 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Sampling for Fairness Testing in Deep Neural Network
Mar 06, 2023

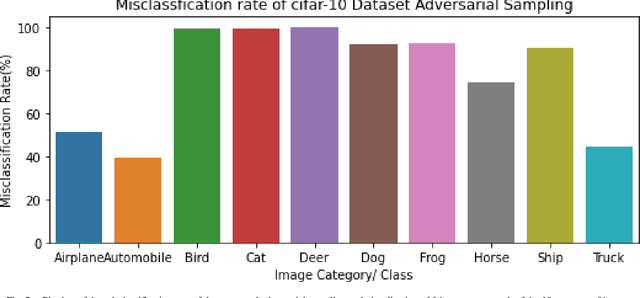
In this research, we focus on the usage of adversarial sampling to test for the fairness in the prediction of deep neural network model across different classes of image in a given dataset. While several framework had been proposed to ensure robustness of machine learning model against adversarial attack, some of which includes adversarial training algorithm. There is still the pitfall that adversarial training algorithm tends to cause disparity in accuracy and robustness among different group. Our research is aimed at using adversarial sampling to test for fairness in the prediction of deep neural network model across different classes or categories of image in a given dataset. We successfully demonstrated a new method of ensuring fairness across various group of input in deep neural network classifier. We trained our neural network model on the original image, and without training our model on the perturbed or attacked image. When we feed the adversarial samplings to our model, it was able to predict the original category/ class of the image the adversarial sample belongs to. We also introduced and used the separation of concern concept from software engineering whereby there is an additional standalone filter layer that filters perturbed image by heavily removing the noise or attack before automatically passing it to the network for classification, we were able to have accuracy of 93.3%. Cifar-10 dataset have ten categories of dataset, and so, in order to account for fairness, we applied our hypothesis across each categories of dataset and were able to get a consistent result and accuracy.
* 7 pages, 5 figures, International Journal of Advanced Computer Science and Application
AI Powered Anti-Cyber Bullying System using Machine Learning Algorithm of Multinomial Naive Bayes and Optimized Linear Support Vector Machine
Jul 25, 2022



"Unless and until our society recognizes cyber bullying for what it is, the suffering of thousands of silent victims will continue." ~ Anna Maria Chavez. There had been series of research on cyber bullying which are unable to provide reliable solution to cyber bullying. In this research work, we were able to provide a permanent solution to this by developing a model capable of detecting and intercepting bullying incoming and outgoing messages with 92% accuracy. We also developed a chatbot automation messaging system to test our model leading to the development of Artificial Intelligence powered anti-cyber bullying system using machine learning algorithm of Multinomial Naive Bayes (MNB) and optimized linear Support Vector Machine (SVM). Our model is able to detect and intercept bullying outgoing and incoming bullying messages and take immediate action.
* 5 pages