 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Context-Based Meta-Reinforcement Learning with Self-Supervised Trajectory Contrastive Learning
Mar 10, 2021
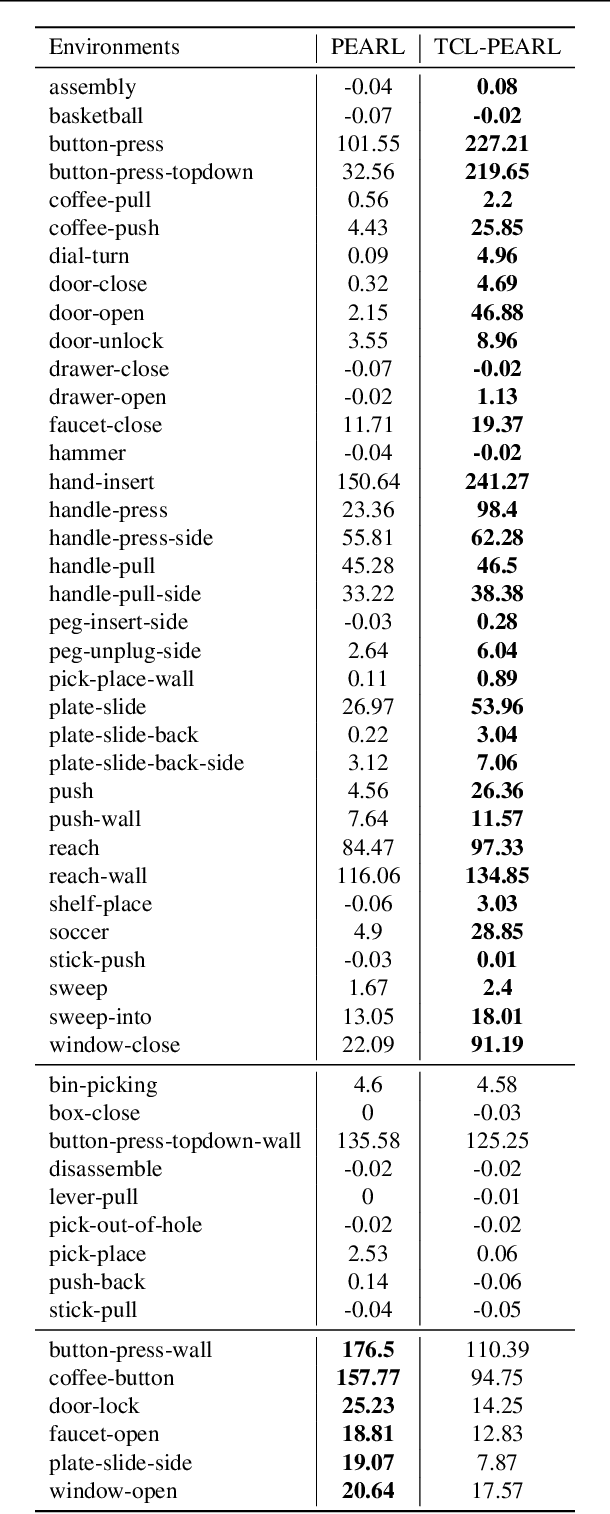
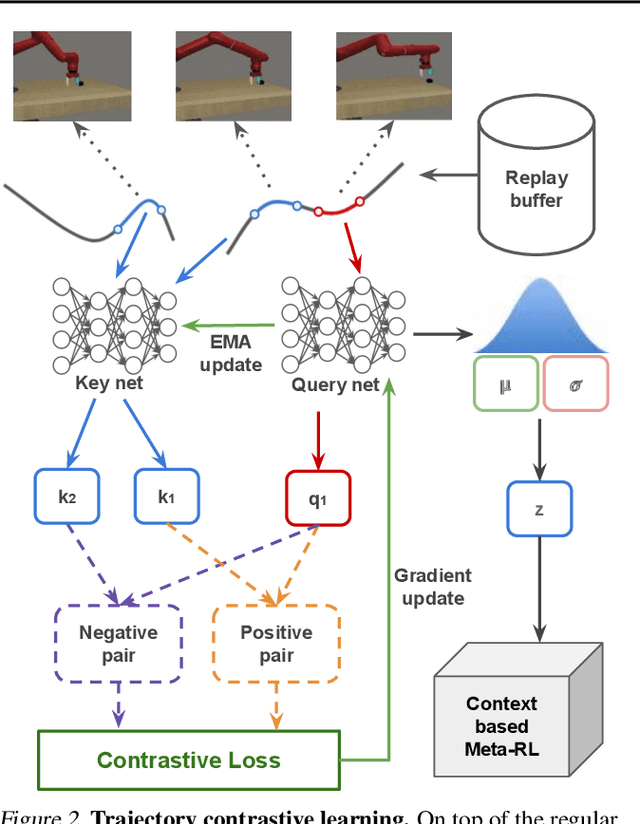

Meta-reinforcement learning typically requires orders of magnitude more samples than single task reinforcement learning methods. This is because meta-training needs to deal with more diverse distributions and train extra components such as context encoders. To address this, we propose a novel self-supervised learning task, which we named Trajectory Contrastive Learning (TCL), to improve meta-training. TCL adopts contrastive learning and trains a context encoder to predict whether two transition windows are sampled from the same trajectory. TCL leverages the natural hierarchical structure of context-based meta-RL and makes minimal assumptions, allowing it to be generally applicable to context-based meta-RL algorithms. It accelerates the training of context encoders and improves meta-training overall. Experiments show that TCL performs better or comparably than a strong meta-RL baseline in most of the environments on both meta-RL MuJoCo (5 of 6) and Meta-World benchmarks (44 out of 50).