 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Large Language Models in Legal Applications: Challenges, Methods, and Future Directions
Jan 21, 2026Large language models (LLMs) are being increasingly integrated into legal applications, including judicial decision support, legal practice assistance, and public-facing legal services. While LLMs show strong potential in handling legal knowledge and tasks, their deployment in real-world legal settings raises critical concerns beyond surface-level accuracy, involving the soundness of legal reasoning processes and trustworthy issues such as fairness and reliability. Systematic evaluation of LLM performance in legal tasks has therefore become essential for their responsible adoption. This survey identifies key challenges in evaluating LLMs for legal tasks grounded in real-world legal practice. We analyze the major difficulties involved in assessing LLM performance in the legal domain, including outcome correctness, reasoning reliability, and trustworthiness. Building on these challenges, we review and categorize existing evaluation methods and benchmarks according to their task design, datasets, and evaluation metrics. We further discuss the extent to which current approaches address these challenges, highlight their limitations, and outline future research directions toward more realistic, reliable, and legally grounded evaluation frameworks for LLMs in legal domains.
Retrieving Supporting Evidence for Generative Question Answering
Sep 20, 2023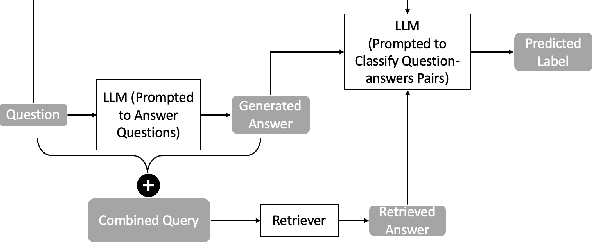


Current large language models (LLMs) can exhibit near-human levels of performance on many natural language-based tasks, including open-domain question answering. Unfortunately, at this time, they also convincingly hallucinate incorrect answers, so that responses to questions must be verified against external sources before they can be accepted at face value. In this paper, we report two simple experiments to automatically validate generated answers against a corpus. We base our experiments on questions and passages from the MS MARCO (V1) test collection, and a retrieval pipeline consisting of sparse retrieval, dense retrieval and neural rerankers. In the first experiment, we validate the generated answer in its entirety. After presenting a question to an LLM and receiving a generated answer, we query the corpus with the combination of the question + generated answer. We then present the LLM with the combination of the question + generated answer + retrieved answer, prompting it to indicate if the generated answer can be supported by the retrieved answer. In the second experiment, we consider the generated answer at a more granular level, prompting the LLM to extract a list of factual statements from the answer and verifying each statement separately. We query the corpus with each factual statement and then present the LLM with the statement and the corresponding retrieved evidence. The LLM is prompted to indicate if the statement can be supported and make necessary edits using the retrieved material. With an accuracy of over 80%, we find that an LLM is capable of verifying its generated answer when a corpus of supporting material is provided. However, manual assessment of a random sample of questions reveals that incorrect generated answers are missed by this verification process. While this verification process can reduce hallucinations, it can not entirely eliminate them.
Retrieving Supporting Evidence for LLMs Generated Answers
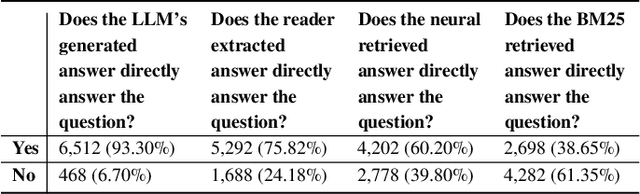
Jun 23, 2023Current large language models (LLMs) can exhibit near-human levels of performance on many natural language tasks, including open-domain question answering. Unfortunately, they also convincingly hallucinate incorrect answers, so that responses to questions must be verified against external sources before they can be accepted at face value. In this paper, we report a simple experiment to automatically verify generated answers against a corpus. After presenting a question to an LLM and receiving a generated answer, we query the corpus with the combination of the question + generated answer. We then present the LLM with the combination of the question + generated answer + retrieved answer, prompting it to indicate if the generated answer can be supported by the retrieved answer. We base our experiment on questions and passages from the MS MARCO (V1) test collection, exploring three retrieval approaches ranging from standard BM25 to a full question answering stack, including a reader based on the LLM. For a large fraction of questions, we find that an LLM is capable of verifying its generated answer if appropriate supporting material is provided. However, with an accuracy of 70-80%, this approach cannot be fully relied upon to detect hallucinations.