 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXWSB: A Blend System Utilizing XLS-R and WavLM with SLS Classifier detection system for SVDD 2024 Challenge
Sep 27, 2024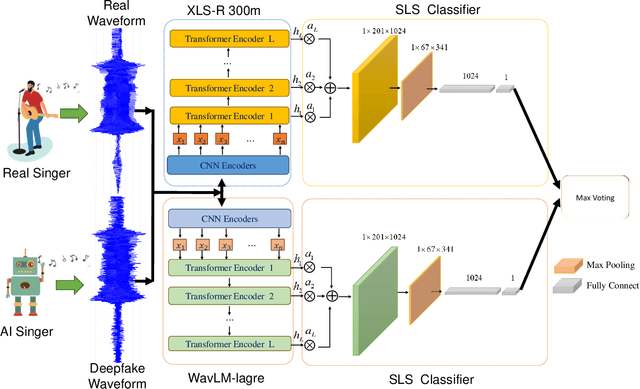
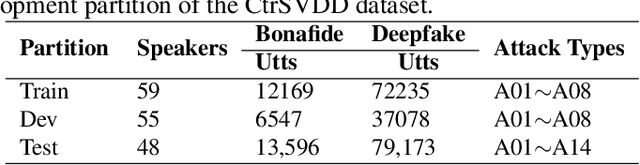
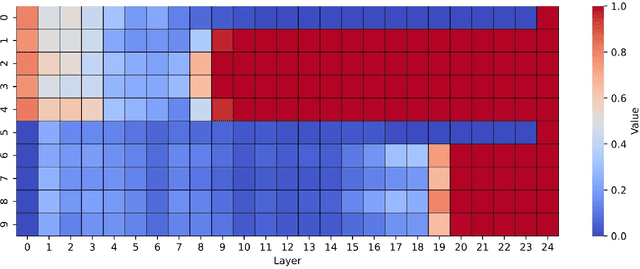
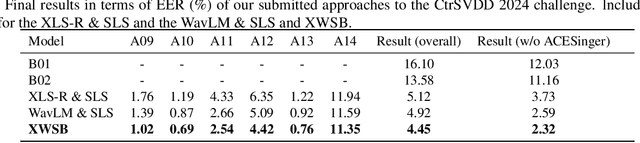
This paper introduces the model structure used in the SVDD 2024 Challenge. The SVDD 2024 challenge has been introduced this year for the first time. Singing voice deepfake detection (SVDD) which faces complexities due to informal speech intonations and varying speech rates. In this paper, we propose the XWSB system, which achieved SOTA per-formance in the SVDD challenge. XWSB stands for XLS-R, WavLM, and SLS Blend, representing the integration of these technologies for the purpose of SVDD. Specifically, we used the best performing model structure XLS-R&SLS from the ASVspoof DF dataset, and applied SLS to WavLM to form the WavLM&SLS structure. Finally, we integrated two models to form the XWSB system. Experimental results show that our system demonstrates advanced recognition capabilities in the SVDD challenge, specifically achieving an EER of 2.32% in the CtrSVDD track. The code and data can be found at https://github.com/QiShanZhang/XWSB_for_ SVDD2024.