 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning Based Prediction of PID Controller Gains for Quadrotor UAVs
Feb 06, 2025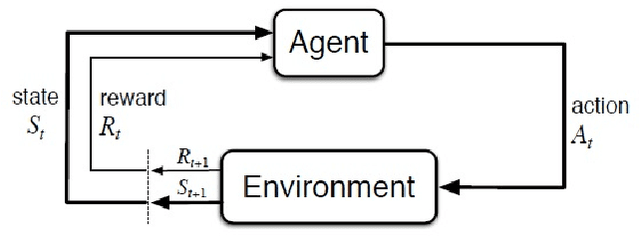
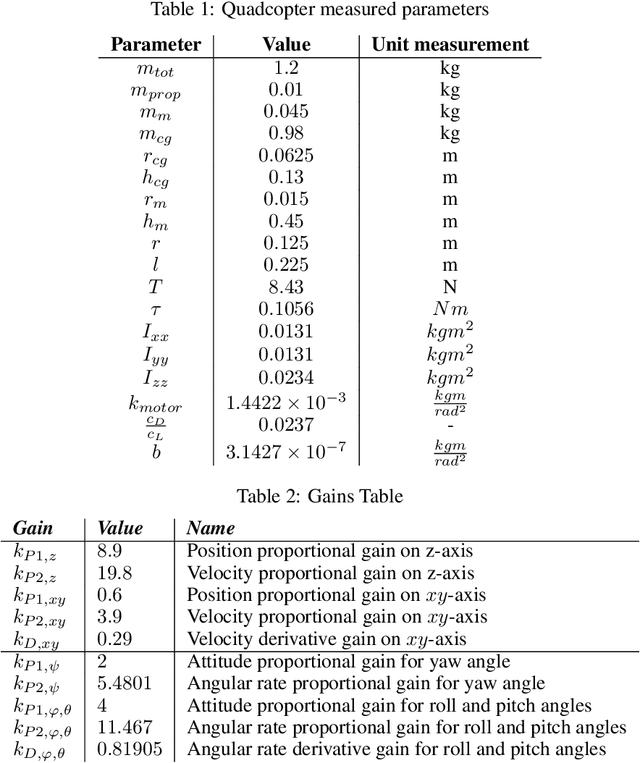
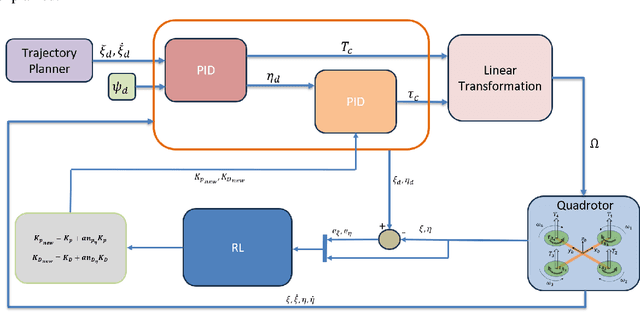

A reinforcement learning (RL) based methodology is proposed and implemented for online fine-tuning of PID controller gains, thus, improving quadrotor effective and accurate trajectory tracking. The RL agent is first trained offline on a quadrotor PID attitude controller and then validated through simulations and experimental flights. RL exploits a Deep Deterministic Policy Gradient (DDPG) algorithm, which is an off-policy actor-critic method. Training and simulation studies are performed using Matlab/Simulink and the UAV Toolbox Support Package for PX4 Autopilots. Performance evaluation and comparison studies are performed between the hand-tuned and RL-based tuned approaches. The results show that the controller parameters based on RL are adjusted during flights, achieving the smallest attitude errors, thus significantly improving attitude tracking performance compared to the hand-tuned approach.