 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHypernetwork-Based Augmentation
Jun 11, 2020

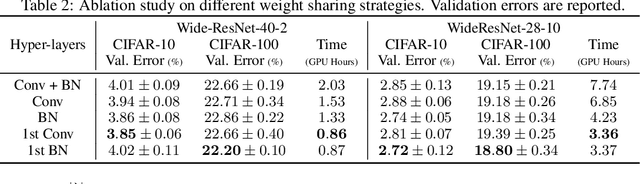
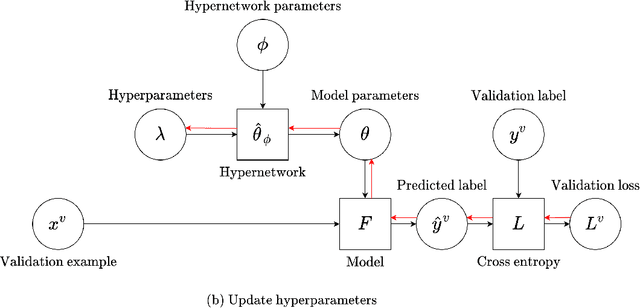
Data augmentation is an effective technique to improve the generalization of deep neural networks. Recently, AutoAugment proposed a well-designed search space and a search algorithm that automatically finds augmentation policies in a data-driven manner. However, AutoAugment is computationally intensive. In this paper, we propose an efficient gradient-based search algorithm, called Hypernetwork-Based Augmentation (HBA), which simultaneously learns model parameters and augmentation hyperparameters in a single training. Our HBA uses a hypernetwork to approximate a population-based training algorithm, which enables us to tune augmentation hyperparameters by gradient descent. Besides, we introduce a weight sharing strategy that simplifies our hypernetwork architecture and speeds up our search algorithm. We conduct experiments on CIFAR-10, CIFAR-100, SVHN, and ImageNet. Our results demonstrate that HBA is significantly faster than state-of-the-art methods while achieving competitive accuracy.
RelGAN: Multi-Domain Image-to-Image Translation via Relative Attributes
Aug 20, 2019
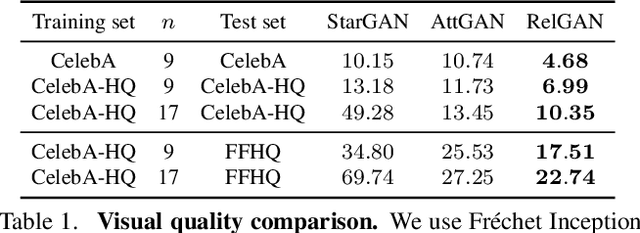
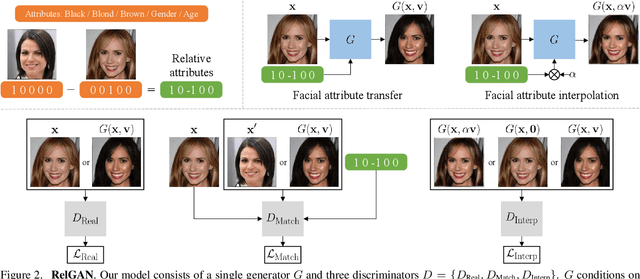
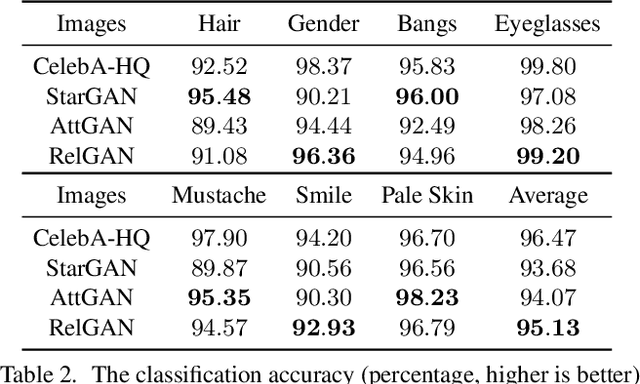
Multi-domain image-to-image translation has gained increasing attention recently. Previous methods take an image and some target attributes as inputs and generate an output image with the desired attributes. However, such methods have two limitations. First, these methods assume binary-valued attributes and thus cannot yield satisfactory results for fine-grained control. Second, these methods require specifying the entire set of target attributes, even if most of the attributes would not be changed. To address these limitations, we propose RelGAN, a new method for multi-domain image-to-image translation. The key idea is to use relative attributes, which describes the desired change on selected attributes. Our method is capable of modifying images by changing particular attributes of interest in a continuous manner while preserving the other attributes. Experimental results demonstrate both the quantitative and qualitative effectiveness of our method on the tasks of facial attribute transfer and interpolation.
KG-GAN: Knowledge-Guided Generative Adversarial Networks
May 29, 2019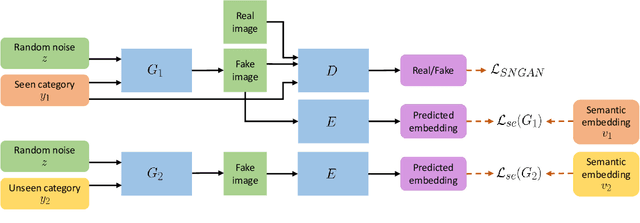

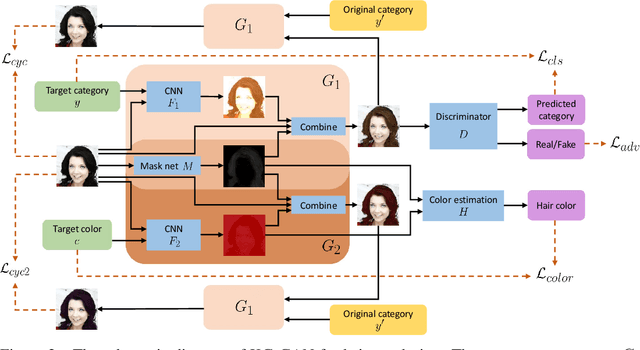

Generative adversarial networks (GANs) learn to mimic training data that represents the underlying true data distribution. However, GANs suffer when the training data lacks quantity or diversity and therefore cannot represent the underlying distribution well. To improve the performance of GANs trained on under-represented training data distributions, this paper proposes KG-GAN to fuse domain knowledge with the GAN framework. KG-GAN trains two generators; one learns from data while the other learns from knowledge. To achieve KG-GAN, domain knowledge is formulated as a constraint function to guide the learning of the second generator. We validate our framework on two tasks: fine-grained image generation and hair recoloring. Experimental results demonstrate the effectiveness of KG-GAN.