 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling and Predicting Blood Flow Characteristics through Double Stenosed Artery from CFD simulation using Deep Learning Models
Dec 04, 2021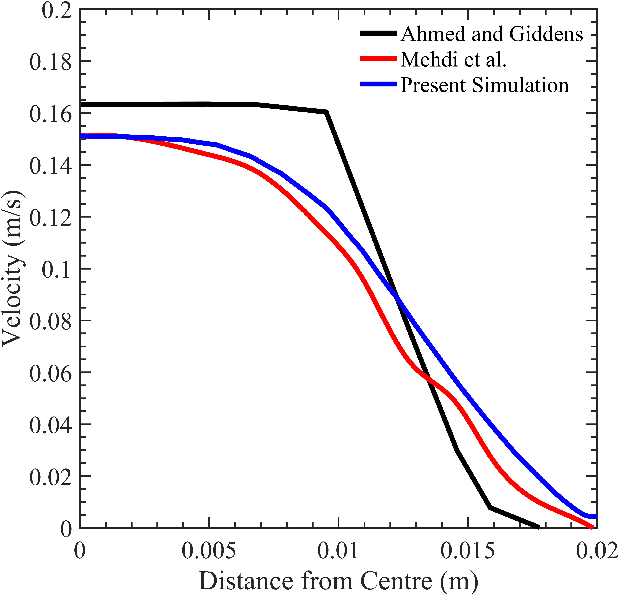



Establishing patient-specific finite element analysis (FEA) models for computational fluid dynamics (CFD) of double stenosed artery models involves time and effort, restricting physicians' ability to respond quickly in time-critical medical applications. Such issues might be addressed by training deep learning (DL) models to learn and predict blood flow characteristics using a dataset generated by CFD simulations of simplified double stenosed artery models with different configurations. When blood flow patterns are compared through an actual double stenosed artery model, derived from IVUS imaging, it is revealed that the sinusoidal approximation of stenosed neck geometry, which has been widely used in previous research works, fails to effectively represent the effects of a real constriction. As a result, a novel geometric representation of the constricted neck is proposed which, in terms of a generalized simplified model, outperforms the former assumption. The sequential change in artery lumen diameter and flow parameters along the length of the vessel presented opportunities for the use of LSTM and GRU DL models. However, with the small dataset of short lengths of doubly constricted blood arteries, the basic neural network model outperforms the specialized RNNs for most flow properties. LSTM, on the other hand, performs better for predicting flow properties with large fluctuations, such as varying blood pressure over the length of the vessels. Despite having good overall accuracies in training and testing across all the properties for the vessels in the dataset, the GRU model underperforms for an individual vessel flow prediction in all cases. The results also point to the need of individually optimized hyperparameters for each property in any model rather than aiming to achieve overall good performance across all outputs with a single set of hyperparameters.
Bornon: Bengali Image Captioning with Transformer-based Deep learning approach
Sep 11, 2021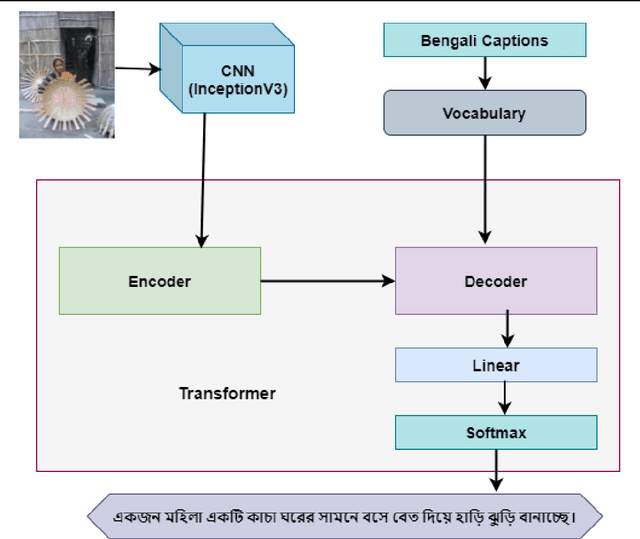


Image captioning using Encoder-Decoder based approach where CNN is used as the Encoder and sequence generator like RNN as Decoder has proven to be very effective. However, this method has a drawback that is sequence needs to be processed in order. To overcome this drawback some researcher has utilized the Transformer model to generate captions from images using English datasets. However, none of them generated captions in Bengali using the transformer model. As a result, we utilized three different Bengali datasets to generate Bengali captions from images using the Transformer model. Additionally, we compared the performance of the transformer-based model with a visual attention-based Encoder-Decoder approach. Finally, we compared the result of the transformer-based model with other models that employed different Bengali image captioning datasets.