 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generative Restricted Boltzmann Machine Based Method for High-Dimensional Motion Data Modeling
Oct 21, 2017
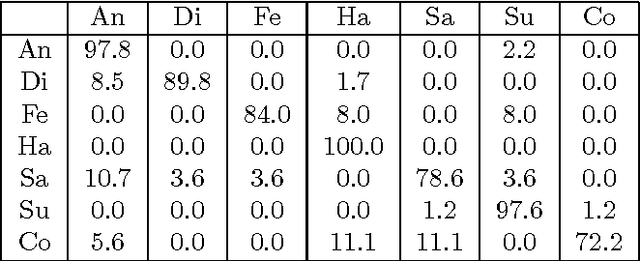
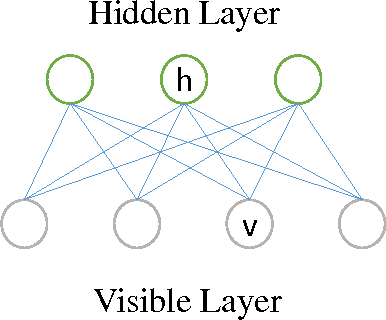
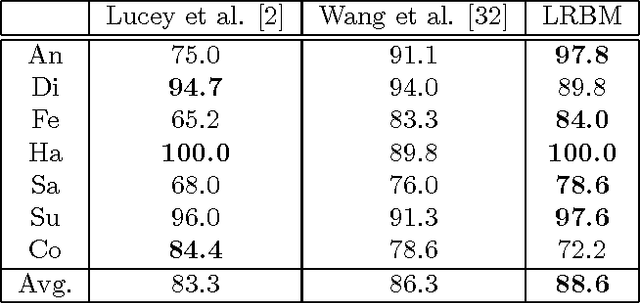
Many computer vision applications involve modeling complex spatio-temporal patterns in high-dimensional motion data. Recently, restricted Boltzmann machines (RBMs) have been widely used to capture and represent spatial patterns in a single image or temporal patterns in several time slices. To model global dynamics and local spatial interactions, we propose to theoretically extend the conventional RBMs by introducing another term in the energy function to explicitly model the local spatial interactions in the input data. A learning method is then proposed to perform efficient learning for the proposed model. We further introduce a new method for multi-class classification that can effectively estimate the infeasible partition functions of different RBMs such that RBM is treated as a generative model for classification purpose. The improved RBM model is evaluated on two computer vision applications: facial expression recognition and human action recognition. Experimental results on benchmark databases demonstrate the effectiveness of the proposed algorithm.
Deep Regression Bayesian Network and Its Applications
Oct 13, 2017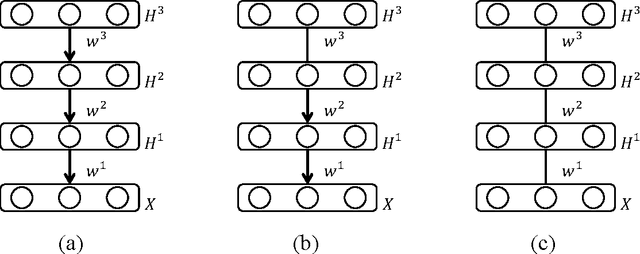
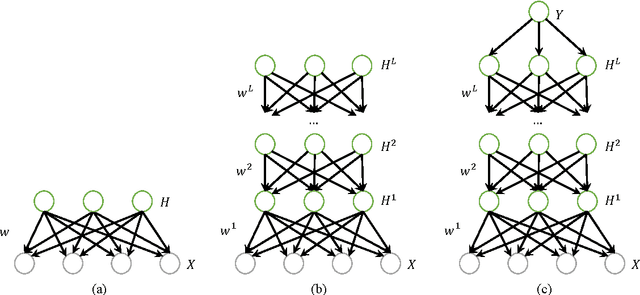

Deep directed generative models have attracted much attention recently due to their generative modeling nature and powerful data representation ability. In this paper, we review different structures of deep directed generative models and the learning and inference algorithms associated with the structures. We focus on a specific structure that consists of layers of Bayesian Networks due to the property of capturing inherent and rich dependencies among latent variables. The major difficulty of learning and inference with deep directed models with many latent variables is the intractable inference due to the dependencies among the latent variables and the exponential number of latent variable configurations. Current solutions use variational methods often through an auxiliary network to approximate the posterior probability inference. In contrast, inference can also be performed directly without using any auxiliary network to maximally preserve the dependencies among the latent variables. Specifically, by exploiting the sparse representation with the latent space, max-max instead of max-sum operation can be used to overcome the exponential number of latent configurations. Furthermore, the max-max operation and augmented coordinate ascent are applied to both supervised and unsupervised learning as well as to various inference. Quantitative evaluations on benchmark datasets of different models are given for both data representation and feature learning tasks.
Latent Regression Bayesian Network for Data Representation
Jun 15, 2015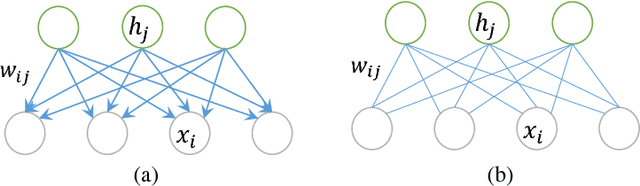
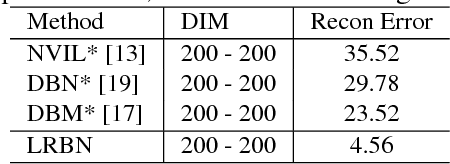

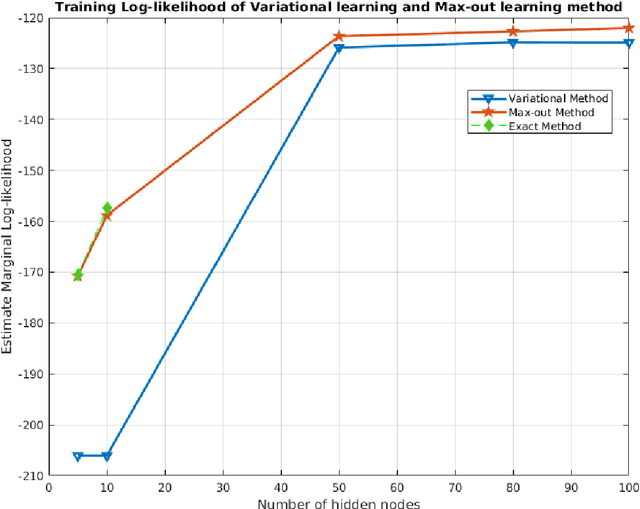
Deep directed generative models have attracted much attention recently due to their expressive representation power and the ability of ancestral sampling. One major difficulty of learning directed models with many latent variables is the intractable inference. To address this problem, most existing algorithms make assumptions to render the latent variables independent of each other, either by designing specific priors, or by approximating the true posterior using a factorized distribution. We believe the correlations among latent variables are crucial for faithful data representation. Driven by this idea, we propose an inference method based on the conditional pseudo-likelihood that preserves the dependencies among the latent variables. For learning, we propose to employ the hard Expectation Maximization (EM) algorithm, which avoids the intractability of the traditional EM by max-out instead of sum-out to compute the data likelihood. Qualitative and quantitative evaluations of our model against state of the art deep models on benchmark datasets demonstrate the effectiveness of the proposed algorithm in data representation and reconstruction.
Advances in Learning Bayesian Networks of Bounded Treewidth
Jun 06, 2014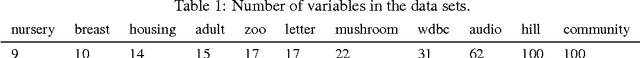
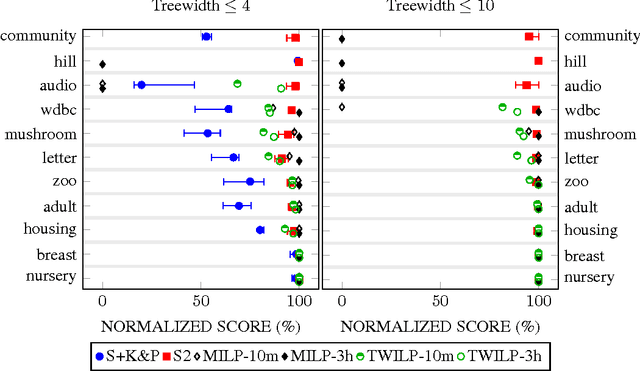
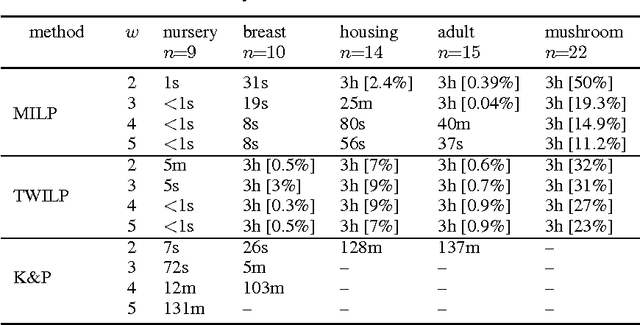
This work presents novel algorithms for learning Bayesian network structures with bounded treewidth. Both exact and approximate methods are developed. The exact method combines mixed-integer linear programming formulations for structure learning and treewidth computation. The approximate method consists in uniformly sampling $k$-trees (maximal graphs of treewidth $k$), and subsequently selecting, exactly or approximately, the best structure whose moral graph is a subgraph of that $k$-tree. Some properties of these methods are discussed and proven. The approaches are empirically compared to each other and to a state-of-the-art method for learning bounded treewidth structures on a collection of public data sets with up to 100 variables. The experiments show that our exact algorithm outperforms the state of the art, and that the approximate approach is fairly accurate.