 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFNet: Discriminative feature extraction and integration network for salient object detection
Apr 03, 2020
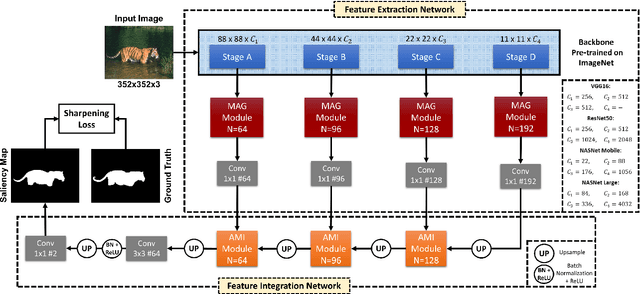
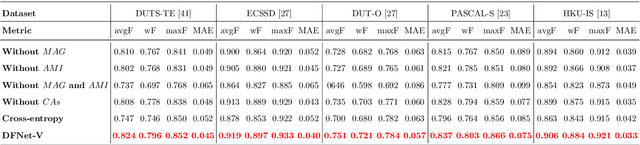
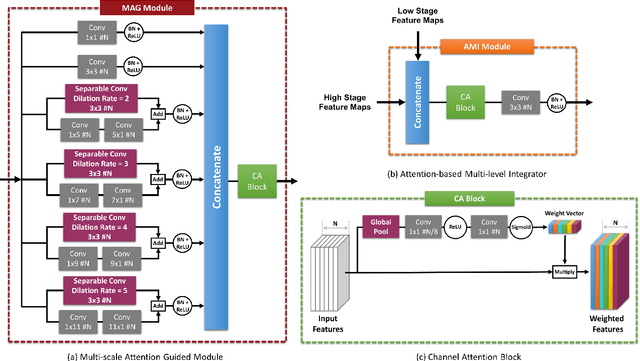
Despite the powerful feature extraction capability of Convolutional Neural Networks, there are still some challenges in saliency detection. In this paper, we focus on two aspects of challenges: i) Since salient objects appear in various sizes, using single-scale convolution would not capture the right size. Moreover, using multi-scale convolutions without considering their importance may confuse the model. ii) Employing multi-level features helps the model use both local and global context. However, treating all features equally results in information redundancy. Therefore, there needs to be a mechanism to intelligently select which features in different levels are useful. To address the first challenge, we propose a Multi-scale Attention Guided Module. This module not only extracts multi-scale features effectively but also gives more attention to more discriminative feature maps corresponding to the scale of the salient object. To address the second challenge, we propose an Attention-based Multi-level Integrator Module to give the model the ability to assign different weights to multi-level feature maps. Furthermore, our Sharpening Loss function guides our network to output saliency maps with higher certainty and less blurry salient objects, and it has far better performance than the Cross-entropy loss. For the first time, we adopt four different backbones to show the generalization of our method. Experiments on five challenging datasets prove that our method achieves the state-of-the-art performance. Our approach is fast as well and can run at a real-time speed.
Ensembles of Deep Neural Networks for Action Recognition in Still Images
Mar 22, 2020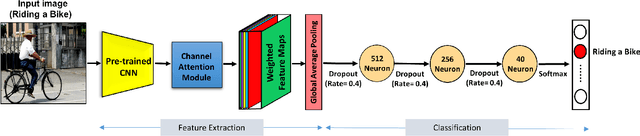
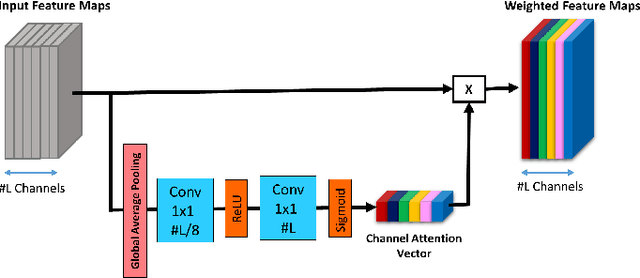
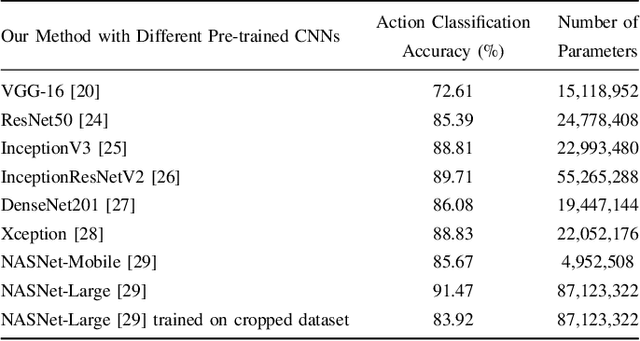

Despite the fact that notable improvements have been made recently in the field of feature extraction and classification, human action recognition is still challenging, especially in images, in which, unlike videos, there is no motion. Thus, the methods proposed for recognizing human actions in videos cannot be applied to still images. A big challenge in action recognition in still images is the lack of large enough datasets, which is problematic for training deep Convolutional Neural Networks (CNNs) due to the overfitting issue. In this paper, by taking advantage of pre-trained CNNs, we employ the transfer learning technique to tackle the lack of massive labeled action recognition datasets. Furthermore, since the last layer of the CNN has class-specific information, we apply an attention mechanism on the output feature maps of the CNN to extract more discriminative and powerful features for classification of human actions. Moreover, we use eight different pre-trained CNNs in our framework and investigate their performance on Stanford 40 dataset. Finally, we propose using the Ensemble Learning technique to enhance the overall accuracy of action classification by combining the predictions of multiple models. The best setting of our method is able to achieve 93.17$\%$ accuracy on the Stanford 40 dataset.
* 5 pages, 2 figures, 3 tables, Accepted by ICCKE 2019
CAGNet: Content-Aware Guidance for Salient Object Detection
Nov 29, 2019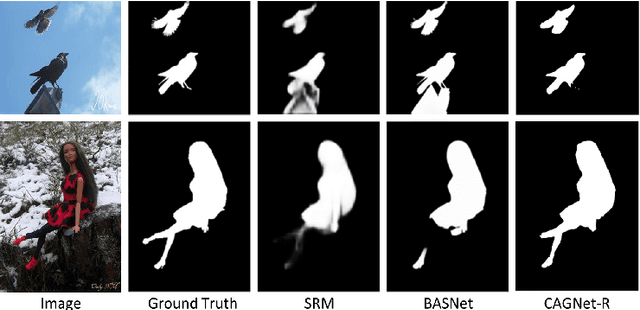
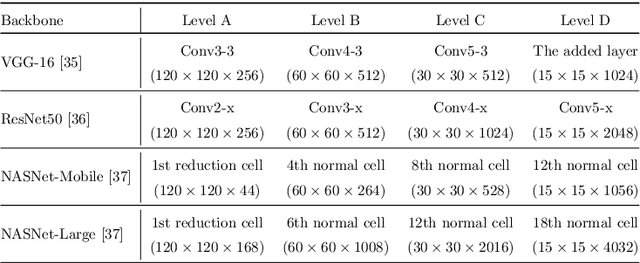
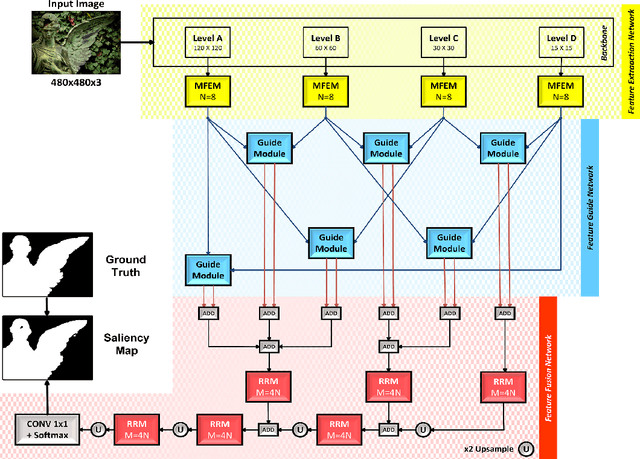
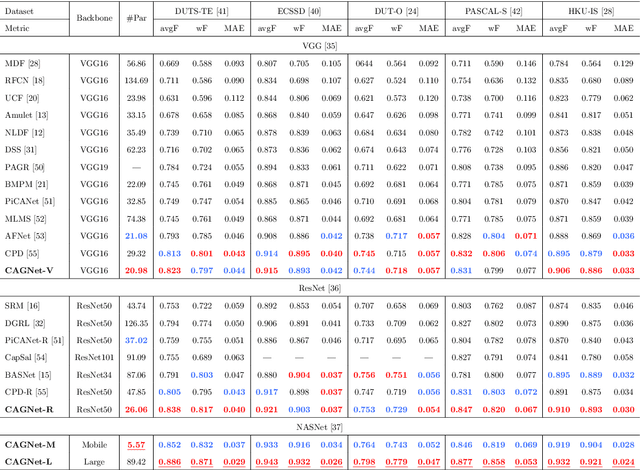
Beneficial from Fully Convolutional Neural Networks (FCNs), saliency detection methods have achieved promising results. However, it is still challenging to learn effective features for detecting salient objects in complicated scenarios, in which i) non-salient regions may have "salient-like" appearance; ii) the salient objects may have different-looking regions. To handle these complex scenarios, we propose a Feature Guide Network which exploits the nature of low-level and high-level features to i) make foreground and background regions more distinct and suppress the non-salient regions which have "salient-like" appearance; ii) assign foreground label to different-looking salient regions. Furthermore, we utilize a Multi-scale Feature Extraction Module (MFEM) for each level of abstraction to obtain multi-scale contextual information. Finally, we design a loss function which outperforms the widely-used Cross-entropy loss. By adopting four different pre-trained models as the backbone, we prove that our method is very general with respect to the choice of the backbone model. Experiments on five challenging datasets demonstrate that our method achieves the state-of-the-art performance in terms of different evaluation metrics. Additionally, our approach contains fewer parameters than the existing ones, does not need any post-processing, and runs fast at a real-time speed of 28 FPS when processing a 480 x 480 image.