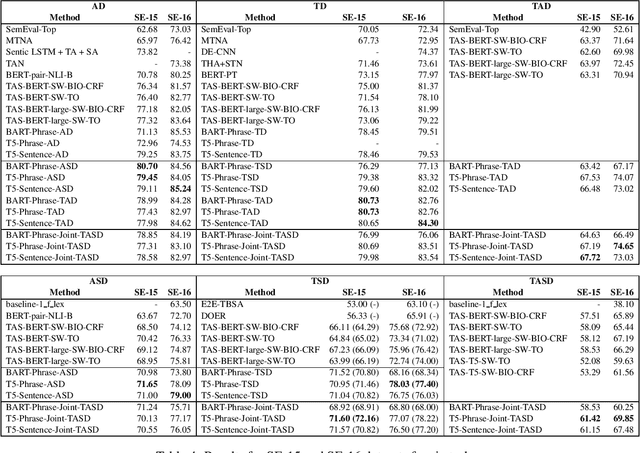
Aspect-based sentiment analysis (ABSA) is an NLP task that entails processing user-generated reviews to determine (i) the target being evaluated, (ii) the aspect category to which it belongs, and (iii) the sentiment expressed towards the target and aspect pair. In this article, we propose transforming ABSA into an abstract summary-like conditional text generation task that uses targets, aspects, and polarities to generate auxiliary statements. To demonstrate the efficacy of our task formulation and a proposed system, we fine-tune a pre-trained model for conditional text generation tasks to get new state-of-the-art results on a few restaurant domains and urban neighborhoods domain benchmark datasets.