 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Neural Predictivity in the Visual Cortex with Gated Recurrent Connections
Mar 22, 2022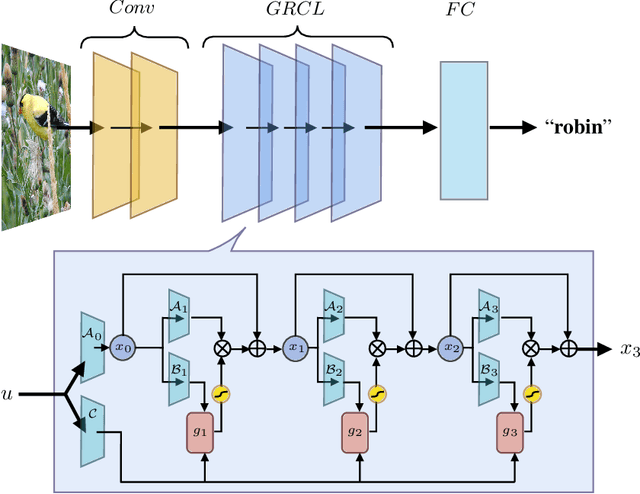
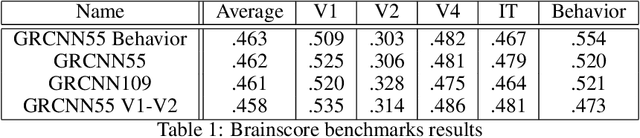
Computational models of vision have traditionally been developed in a bottom-up fashion, by hierarchically composing a series of straightforward operations - i.e. convolution and pooling - with the aim of emulating simple and complex cells in the visual cortex, resulting in the introduction of deep convolutional neural networks (CNNs). Nevertheless, data obtained with recent neuronal recording techniques support that the nature of the computations carried out in the ventral visual stream is not completely captured by current deep CNN models. To fill the gap between the ventral visual stream and deep models, several benchmarks have been designed and organized into the Brain-Score platform, granting a way to perform multi-layer (V1, V2, V4, IT) and behavioral comparisons between the two counterparts. In our work, we aim to shift the focus on architectures that take into account lateral recurrent connections, a ubiquitous feature of the ventral visual stream, to devise adaptive receptive fields. Through recurrent connections, the input s long-range spatial dependencies can be captured in a local multi-step fashion and, as introduced with Gated Recurrent CNNs (GRCNN), the unbounded expansion of the neuron s receptive fields can be modulated through the use of gates. In order to increase the robustness of our approach and the biological fidelity of the activations, we employ specific data augmentation techniques in line with several of the scoring benchmarks. Enforcing some form of invariance, through heuristics, was found to be beneficial for better neural predictivity.
Topological Data Analysis (TDA) Techniques Enhance Hand Pose Classification from ECoG Neural Recordings
Oct 09, 2021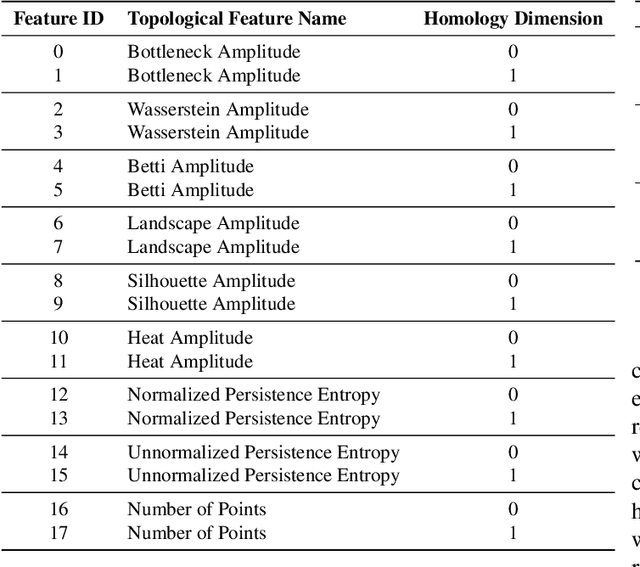
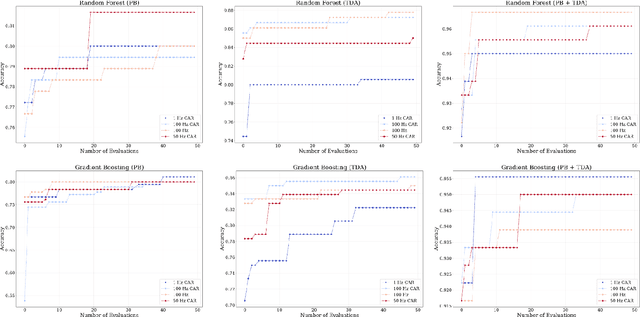
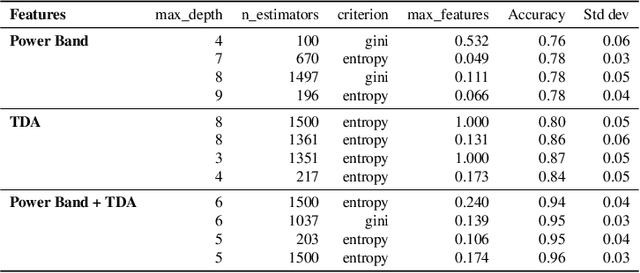
Electrocorticogram (ECoG) well characterizes hand movement intentions and gestures. In the present work we aim to investigate the possibility to enhance hand pose classification, in a Rock-Paper-Scissor - and Rest - task, by introducing topological descriptors of time series data. We hypothesized that an innovative approach based on topological data analysis can extract hidden information that are not detectable with standard Brain Computer Interface (BCI)techniques. To investigate this hypothesis, we integrate topological features together with power band features and feed them to several standard classifiers, e.g. Random Forest,Gradient Boosting. Model selection is thus completed after a meticulous phase of bayesian hyperparameter optimization. With our method, we observed robust results in terms of ac-curacy for a four-labels classification problem, with limited available data. Through feature importance investigation, we conclude that topological descriptors are able to extract useful discriminative information and provide novel insights.Since our data are restricted to single-patient recordings, generalization might be limited. Nevertheless, our method can be extended and applied to a wide range of neurophysiological recordings and it might be an intriguing point of departure for future studies.
Latin writing styles analysis with Machine Learning: New approach to old questions
Sep 01, 2021
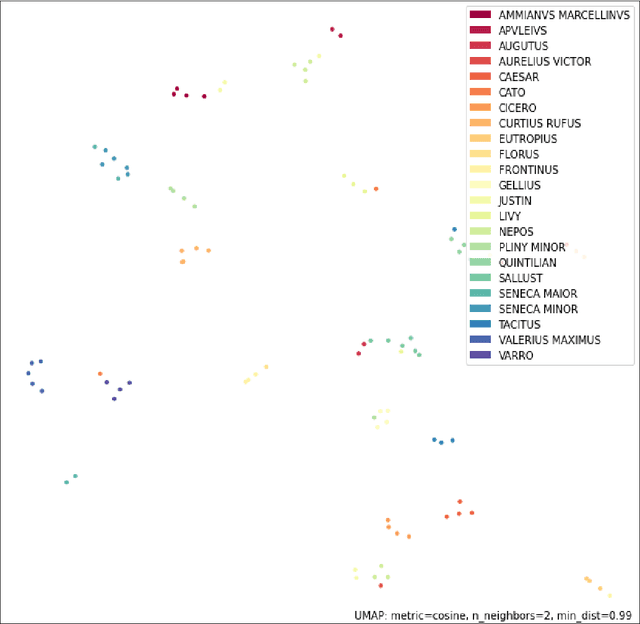


In the Middle Ages texts were learned by heart and spread using oral means of communication from generation to generation. Adaptation of the art of prose and poems allowed keeping particular descriptions and compositions characteristic for many literary genres. Taking into account such a specific construction of literature composed in Latin, we can search for and indicate the probability patterns of familiar sources of specific narrative texts. Consideration of Natural Language Processing tools allowed us the transformation of textual objects into numerical ones and then application of machine learning algorithms to extract information from the dataset. We carried out the task consisting of the practical use of those concepts and observation to create a tool for analyzing narrative texts basing on open-source databases. The tool focused on creating specific search tools resources which could enable us detailed searching throughout the text. The main objectives of the study take into account finding similarities between sentences and between documents. Next, we applied machine learning algorithms on chosen texts to calculate specific features of them (for instance authorship or centuries) and to recognize sources of anonymous texts with a certain percentage.