 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast-MIA: Efficient and Scalable Membership Inference for LLMs
Oct 27, 2025We propose Fast-MIA (https://github.com/Nikkei/fast-mia), a Python library for efficiently evaluating membership inference attacks (MIA) against Large Language Models (LLMs). MIA against LLMs has emerged as a crucial challenge due to growing concerns over copyright, security, and data privacy, and has attracted increasing research attention. However, the progress of this research is significantly hindered by two main obstacles: (1) the high computational cost of inference in LLMs, and (2) the lack of standardized and maintained implementations of MIA methods, which makes large-scale empirical comparison difficult. To address these challenges, our library provides fast batch inference and includes implementations of representative MIA methods under a unified evaluation framework. This library supports easy implementation of reproducible benchmarks with simple configuration and extensibility. We release Fast-MIA as an open-source (Apache License 2.0) tool to support scalable and transparent research on LLMs.
Quantifying Memorization of Domain-Specific Pre-trained Language Models using Japanese Newspaper and Paywalls
Apr 26, 2024


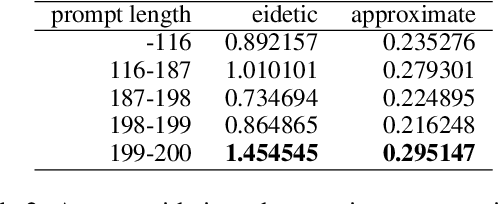
Dominant pre-trained language models (PLMs) have been successful in high-quality natural language generation. However, the analysis of their generation is not mature: do they acquire generalizable linguistic abstractions, or do they simply memorize and recover substrings of the training data? Especially, few studies focus on domain-specific PLM. In this study, we pre-trained domain-specific GPT-2 models using a limited corpus of Japanese newspaper articles and quantified memorization of training data by comparing them with general Japanese GPT-2 models. Our experiments revealed that domain-specific PLMs sometimes "copy and paste" on a large scale. Furthermore, we replicated the empirical finding that memorization is related to duplication, model size, and prompt length, in Japanese the same as in previous English studies. Our evaluations are relieved from data contamination concerns by focusing on newspaper paywalls, which prevent their use as training data. We hope that our paper encourages a sound discussion such as the security and copyright of PLMs.
Generating News-Centric Crossword Puzzles As A Constraint Satisfaction and Optimization Problem
Aug 09, 2023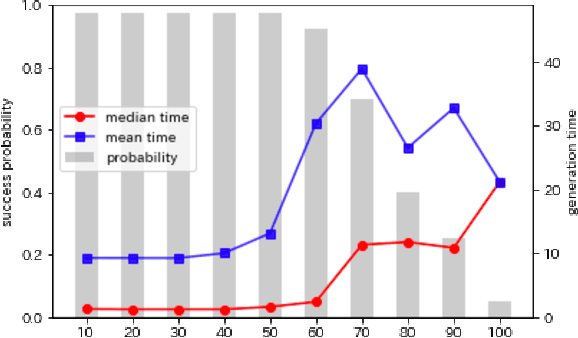
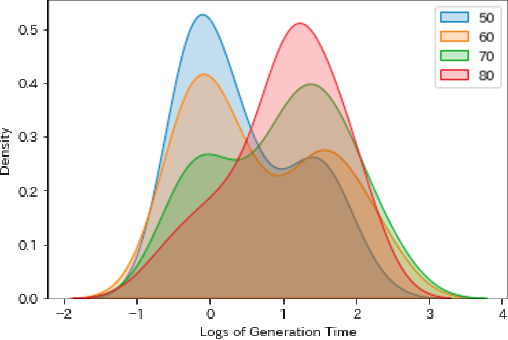
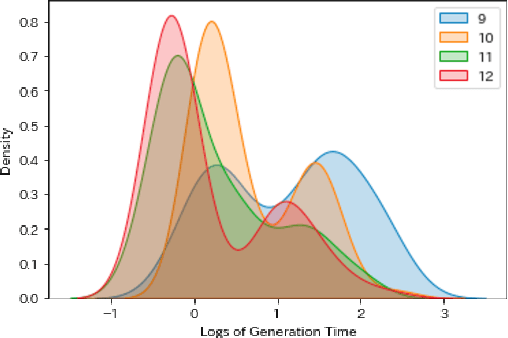
Crossword puzzles have traditionally served not only as entertainment but also as an educational tool that can be used to acquire vocabulary and language proficiency. One strategy to enhance the educational purpose is personalization, such as including more words on a particular topic. This paper focuses on the case of encouraging people's interest in news and proposes a framework for automatically generating news-centric crossword puzzles. We designed possible scenarios and built a prototype as a constraint satisfaction and optimization problem, that is, containing as many news-derived words as possible. Our experiments reported the generation probabilities and time required under several conditions. The results showed that news-centric crossword puzzles can be generated even with few news-derived words. We summarize the current issues and future research directions through a qualitative evaluation of the prototype. This is the first proposal that a formulation of a constraint satisfaction and optimization problem can be beneficial as an educational application.
Training Data Extraction From Pre-trained Language Models: A Survey
May 25, 2023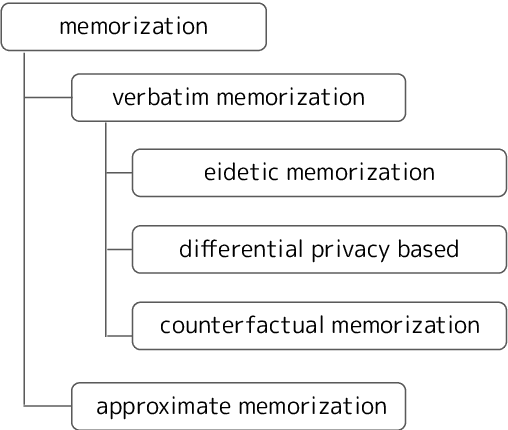
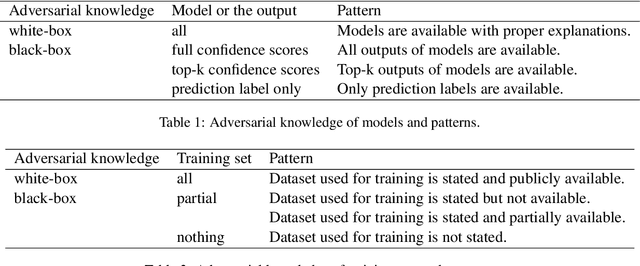
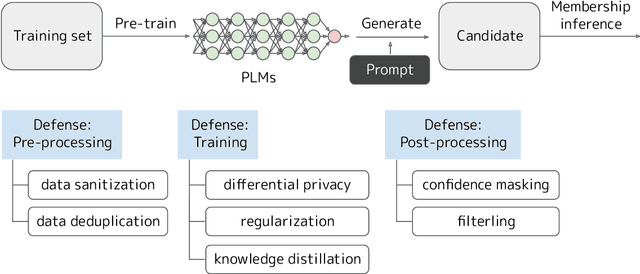
As the deployment of pre-trained language models (PLMs) expands, pressing security concerns have arisen regarding the potential for malicious extraction of training data, posing a threat to data privacy. This study is the first to provide a comprehensive survey of training data extraction from PLMs. Our review covers more than 100 key papers in fields such as natural language processing and security. First, preliminary knowledge is recapped and a taxonomy of various definitions of memorization is presented. The approaches for attack and defense are then systemized. Furthermore, the empirical findings of several quantitative studies are highlighted. Finally, future research directions based on this review are suggested.