 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtist-driven layering and user's behaviour impact on recommendations in a playlist continuation scenario
Oct 13, 2020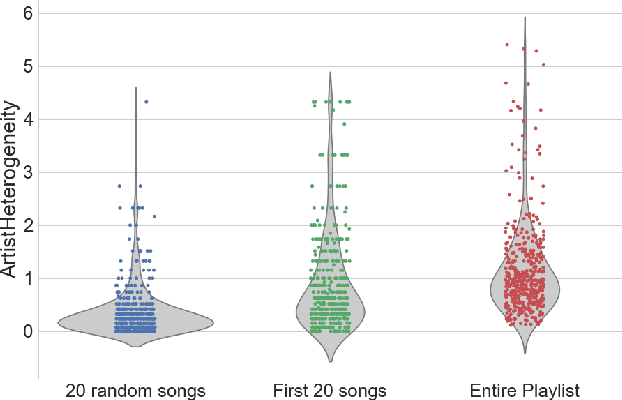
In this paper we provide an overview of the approach we used as team Creamy Fireflies for the ACM RecSys Challenge 2018. The competition, organized by Spotify, focuses on the problem of playlist continuation, that is suggesting which tracks the user may add to an existing playlist. The challenge addresses this issue in many use cases, from playlist cold start to playlists already composed by up to a hundred tracks. Our team proposes a solution based on a few well known models both content based and collaborative, whose predictions are aggregated via an ensembling step. Moreover by analyzing the underlying structure of the data, we propose a series of boosts to be applied on top of the final predictions and improve the recommendation quality. The proposed approach leverages well-known algorithms and is able to offer a high recommendation quality while requiring a limited amount of computational resources.
* Source code available here: https://github.com/MaurizioFD/spotify-recsys-challenge
A Troubling Analysis of Reproducibility and Progress in Recommender Systems Research
Nov 18, 2019
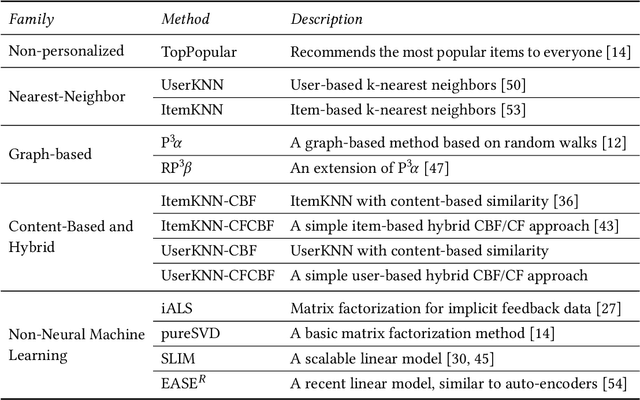

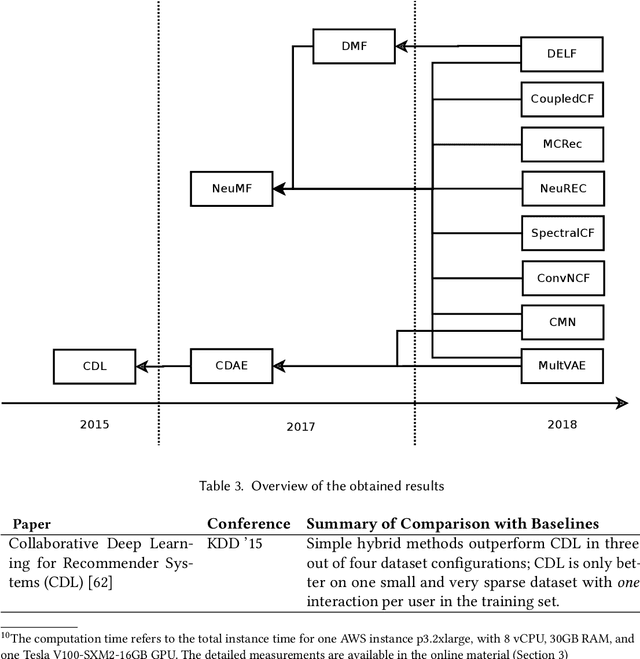
The design of algorithms that generate personalized ranked item lists is a central topic of research in the field of recommender systems. In the past few years, in particular, approaches based on deep learning (neural) techniques have become dominant in the literature. For all of them, substantial progress over the state-of-the-art is claimed. However, indications exist of certain problems in today's research practice, e.g., with respect to the choice and optimization of the baselines used for comparison, raising questions about the published claims. In order to obtain a better understanding of the actual progress, we have tried to reproduce recent results in the area of neural recommendation approaches based on collaborative filtering. The worrying outcome of the analysis of these recent works-all were published at prestigious scientific conferences between 2015 and 2018-is that 11 out of the 12 reproducible neural approaches can be outperformed by conceptually simple methods, e.g., based on the nearest-neighbor heuristics. None of the computationally complex neural methods was actually consistently better than already existing learning-based techniques, e.g., using matrix factorization or linear models. In our analysis, we discuss common issues in today's research practice, which, despite the many papers that are published on the topic, have apparently led the field to a certain level of stagnation.