 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey of Aspect-based Sentiment Analysis Datasets
Paper and Code
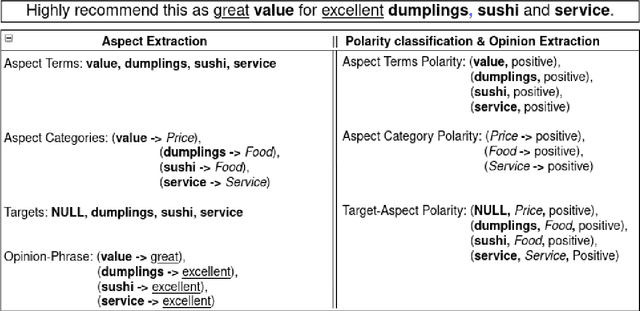
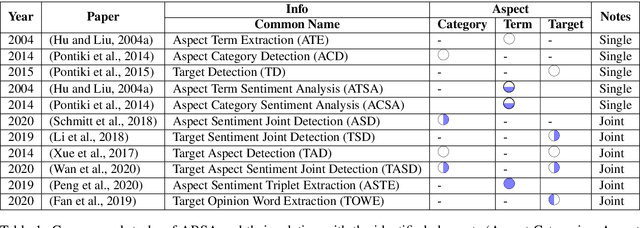
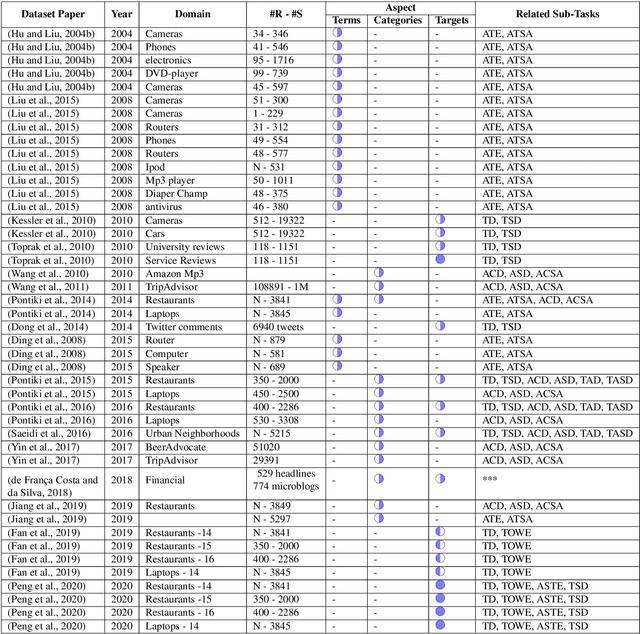
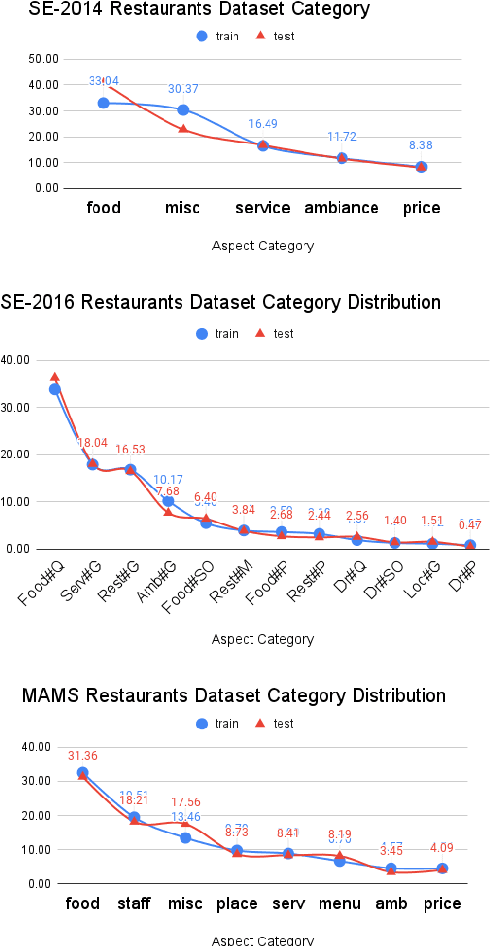
Aspect-based sentiment analysis (ABSA) is a natural language processing problem that requires analyzing user-generated reviews in order to determine: a) The target entity being reviewed, b) The high-level aspect to which it belongs, and c) The sentiment expressed toward the targets and the aspects. Numerous yet scattered corpora for ABSA make it difficult for researchers to quickly identify corpora best suited for a specific ABSA subtask. This study aims to present a database of corpora that can be used to train and assess autonomous ABSA systems. Additionally, we provide an overview of the major corpora concerning the various ABSA and its subtasks and highlight several corpus features that researchers should consider when selecting a corpus. We conclude that further large-scale ABSA corpora are required. Additionally, because each corpus is constructed differently, it is time-consuming for researchers to experiment with a novel ABSA algorithm on many corpora and often employ just one or a few corpora. The field would benefit from an agreement on a data standard for ABSA corpora. Finally, we discuss the advantages and disadvantages of current collection approaches and make recommendations for future ABSA dataset gathering.