 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFiltered Fictitious Play for Perturbed Observation Potential Games and Decentralised POMDPs
Feb 14, 2012
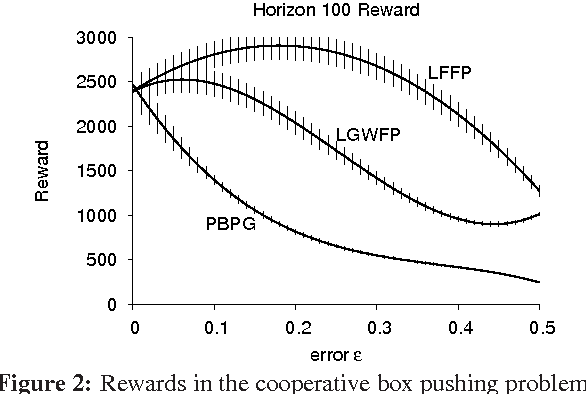
Potential games and decentralised partially observable MDPs (Dec-POMDPs) are two commonly used models of multi-agent interaction, for static optimisation and sequential decisionmaking settings, respectively. In this paper we introduce filtered fictitious play for solving repeated potential games in which each player's observations of others' actions are perturbed by random noise, and use this algorithm to construct an online learning method for solving Dec-POMDPs. Specifically, we prove that noise in observations prevents standard fictitious play from converging to Nash equilibrium in potential games, which also makes fictitious play impractical for solving Dec-POMDPs. To combat this, we derive filtered fictitious play, and provide conditions under which it converges to a Nash equilibrium in potential games with noisy observations. We then use filtered fictitious play to construct a solver for Dec-POMDPs, and demonstrate our new algorithm's performance in a box pushing problem. Our results show that we consistently outperform the state-of-the-art Dec-POMDP solver by an average of 100% across the range of noise in the observation function.