 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFTerViT: Fully Ternary Vision Transformer
May 20, 2026Ternary Vision Transformers offer substantial model compression, however state-of-the-art methods only ternarize the encoder layers, leaving patch embeddings, LayerNorm parameters, and classifier heads in full precision. In compact models targeting resource-constrained processors, such as microcontrollers, these remaining full-precision components determine the total memory footprint, severely limiting deployment efficiency and on-device feasibility. In this work, we introduce a fully ternarized Vision Transformer in which \emph{all} weight matrices and normalization parameters are ternarized (FTerViT). To this end, we introduce two novel operators : TernaryBitConv2d with per-channel scaling for patch embedding and TernaryLayerNorm. FTerViT is trained using knowledge distillation, followed by a lightweight quantization-aware recovery phase. Our ternary W2A8 DeiT-III-S at 384$\times$384 resolution achieves 82.43\% ImageNet-1K top-1 at 6.09\,MB (${\sim}$15$\times$ compression, $-$2.42\,pp vs.\ FP32), outperforming prior ternary ViTs methods up to 8 pp. Finally, we demonstrate the first implementation of ternary vision transformers on a dual cores XTensa LX7 microcontroller inside the ESP32-S3 system-on-chip. By deploying FTerViT-Small (based on DeiT-III-Small at 224$\times$224 resolution, 5.81\,MB), we achieve 79.64\% ImageNet-1K top-1 accuracy.
Adaptation of MobileNetV2 for Face Detection on Ultra-Low Power Platform
Aug 23, 2022
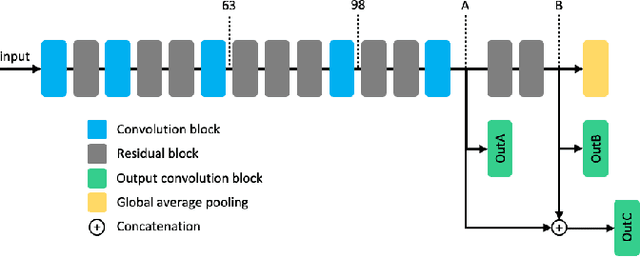

Designing Deep Neural Networks (DNNs) running on edge hardware remains a challenge. Standard designs have been adopted by the community to facilitate the deployment of Neural Network models. However, not much emphasis is put on adapting the network topology to fit hardware constraints. In this paper, we adapt one of the most widely used architectures for mobile hardware platforms, MobileNetV2, and study the impact of changing its topology and applying post-training quantization. We discuss the impact of the adaptations and the deployment of the model on an embedded hardware platform for face detection.
Optimizing the Consumption of Spiking Neural Networks with Activity Regularization
Apr 04, 2022
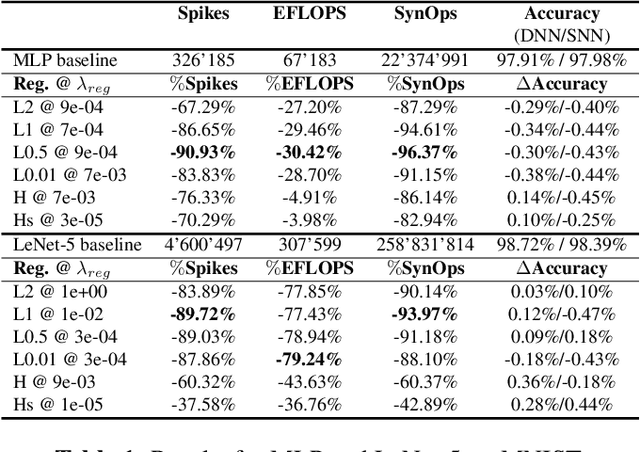
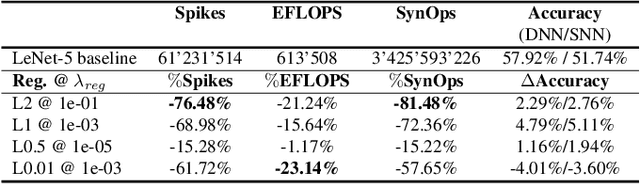
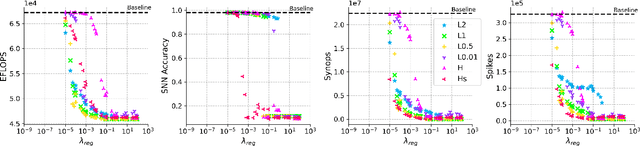
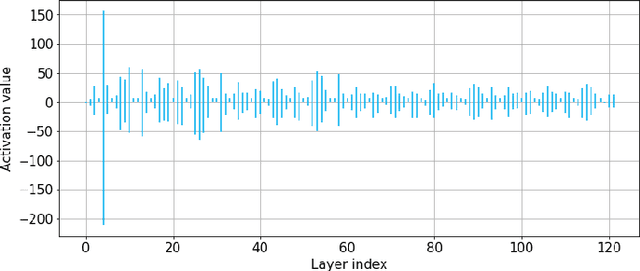
Reducing energy consumption is a critical point for neural network models running on edge devices. In this regard, reducing the number of multiply-accumulate (MAC) operations of Deep Neural Networks (DNNs) running on edge hardware accelerators will reduce the energy consumption during inference. Spiking Neural Networks (SNNs) are an example of bio-inspired techniques that can further save energy by using binary activations, and avoid consuming energy when not spiking. The networks can be configured for equivalent accuracy on a task through DNN-to-SNN conversion frameworks but their conversion is based on rate coding therefore the synaptic operations can be high. In this work, we look into different techniques to enforce sparsity on the neural network activation maps and compare the effect of different training regularizers on the efficiency of the optimized DNNs and SNNs.