 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatin writing styles analysis with Machine Learning: New approach to old questions
Sep 01, 2021
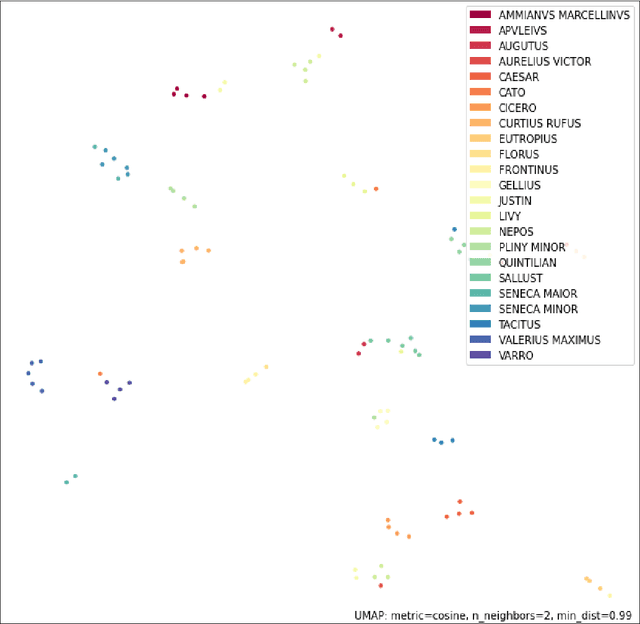


In the Middle Ages texts were learned by heart and spread using oral means of communication from generation to generation. Adaptation of the art of prose and poems allowed keeping particular descriptions and compositions characteristic for many literary genres. Taking into account such a specific construction of literature composed in Latin, we can search for and indicate the probability patterns of familiar sources of specific narrative texts. Consideration of Natural Language Processing tools allowed us the transformation of textual objects into numerical ones and then application of machine learning algorithms to extract information from the dataset. We carried out the task consisting of the practical use of those concepts and observation to create a tool for analyzing narrative texts basing on open-source databases. The tool focused on creating specific search tools resources which could enable us detailed searching throughout the text. The main objectives of the study take into account finding similarities between sentences and between documents. Next, we applied machine learning algorithms on chosen texts to calculate specific features of them (for instance authorship or centuries) and to recognize sources of anonymous texts with a certain percentage.