 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Natural Language Processing to Screen Patients with Active Heart Failure: An Exploration for Hospital-wide Surveillance
Sep 06, 2016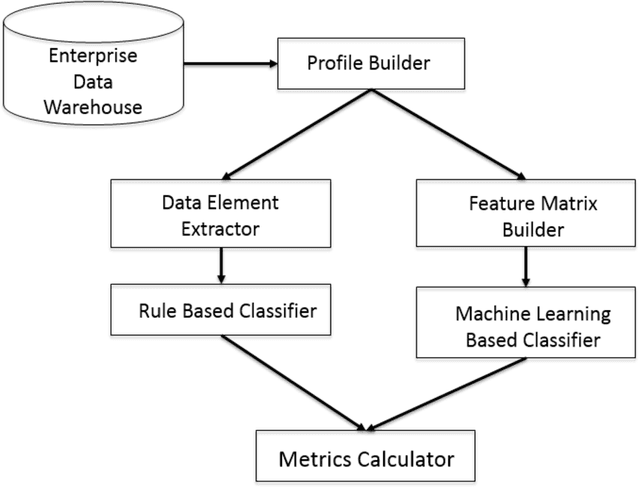
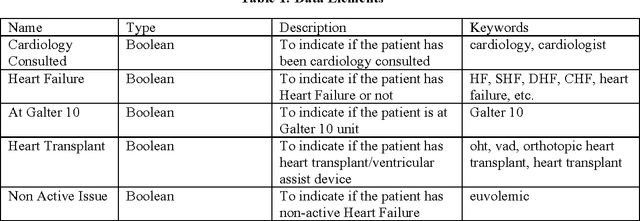
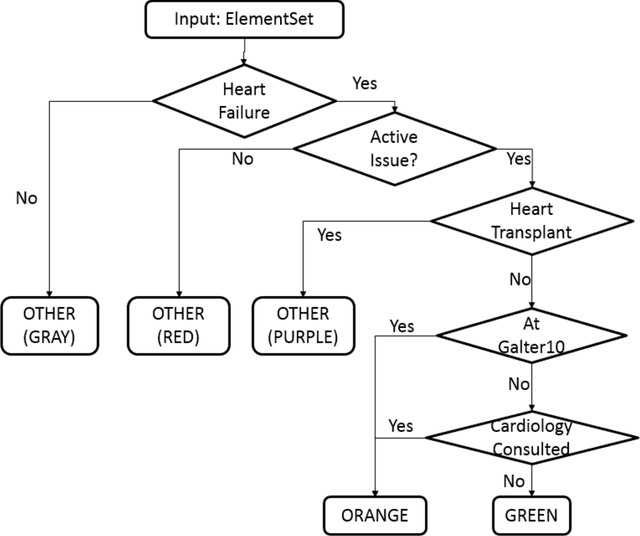
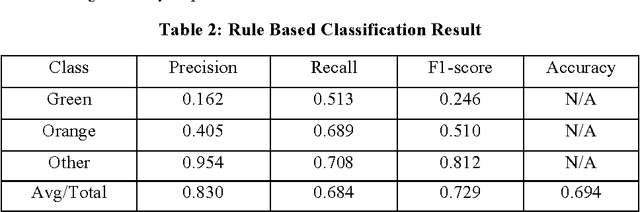
In this paper, we proposed two different approaches, a rule-based approach and a machine-learning based approach, to identify active heart failure cases automatically by analyzing electronic health records (EHR). For the rule-based approach, we extracted cardiovascular data elements from clinical notes and matched patients to different colors according their heart failure condition by using rules provided by experts in heart failure. It achieved 69.4% accuracy and 0.729 F1-Score. For the machine learning approach, with bigram of clinical notes as features, we tried four different models while SVM with linear kernel achieved the best performance with 87.5% accuracy and 0.86 F1-Score. Also, from the classification comparison between the four different models, we believe that linear models fit better for this problem. Once we combine the machine-learning and rule-based algorithms, we will enable hospital-wide surveillance of active heart failure through increased accuracy and interpretability of the outputs.
An Effective Approach to Biomedical Information Extraction with Limited Training Data
Sep 12, 2011Overall, the two main contributions of this work include the application of sentence simplification to association extraction as described above, and the use of distributional semantics for concept extraction. The proposed work on concept extraction amalgamates for the first time two diverse research areas -distributional semantics and information extraction. This approach renders all the advantages offered in other semi-supervised machine learning systems, and, unlike other proposed semi-supervised approaches, it can be used on top of different basic frameworks and algorithms. http://gradworks.umi.com/34/49/3449837.html
* This paper has been withdrawn
BioSimplify: an open source sentence simplification engine to improve recall in automatic biomedical information extraction
Jul 28, 2011
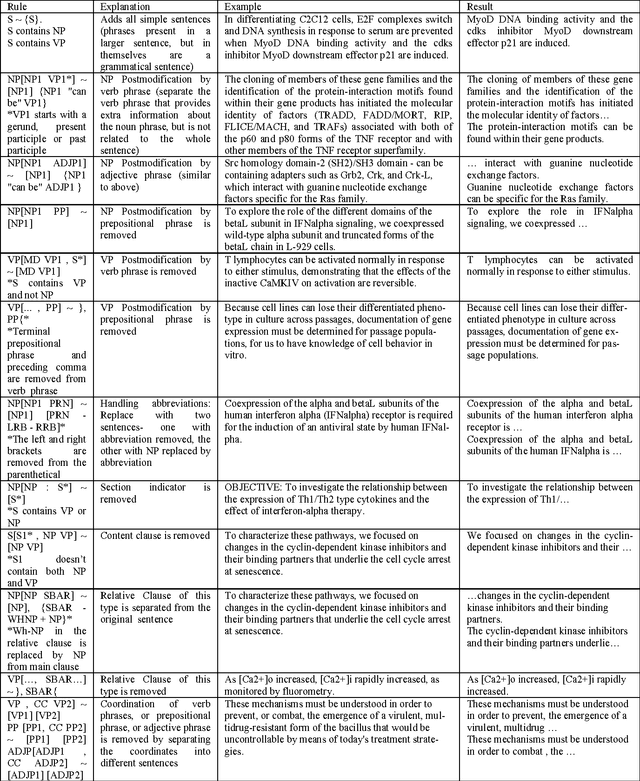

BioSimplify is an open source tool written in Java that introduces and facilitates the use of a novel model for sentence simplification tuned for automatic discourse analysis and information extraction (as opposed to sentence simplification for improving human readability). The model is based on a "shot-gun" approach that produces many different (simpler) versions of the original sentence by combining variants of its constituent elements. This tool is optimized for processing biomedical scientific literature such as the abstracts indexed in PubMed. We tested our tool on its impact to the task of PPI extraction and it improved the f-score of the PPI tool by around 7%, with an improvement in recall of around 20%. The BioSimplify tool and test corpus can be downloaded from https://biosimplify.sourceforge.net.
NEMO: Extraction and normalization of organization names from PubMed affiliation strings
Jul 28, 2011We propose NEMO, a system for extracting organization names in the affiliation and normalizing them to a canonical organization name. Our parsing process involves multi-layered rule matching with multiple dictionaries. The system achieves more than 98% f-score in extracting organization names. Our process of normalization that involves clustering based on local sequence alignment metrics and local learning based on finding connected components. A high precision was also observed in normalization. NEMO is the missing link in associating each biomedical paper and its authors to an organization name in its canonical form and the Geopolitical location of the organization. This research could potentially help in analyzing large social networks of organizations for landscaping a particular topic, improving performance of author disambiguation, adding weak links in the co-author network of authors, augmenting NLM's MARS system for correcting errors in OCR output of affiliation field, and automatically indexing the PubMed citations with the normalized organization name and country. Our system is available as a graphical user interface available for download along with this paper.
Towards Effective Sentence Simplification for Automatic Processing of Biomedical Text
Jan 24, 2010


The complexity of sentences characteristic to biomedical articles poses a challenge to natural language parsers, which are typically trained on large-scale corpora of non-technical text. We propose a text simplification process, bioSimplify, that seeks to reduce the complexity of sentences in biomedical abstracts in order to improve the performance of syntactic parsers on the processed sentences. Syntactic parsing is typically one of the first steps in a text mining pipeline. Thus, any improvement in performance would have a ripple effect over all processing steps. We evaluated our method using a corpus of biomedical sentences annotated with syntactic links. Our empirical results show an improvement of 2.90% for the Charniak-McClosky parser and of 4.23% for the Link Grammar parser when processing simplified sentences rather than the original sentences in the corpus.
* 4 pages, In Proc. of the NAACL-HLT 2009, Boulder, USA, June
Sentence Simplification Aids Protein-Protein Interaction Extraction
Jan 24, 2010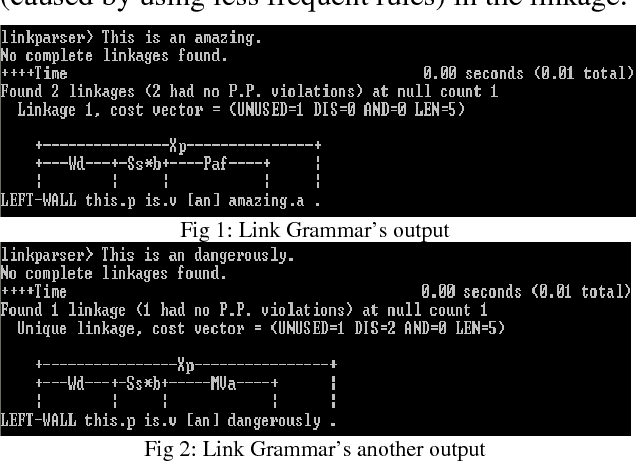

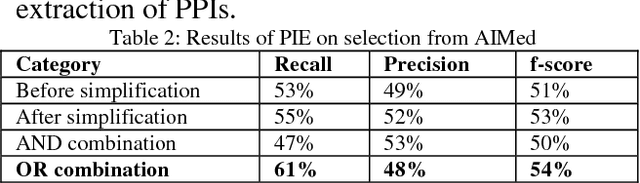
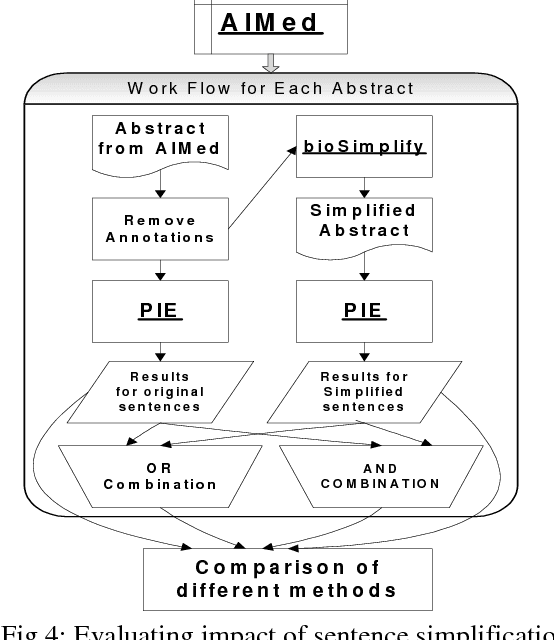
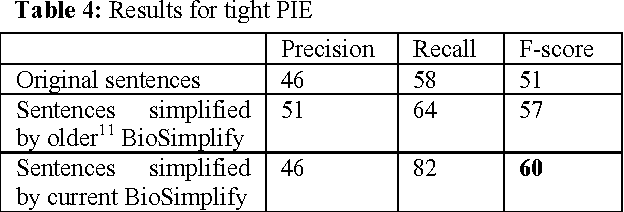
Accurate systems for extracting Protein-Protein Interactions (PPIs) automatically from biomedical articles can help accelerate biomedical research. Biomedical Informatics researchers are collaborating to provide metaservices and advance the state-of-art in PPI extraction. One problem often neglected by current Natural Language Processing systems is the characteristic complexity of the sentences in biomedical literature. In this paper, we report on the impact that automatic simplification of sentences has on the performance of a state-of-art PPI extraction system, showing a substantial improvement in recall (8%) when the sentence simplification method is applied, without significant impact to precision.
* 6 pages, The 3rd International Symposium on Languages in Biology and Medicine, Jeju Island, South Korea, November 8-10, 2009