 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Interpretable Implicit-Based Approach for Modeling Local Spatial Effects: A Case Study of Global Gross Primary Productivity
Feb 10, 2025



In Earth sciences, unobserved factors exhibit non-stationary spatial distributions, causing the relationships between features and targets to display spatial heterogeneity. In geographic machine learning tasks, conventional statistical learning methods often struggle to capture spatial heterogeneity, leading to unsatisfactory prediction accuracy and unreliable interpretability. While approaches like Geographically Weighted Regression (GWR) capture local variations, they fall short of uncovering global patterns and tracking the continuous evolution of spatial heterogeneity. Motivated by this limitation, we propose a novel perspective - that is, simultaneously modeling common features across different locations alongside spatial differences using deep neural networks. The proposed method is a dual-branch neural network with an encoder-decoder structure. In the encoding stage, the method aggregates node information in a spatiotemporal conditional graph using GCN and LSTM, encoding location-specific spatiotemporal heterogeneity as an implicit conditional vector. Additionally, a self-attention-based encoder is used to extract location-invariant common features from the data. In the decoding stage, the approach employs a conditional generation strategy that predicts response variables and interpretative weights based on data features under spatiotemporal conditions. The approach is validated by predicting vegetation gross primary productivity (GPP) using global climate and land cover data from 2001 to 2020. Trained on 50 million samples and tested on 2.8 million, the proposed model achieves an RMSE of 0.836, outperforming LightGBM (1.063) and TabNet (0.944). Visualization analyses indicate that our method can reveal the distribution differences of the dominant factors of GPP across various times and locations.
Tree-GPT: Modular Large Language Model Expert System for Forest Remote Sensing Image Understanding and Interactive Analysis
Oct 07, 2023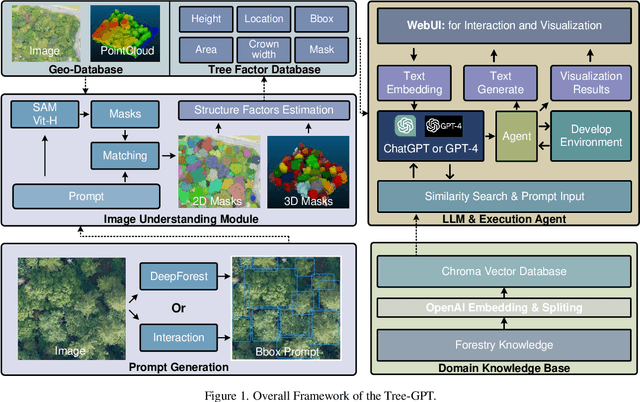
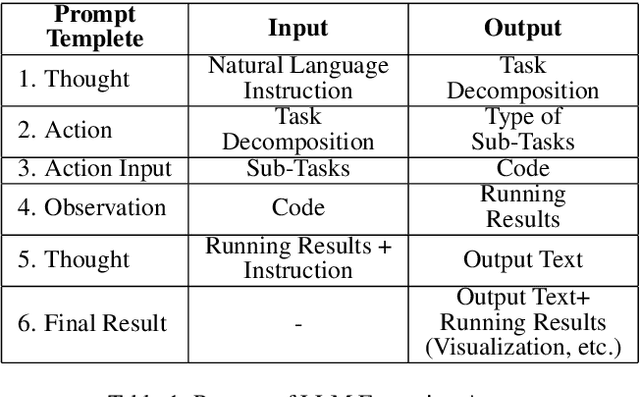

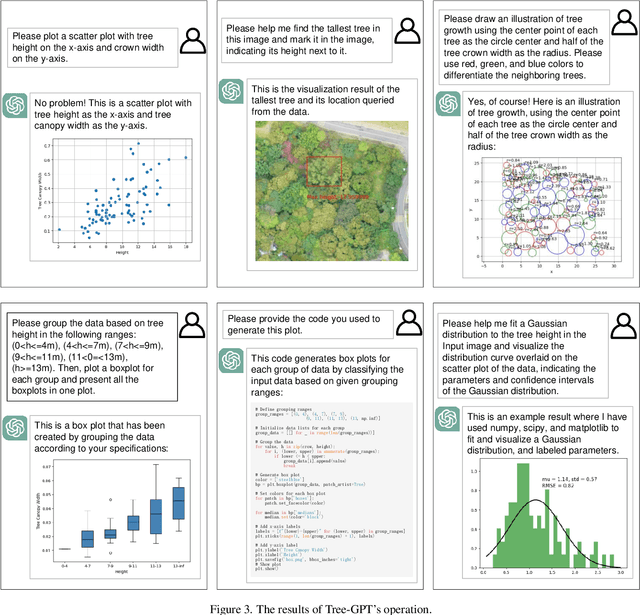
This paper introduces a novel framework, Tree-GPT, which incorporates Large Language Models (LLMs) into the forestry remote sensing data workflow, thereby enhancing the efficiency of data analysis. Currently, LLMs are unable to extract or comprehend information from images and may generate inaccurate text due to a lack of domain knowledge, limiting their use in forestry data analysis. To address this issue, we propose a modular LLM expert system, Tree-GPT, that integrates image understanding modules, domain knowledge bases, and toolchains. This empowers LLMs with the ability to comprehend images, acquire accurate knowledge, generate code, and perform data analysis in a local environment. Specifically, the image understanding module extracts structured information from forest remote sensing images by utilizing automatic or interactive generation of prompts to guide the Segment Anything Model (SAM) in generating and selecting optimal tree segmentation results. The system then calculates tree structural parameters based on these results and stores them in a database. Upon receiving a specific natural language instruction, the LLM generates code based on a thought chain to accomplish the analysis task. The code is then executed by an LLM agent in a local environment and . For ecological parameter calculations, the system retrieves the corresponding knowledge from the knowledge base and inputs it into the LLM to guide the generation of accurate code. We tested this system on several tasks, including Search, Visualization, and Machine Learning Analysis. The prototype system performed well, demonstrating the potential for dynamic usage of LLMs in forestry research and environmental sciences.
AsymFormer: Asymmetrical Cross-Modal Representation Learning for Mobile Platform Real-Time RGB-D Semantic Segmentation
Sep 26, 2023In the realm of robotic intelligence, achieving efficient and precise RGB-D semantic segmentation is a key cornerstone. State-of-the-art multimodal semantic segmentation methods, primarily rooted in symmetrical skeleton networks, find it challenging to harmonize computational efficiency and precision. In this work, we propose AsymFormer, a novel network for real-time RGB-D semantic segmentation, which targets the minimization of superfluous parameters by optimizing the distribution of computational resources and introduces an asymmetrical backbone to allow for the effective fusion of multimodal features. Furthermore, we explore techniques to bolster network accuracy by redefining feature selection and extracting multi-modal self-similarity features without a substantial increase in the parameter count, thereby ensuring real-time execution on robotic platforms. Additionally, a Local Attention-Guided Feature Selection (LAFS) module is used to selectively fuse features from different modalities by leveraging their dependencies. Subsequently, a Cross-Modal Attention-Guided Feature Correlation Embedding (CMA) module is introduced to further extract cross-modal representations. This method is evaluated on NYUv2 and SUNRGBD datasets, with AsymFormer demonstrating competitive results with 52.0% mIoU on NYUv2 and 49.1% mIoU on SUNRGBD. Notably, AsymFormer achieves an inference speed of 65 FPS and after implementing mixed precision quantization, it attains an impressive inference speed of 79 FPS on RTX3090. This significantly outperforms existing multi-modal methods, thereby demonstrating that AsymFormer can strike a balance between high accuracy and efficiency for RGB-D semantic segmentation.