 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePDMP: Rethinking Balanced Multimodal Learning via Performance-Dominant Modality Prioritization
Apr 07, 2026Multimodal learning has attracted increasing attention due to its practicality. However, it often suffers from insufficient optimization, where the multimodal model underperforms even compared to its unimodal counterparts. Existing methods attribute this problem to the imbalanced learning between modalities and solve it by gradient modulation. This paper argues that balanced learning is not the optimal setting for multimodal learning. On the contrary, imbalanced learning driven by the performance-dominant modality that has superior unimodal performance can contribute to better multimodal performance. And the under-optimization problem is caused by insufficient learning of the performance-dominant modality. To this end, we propose the Performance-Dominant Modality Prioritization (PDMP) strategy to assist multimodal learning. Specifically, PDMP firstly mines the performance-dominant modality via the performance ranking of the independently trained unimodal model. Then PDMP introduces asymmetric coefficients to modulate the gradients of each modality, enabling the performance-dominant modality to dominate the optimization. Since PDMP only relies on the unimodal performance ranking, it is independent of the structures and fusion methods of the multimodal model and has great potential for practical scenarios. Finally, extensive experiments on various datasets validate the superiority of PDMP.
Unbiased Dynamic Multimodal Fusion
Mar 20, 2026Traditional multimodal methods often assume static modality quality, which limits their adaptability in dynamic real-world scenarios. Thus, dynamical multimodal methods are proposed to assess modality quality and adjust their contribution accordingly. However, they typically rely on empirical metrics, failing to measure the modality quality when noise levels are extremely low or high. Moreover, existing methods usually assume that the initial contribution of each modality is the same, neglecting the intrinsic modality dependency bias. As a result, the modality hard to learn would be doubly penalized, and the performance of dynamical fusion could be inferior to that of static fusion. To address these challenges, we propose the Unbiased Dynamic Multimodal Learning (UDML) framework. Specifically, we introduce a noise-aware uncertainty estimator that adds controlled noise to the modality data and predicts its intensity from the modality feature. This forces the model to learn a clear correspondence between feature corruption and noise level, allowing accurate uncertainty measure across both low- and high-noise conditions. Furthermore, we quantify the inherent modality reliance bias within multimodal networks via modality dropout and incorporate it into the weighting mechanism. This eliminates the dual suppression effect on the hard-to-learn modality. Extensive experiments across diverse multimodal benchmark tasks validate the effectiveness, versatility, and generalizability of the proposed UDML. The code is available at https://github.com/shicaiwei123/UDML.
Robust Multimodal Learning via Representation Decoupling
Jul 05, 2024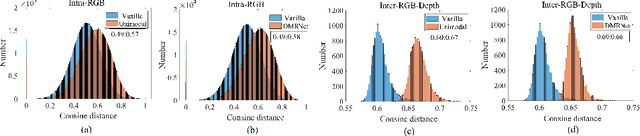
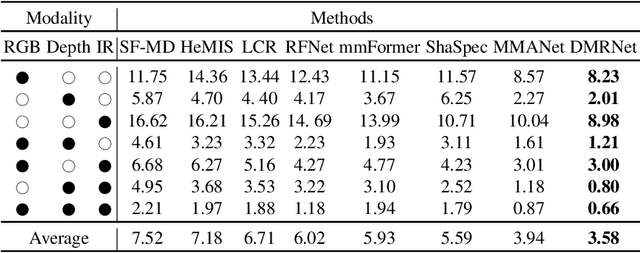
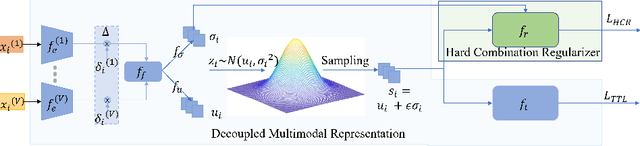
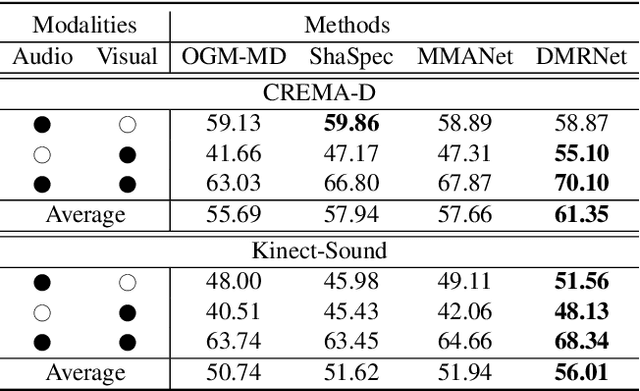
Multimodal learning robust to missing modality has attracted increasing attention due to its practicality. Existing methods tend to address it by learning a common subspace representation for different modality combinations. However, we reveal that they are sub-optimal due to their implicit constraint on intra-class representation. Specifically, the sample with different modalities within the same class will be forced to learn representations in the same direction. This hinders the model from capturing modality-specific information, resulting in insufficient learning. To this end, we propose a novel Decoupled Multimodal Representation Network (DMRNet) to assist robust multimodal learning. Specifically, DMRNet models the input from different modality combinations as a probabilistic distribution instead of a fixed point in the latent space, and samples embeddings from the distribution for the prediction module to calculate the task loss. As a result, the direction constraint from the loss minimization is blocked by the sampled representation. This relaxes the constraint on the inference representation and enables the model to capture the specific information for different modality combinations. Furthermore, we introduce a hard combination regularizer to prevent DMRNet from unbalanced training by guiding it to pay more attention to hard modality combinations. Finally, extensive experiments on multimodal classification and segmentation tasks demonstrate that the proposed DMRNet outperforms the state-of-the-art significantly.
One-stage Modality Distillation for Incomplete Multimodal Learning
Sep 15, 2023



Learning based on multimodal data has attracted increasing interest recently. While a variety of sensory modalities can be collected for training, not all of them are always available in development scenarios, which raises the challenge to infer with incomplete modality. To address this issue, this paper presents a one-stage modality distillation framework that unifies the privileged knowledge transfer and modality information fusion into a single optimization procedure via multi-task learning. Compared with the conventional modality distillation that performs them independently, this helps to capture the valuable representation that can assist the final model inference directly. Specifically, we propose the joint adaptation network for the modality transfer task to preserve the privileged information. This addresses the representation heterogeneity caused by input discrepancy via the joint distribution adaptation. Then, we introduce the cross translation network for the modality fusion task to aggregate the restored and available modality features. It leverages the parameters-sharing strategy to capture the cross-modal cues explicitly. Extensive experiments on RGB-D classification and segmentation tasks demonstrate the proposed multimodal inheritance framework can overcome the problem of incomplete modality input in various scenes and achieve state-of-the-art performance.
MMANet: Margin-aware Distillation and Modality-aware Regularization for Incomplete Multimodal Learning
Apr 17, 2023



Multimodal learning has shown great potentials in numerous scenes and attracts increasing interest recently. However, it often encounters the problem of missing modality data and thus suffers severe performance degradation in practice. To this end, we propose a general framework called MMANet to assist incomplete multimodal learning. It consists of three components: the deployment network used for inference, the teacher network transferring comprehensive multimodal information to the deployment network, and the regularization network guiding the deployment network to balance weak modality combinations. Specifically, we propose a novel margin-aware distillation (MAD) to assist the information transfer by weighing the sample contribution with the classification uncertainty. This encourages the deployment network to focus on the samples near decision boundaries and acquire the refined inter-class margin. Besides, we design a modality-aware regularization (MAR) algorithm to mine the weak modality combinations and guide the regularization network to calculate prediction loss for them. This forces the deployment network to improve its representation ability for the weak modality combinations adaptively. Finally, extensive experiments on multimodal classification and segmentation tasks demonstrate that our MMANet outperforms the state-of-the-art significantly. Code is available at: https://github.com/shicaiwei123/MMANet