 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistIR: An Intermediate Representation and Simulator for Efficient Neural Network Distribution
Nov 09, 2021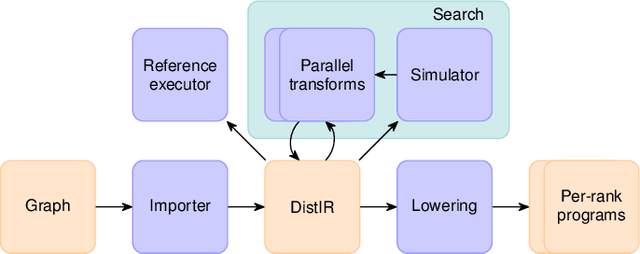
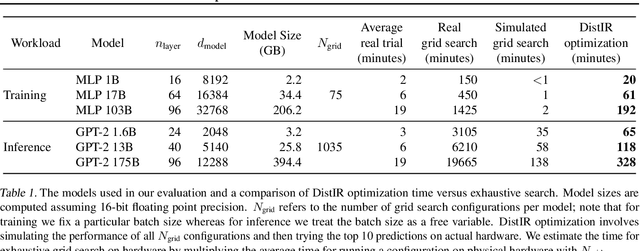

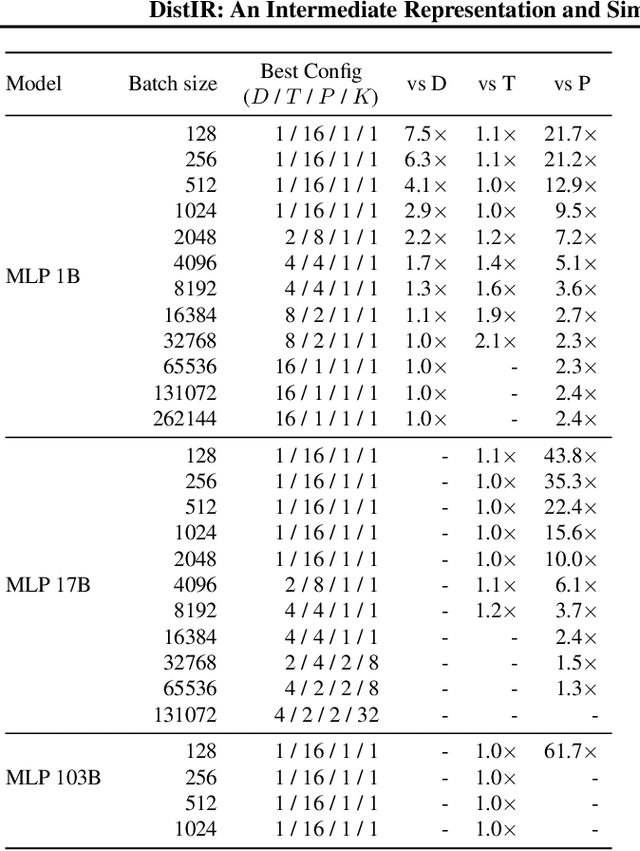
The rapidly growing size of deep neural network (DNN) models and datasets has given rise to a variety of distribution strategies such as data, tensor-model, pipeline parallelism, and hybrid combinations thereof. Each of these strategies offers its own trade-offs and exhibits optimal performance across different models and hardware topologies. Selecting the best set of strategies for a given setup is challenging because the search space grows combinatorially, and debugging and testing on clusters is expensive. In this work we propose DistIR, an expressive intermediate representation for distributed DNN computation that is tailored for efficient analyses, such as simulation. This enables automatically identifying the top-performing strategies without having to execute on physical hardware. Unlike prior work, DistIR can naturally express many distribution strategies including pipeline parallelism with arbitrary schedules. Our evaluation on MLP training and GPT-2 inference models demonstrates how DistIR and its simulator enable fast grid searches over complex distribution spaces spanning up to 1000+ configurations, reducing optimization time by an order of magnitude for certain regimes.
Learning Invariants using Decision Trees
Jan 20, 2015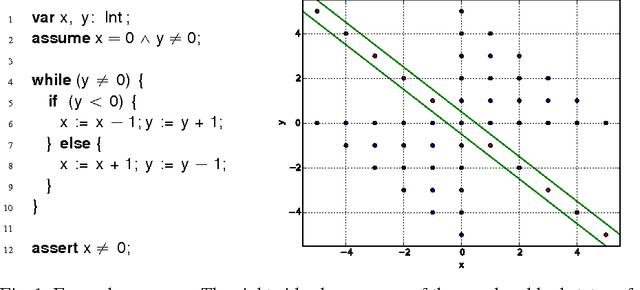
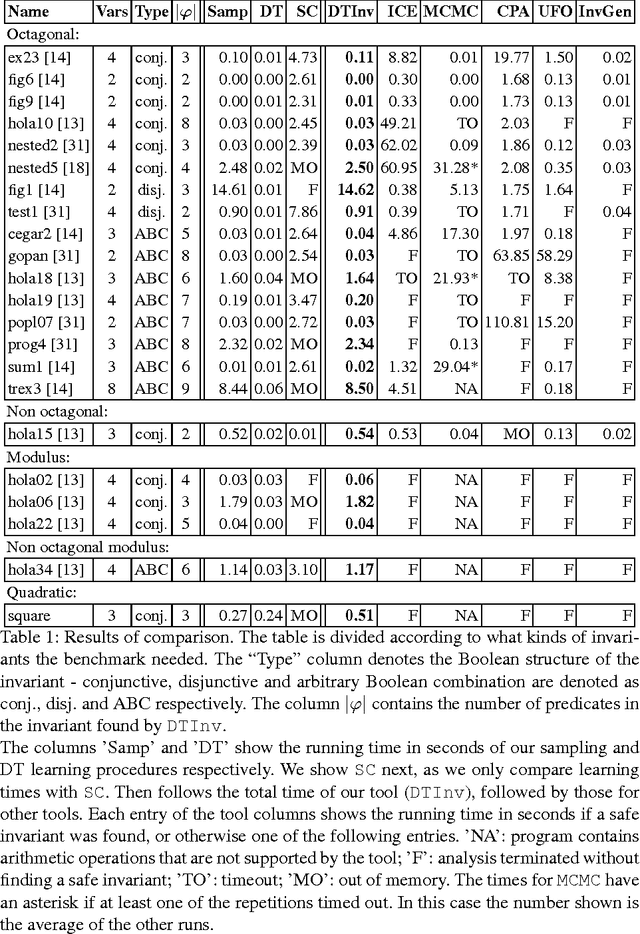
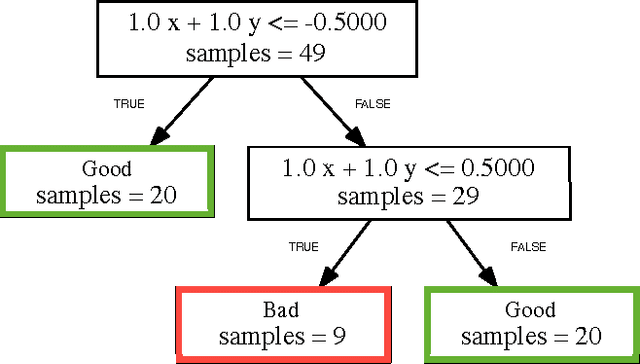
The problem of inferring an inductive invariant for verifying program safety can be formulated in terms of binary classification. This is a standard problem in machine learning: given a sample of good and bad points, one is asked to find a classifier that generalizes from the sample and separates the two sets. Here, the good points are the reachable states of the program, and the bad points are those that reach a safety property violation. Thus, a learned classifier is a candidate invariant. In this paper, we propose a new algorithm that uses decision trees to learn candidate invariants in the form of arbitrary Boolean combinations of numerical inequalities. We have used our algorithm to verify C programs taken from the literature. The algorithm is able to infer safe invariants for a range of challenging benchmarks and compares favorably to other ML-based invariant inference techniques. In particular, it scales well to large sample sets.