 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Network Design for Face Video Super-resolution
Sep 28, 2021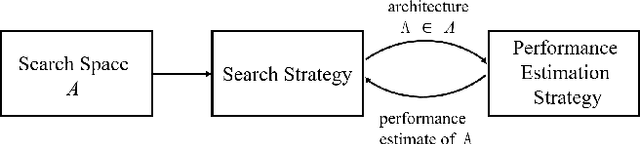
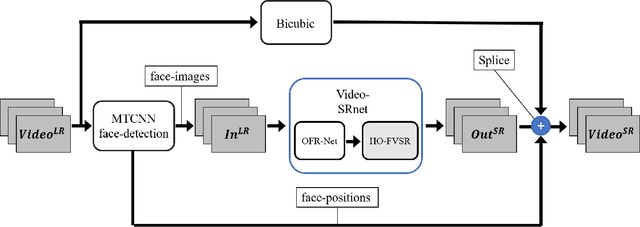
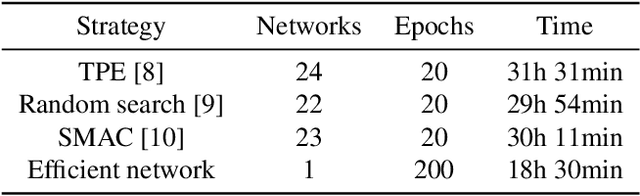
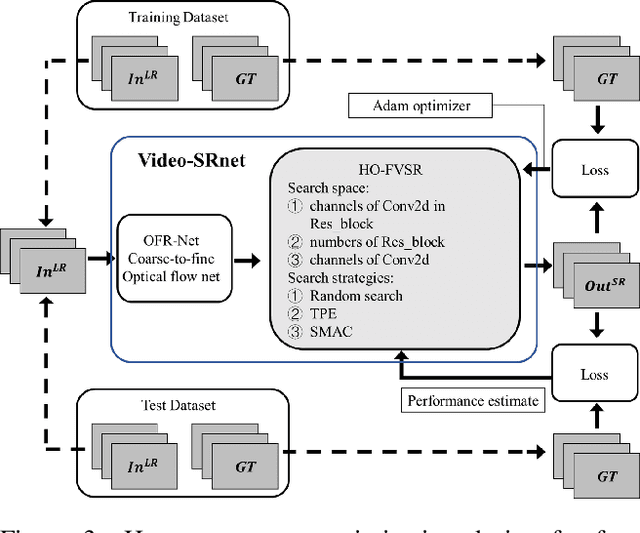
Face video super-resolution algorithm aims to reconstruct realistic face details through continuous input video sequences. However, existing video processing algorithms usually contain redundant parameters to guarantee different super-resolution scenes. In this work, we focus on super-resolution of face areas in original video scenes, while rest areas are interpolated. This specific super-resolved task makes it possible to cut redundant parameters in general video super-resolution networks. We construct a dataset consisting entirely of face video sequences for network training and evaluation, and conduct hyper-parameter optimization in our experiments. We use three combined strategies to optimize the network parameters with a simultaneous train-evaluation method to accelerate optimization process. Results show that simultaneous train-evaluation method improves the training speed and facilitates the generation of efficient networks. The generated network can reduce at least 52.4% parameters and 20.7% FLOPs, achieve better performance on PSNR, SSIM compared with state-of-art video super-resolution algorithms. When processing 36x36x1x3 input video frame sequences, the efficient network provides 47.62 FPS real-time processing performance. We name our proposal as hyper-parameter optimization for face Video Super-Resolution (HO-FVSR), which is open-sourced at https://github.com/yphone/efficient-network-for-face-VSR.