 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBornon: Bengali Image Captioning with Transformer-based Deep learning approach
Sep 11, 2021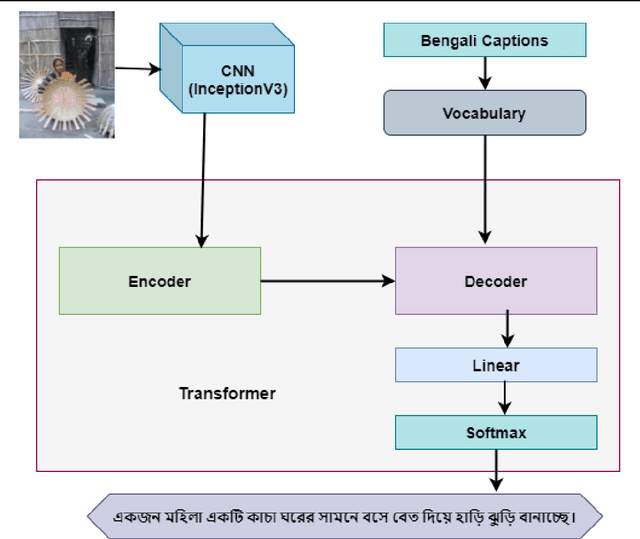

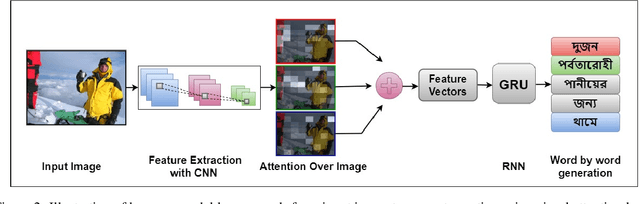

Image captioning using Encoder-Decoder based approach where CNN is used as the Encoder and sequence generator like RNN as Decoder has proven to be very effective. However, this method has a drawback that is sequence needs to be processed in order. To overcome this drawback some researcher has utilized the Transformer model to generate captions from images using English datasets. However, none of them generated captions in Bengali using the transformer model. As a result, we utilized three different Bengali datasets to generate Bengali captions from images using the Transformer model. Additionally, we compared the performance of the transformer-based model with a visual attention-based Encoder-Decoder approach. Finally, we compared the result of the transformer-based model with other models that employed different Bengali image captioning datasets.