 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA framework for dynamically training and adapting deep reinforcement learning models to different, low-compute, and continuously changing radiology deployment environments
Jun 08, 2023



While Deep Reinforcement Learning has been widely researched in medical imaging, the training and deployment of these models usually require powerful GPUs. Since imaging environments evolve rapidly and can be generated by edge devices, the algorithm is required to continually learn and adapt to changing environments, and adjust to low-compute devices. To this end, we developed three image coreset algorithms to compress and denoise medical images for selective experience replayed-based lifelong reinforcement learning. We implemented neighborhood averaging coreset, neighborhood sensitivity-based sampling coreset, and maximum entropy coreset on full-body DIXON water and DIXON fat MRI images. All three coresets produced 27x compression with excellent performance in localizing five anatomical landmarks: left knee, right trochanter, left kidney, spleen, and lung across both imaging environments. Maximum entropy coreset obtained the best performance of $11.97\pm 12.02$ average distance error, compared to the conventional lifelong learning framework's $19.24\pm 50.77$.
Multi-environment lifelong deep reinforcement learning for medical imaging
May 31, 2023Deep reinforcement learning(DRL) is increasingly being explored in medical imaging. However, the environments for medical imaging tasks are constantly evolving in terms of imaging orientations, imaging sequences, and pathologies. To that end, we developed a Lifelong DRL framework, SERIL to continually learn new tasks in changing imaging environments without catastrophic forgetting. SERIL was developed using selective experience replay based lifelong learning technique for the localization of five anatomical landmarks in brain MRI on a sequence of twenty-four different imaging environments. The performance of SERIL, when compared to two baseline setups: MERT(multi-environment-best-case) and SERT(single-environment-worst-case) demonstrated excellent performance with an average distance of $9.90\pm7.35$ pixels from the desired landmark across all 120 tasks, compared to $10.29\pm9.07$ for MERT and $36.37\pm22.41$ for SERT($p<0.05$), demonstrating the excellent potential for continuously learning multiple tasks across dynamically changing imaging environments.
Cross-Domain Federated Learning in Medical Imaging
Dec 18, 2021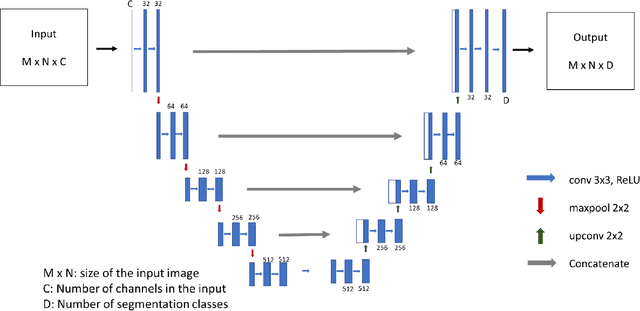
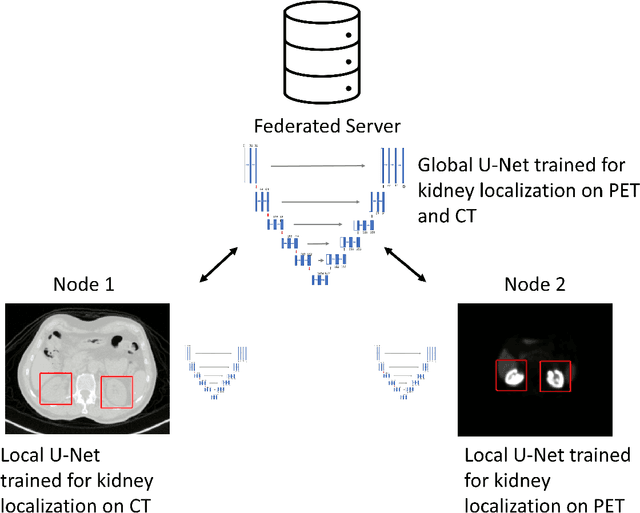
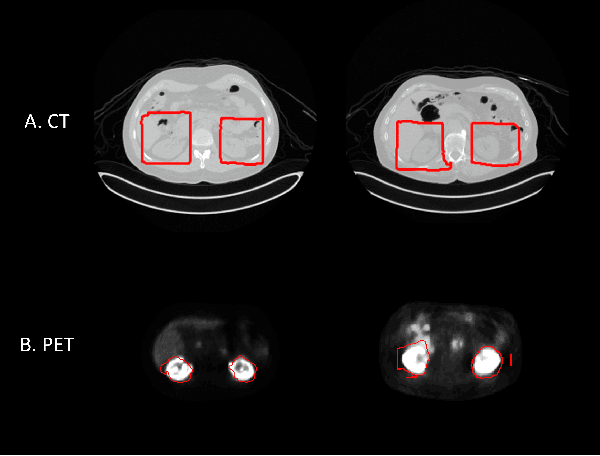
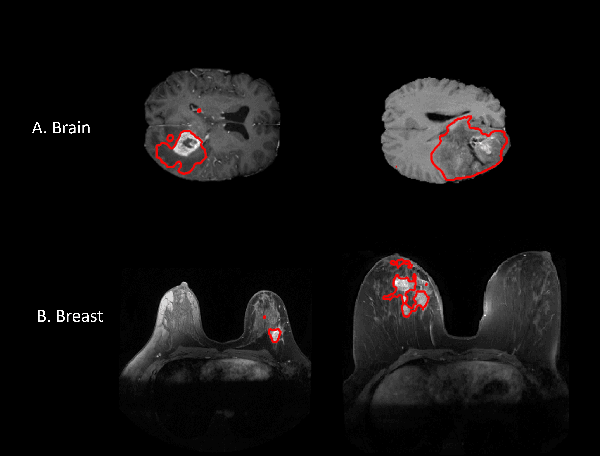
Federated learning is increasingly being explored in the field of medical imaging to train deep learning models on large scale datasets distributed across different data centers while preserving privacy by avoiding the need to transfer sensitive patient information. In this manuscript, we explore federated learning in a multi-domain, multi-task setting wherein different participating nodes may contain datasets sourced from different domains and are trained to solve different tasks. We evaluated cross-domain federated learning for the tasks of object detection and segmentation across two different experimental settings: multi-modal and multi-organ. The result from our experiments on cross-domain federated learning framework were very encouraging with an overlap similarity of 0.79 for organ localization and 0.65 for lesion segmentation. Our results demonstrate the potential of federated learning in developing multi-domain, multi-task deep learning models without sharing data from different domains.