 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLandmark Enhanced Multimodal Graph Learning for Deepfake Video Detection
Sep 12, 2022
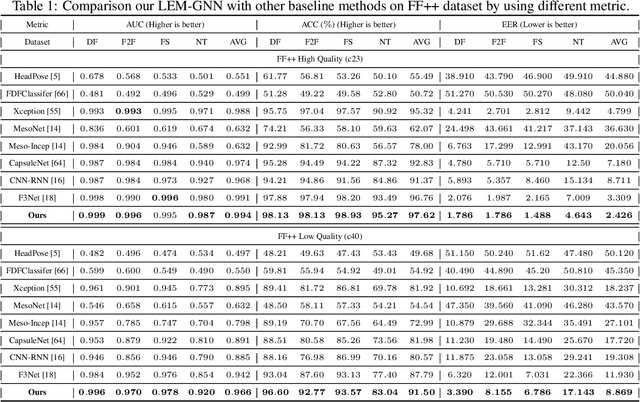
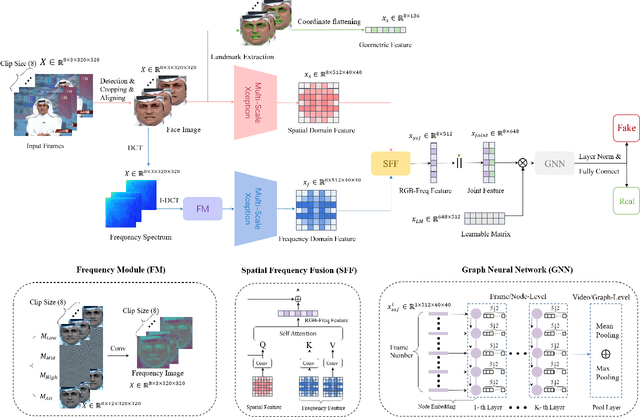
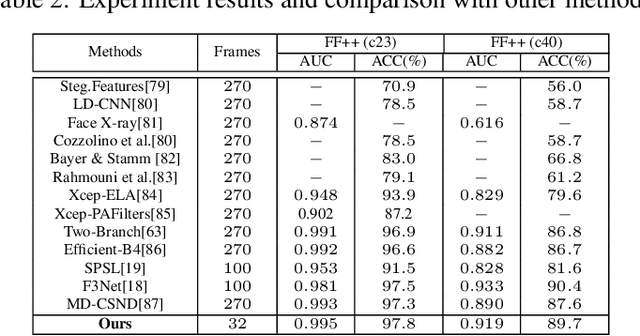
With the rapid development of face forgery technology, deepfake videos have attracted widespread attention in digital media. Perpetrators heavily utilize these videos to spread disinformation and make misleading statements. Most existing methods for deepfake detection mainly focus on texture features, which are likely to be impacted by external fluctuations, such as illumination and noise. Besides, detection methods based on facial landmarks are more robust against external variables but lack sufficient detail. Thus, how to effectively mine distinctive features in the spatial, temporal, and frequency domains and fuse them with facial landmarks for forgery video detection is still an open question. To this end, we propose a Landmark Enhanced Multimodal Graph Neural Network (LEM-GNN) based on multiple modalities' information and geometric features of facial landmarks. Specifically, at the frame level, we have designed a fusion mechanism to mine a joint representation of the spatial and frequency domain elements while introducing geometric facial features to enhance the robustness of the model. At the video level, we first regard each frame in a video as a node in a graph and encode temporal information into the edges of the graph. Then, by applying the message passing mechanism of the graph neural network (GNN), the multimodal feature will be effectively combined to obtain a comprehensive representation of the video forgery. Extensive experiments show that our method consistently outperforms the state-of-the-art (SOTA) on widely-used benchmarks.