 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Multimodal Learning via Representation Decoupling
Paper and Code
Jul 05, 2024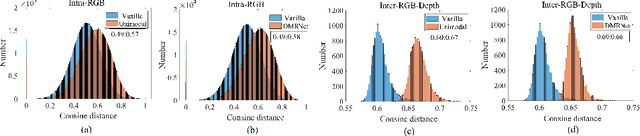
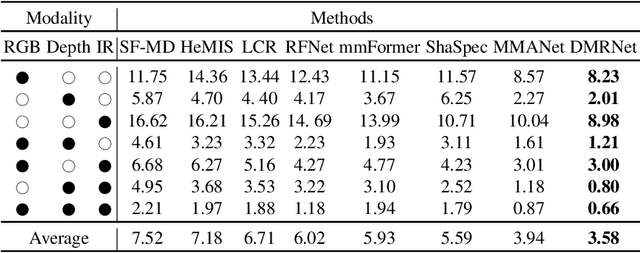
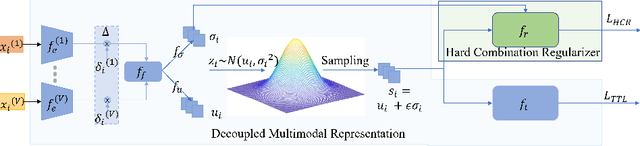
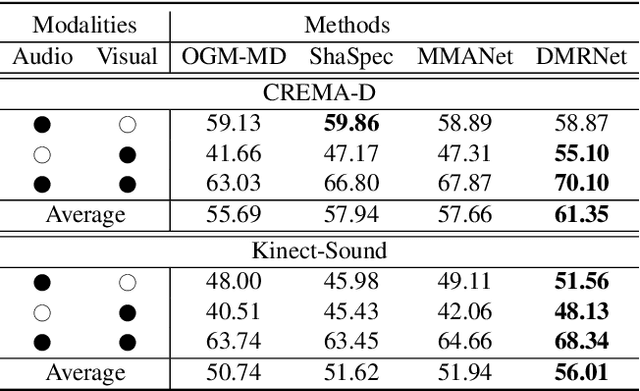
Multimodal learning robust to missing modality has attracted increasing attention due to its practicality. Existing methods tend to address it by learning a common subspace representation for different modality combinations. However, we reveal that they are sub-optimal due to their implicit constraint on intra-class representation. Specifically, the sample with different modalities within the same class will be forced to learn representations in the same direction. This hinders the model from capturing modality-specific information, resulting in insufficient learning. To this end, we propose a novel Decoupled Multimodal Representation Network (DMRNet) to assist robust multimodal learning. Specifically, DMRNet models the input from different modality combinations as a probabilistic distribution instead of a fixed point in the latent space, and samples embeddings from the distribution for the prediction module to calculate the task loss. As a result, the direction constraint from the loss minimization is blocked by the sampled representation. This relaxes the constraint on the inference representation and enables the model to capture the specific information for different modality combinations. Furthermore, we introduce a hard combination regularizer to prevent DMRNet from unbalanced training by guiding it to pay more attention to hard modality combinations. Finally, extensive experiments on multimodal classification and segmentation tasks demonstrate that the proposed DMRNet outperforms the state-of-the-art significantly.