 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoSPlan: Corrective Sequential Planning via Scene Graph Incremental Updates
Dec 11, 2025Large-scale Vision-Language Models (VLMs) exhibit impressive complex reasoning capabilities but remain largely unexplored in visual sequential planning, i.e., executing multi-step actions towards a goal. Additionally, practical sequential planning often involves non-optimal (erroneous) steps, challenging VLMs to detect and correct such steps. We propose Corrective Sequential Planning Benchmark (CoSPlan) to evaluate VLMs in error-prone, vision-based sequential planning tasks across 4 domains: maze navigation, block rearrangement, image reconstruction,and object reorganization. CoSPlan assesses two key abilities: Error Detection (identifying non-optimal action) and Step Completion (correcting and completing action sequences to reach the goal). Despite using state-of-the-art reasoning techniques such as Chain-of-Thought and Scene Graphs, VLMs (e.g. Intern-VLM and Qwen2) struggle on CoSPlan, failing to leverage contextual cues to reach goals. Addressing this, we propose a novel training-free method, Scene Graph Incremental updates (SGI), which introduces intermediate reasoning steps between the initial and goal states. SGI helps VLMs reason about sequences, yielding an average performance gain of 5.2%. In addition to enhancing reliability in corrective sequential planning, SGI generalizes to traditional planning tasks such as Plan-Bench and VQA.
Navigating Hallucinations for Reasoning of Unintentional Activities
Mar 03, 2024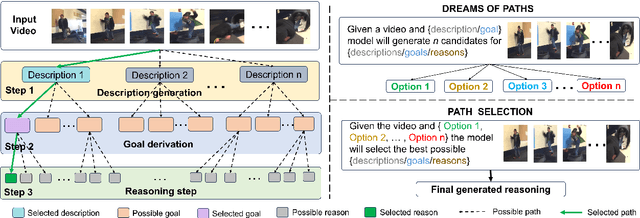


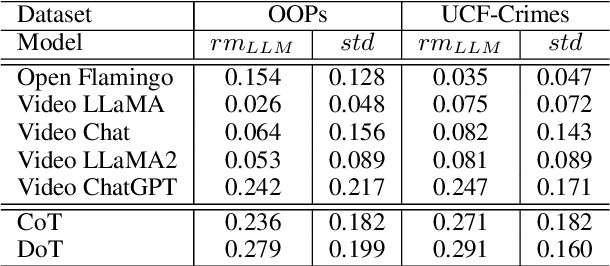
In this work we present a novel task of understanding unintentional human activities in videos. We formalize this problem as a reasoning task under zero-shot scenario, where given a video of an unintentional activity we want to know why it transitioned from intentional to unintentional. We first evaluate the effectiveness of current state-of-the-art Large Multimodal Models on this reasoning task and observe that they suffer from hallucination. We further propose a novel prompting technique,termed as Dream of Thoughts (DoT), which allows the model to navigate through hallucinated thoughts to achieve better reasoning. To evaluate the performance on this task, we also introduce three different specialized metrics designed to quantify the models reasoning capability. We perform our experiments on two different datasets, OOPs and UCF-Crimes, and our findings show that DOT prompting technique is able to outperform standard prompting, while minimizing hallucinations.