 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Tail Neural Network for Realtime Custom Keyword Spotting
May 24, 2022
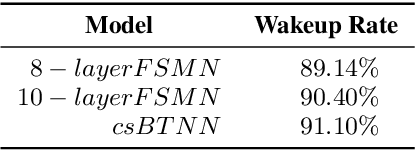
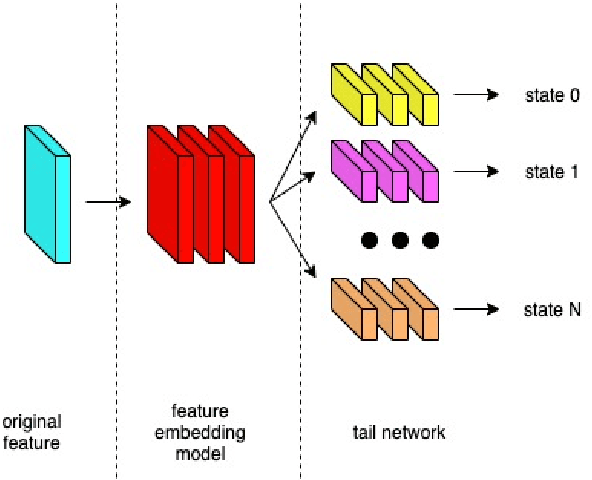
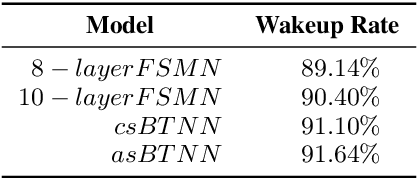
In this paper, we propose a Boosting Tail Neural Network (BTNN) for improving the performance of Realtime Custom Keyword Spotting (RCKS) that is still an industrial challenge for demanding powerful classification ability with limited computation resources. Inspired by Brain Science that a brain is only partly activated for a nerve simulation and numerous machine learning algorithms are developed to use a batch of weak classifiers to resolve arduous problems, which are often proved to be effective. We show that this method is helpful to the RCKS problem. The proposed approach achieve better performances in terms of wakeup rate and false alarm. In our experiments compared with those traditional algorithms that use only one strong classifier, it gets 18\% relative improvement. We also point out that this approach may be promising in future ASR exploration.
Hierarchical Neural Network Architecture In Keyword Spotting
Nov 06, 2018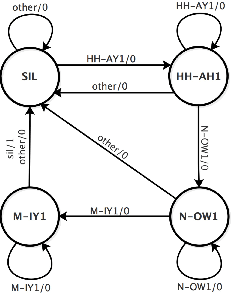
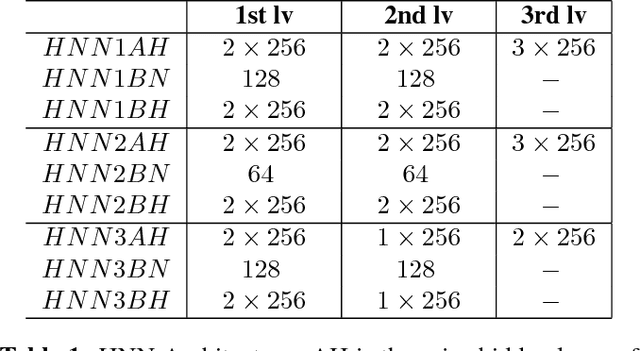
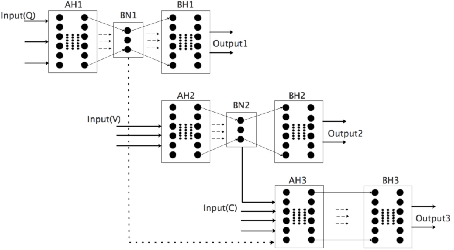
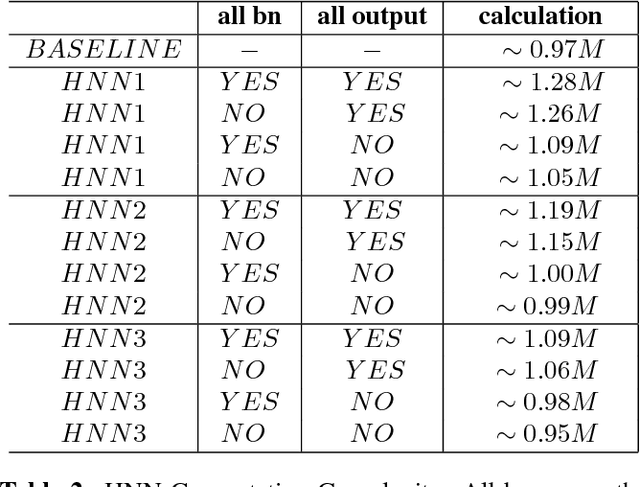
Keyword Spotting (KWS) provides the start signal of ASR problem, and thus it is essential to ensure a high recall rate. However, its real-time property requires low computation complexity. This contradiction inspires people to find a suitable model which is small enough to perform well in multi environments. To deal with this contradiction, we implement the Hierarchical Neural Network(HNN), which is proved to be effective in many speech recognition problems. HNN outperforms traditional DNN and CNN even though its model size and computation complexity are slightly less. Also, its simple topology structure makes easy to deploy on any device.
Weight-importance sparse training in keyword spotting
Jul 09, 2018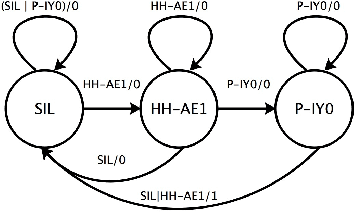
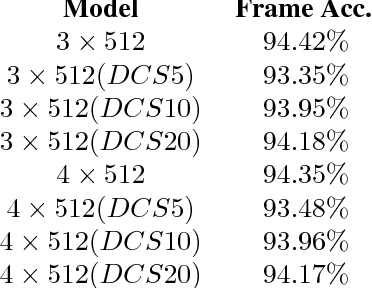
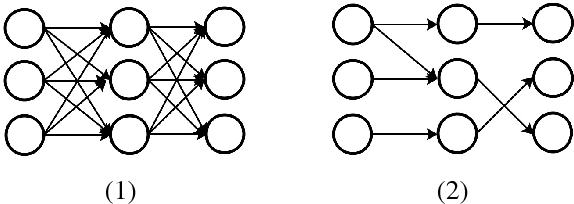
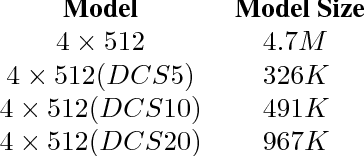
Large size models are implemented in recently ASR system to deal with complex speech recognition problems. The num- ber of parameters in these models makes them hard to deploy, especially on some resource-short devices such as car tablet. Besides this, at most of time, ASR system is used to deal with real-time problem such as keyword spotting (KWS). It is contradictory to the fact that large model requires long com- putation time. To deal with this problem, we apply some sparse algo- rithms to reduces number of parameters in some widely used models, Deep Neural Network (DNN) KWS, which requires real short computation time. We can prune more than 90 % even 95% of parameters in the model with tiny effect decline. And the sparse model performs better than baseline models which has same order number of parameters. Besides this, sparse algorithm can lead us to find rational model size au- tomatically for certain problem without concerning choosing an original model size.