 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Embedding with Transformer for High-dimensional Data
Feb 20, 2024Quantum embedding with transformers is a novel and promising architecture for quantum machine learning to deliver exceptional capability on near-term devices or simulators. The research incorporated a vision transformer (ViT) to advance quantum significantly embedding ability and results for a single qubit classifier with around 3 percent in the median F1 score on the BirdCLEF-2021, a challenging high-dimensional dataset. The study showcases and analyzes empirical evidence that our transformer-based architecture is a highly versatile and practical approach to modern quantum machine learning problems.
Hybrid Quantum Neural Network in High-dimensional Data Classification
Dec 02, 2023The research explores the potential of quantum deep learning models to address challenging machine learning problems that classical deep learning models find difficult to tackle. We introduce a novel model architecture that combines classical convolutional layers with a quantum neural network, aiming to surpass state-of-the-art accuracy while maintaining a compact model size. The experiment is to classify high-dimensional audio data from the Bird-CLEF 2021 dataset. Our evaluation focuses on key metrics, including training duration, model accuracy, and total model size. This research demonstrates the promising potential of quantum machine learning in enhancing machine learning tasks and solving practical machine learning challenges available today.
BLIP-Adapter: Parameter-Efficient Transfer Learning for Mobile Screenshot Captioning
Sep 26, 2023



This study aims to explore efficient tuning methods for the screenshot captioning task. Recently, image captioning has seen significant advancements, but research in captioning tasks for mobile screens remains relatively scarce. Current datasets and use cases describing user behaviors within product screenshots are notably limited. Consequently, we sought to fine-tune pre-existing models for the screenshot captioning task. However, fine-tuning large pre-trained models can be resource-intensive, requiring considerable time, computational power, and storage due to the vast number of parameters in image captioning models. To tackle this challenge, this study proposes a combination of adapter methods, which necessitates tuning only the additional modules on the model. These methods are originally designed for vision or language tasks, and our intention is to apply them to address similar challenges in screenshot captioning. By freezing the parameters of the image caption models and training only the weights associated with the methods, performance comparable to fine-tuning the entire model can be achieved, while significantly reducing the number of parameters. This study represents the first comprehensive investigation into the effectiveness of combining adapters within the context of the screenshot captioning task. Through our experiments and analyses, this study aims to provide valuable insights into the application of adapters in vision-language models and contribute to the development of efficient tuning techniques for the screenshot captioning task. Our study is available at https://github.com/RainYuGG/BLIP-Adapter
RelGAN: Multi-Domain Image-to-Image Translation via Relative Attributes
Aug 20, 2019
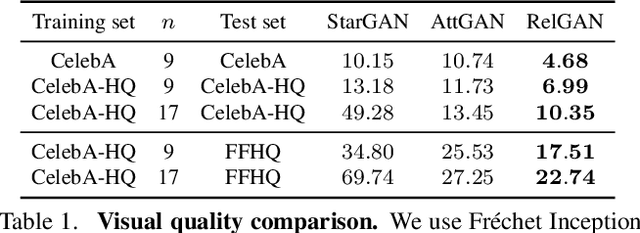
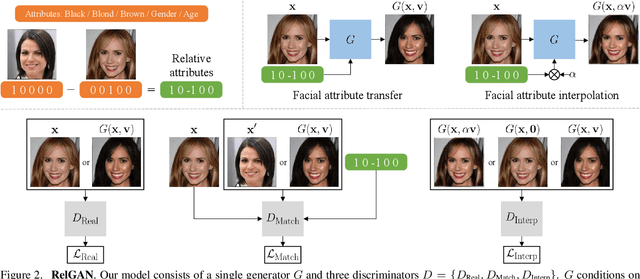
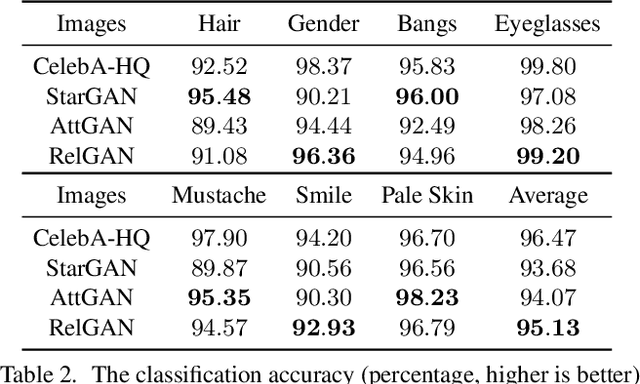
Multi-domain image-to-image translation has gained increasing attention recently. Previous methods take an image and some target attributes as inputs and generate an output image with the desired attributes. However, such methods have two limitations. First, these methods assume binary-valued attributes and thus cannot yield satisfactory results for fine-grained control. Second, these methods require specifying the entire set of target attributes, even if most of the attributes would not be changed. To address these limitations, we propose RelGAN, a new method for multi-domain image-to-image translation. The key idea is to use relative attributes, which describes the desired change on selected attributes. Our method is capable of modifying images by changing particular attributes of interest in a continuous manner while preserving the other attributes. Experimental results demonstrate both the quantitative and qualitative effectiveness of our method on the tasks of facial attribute transfer and interpolation.