 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction recognition in still images by latent superpixel classification
Jul 30, 2015
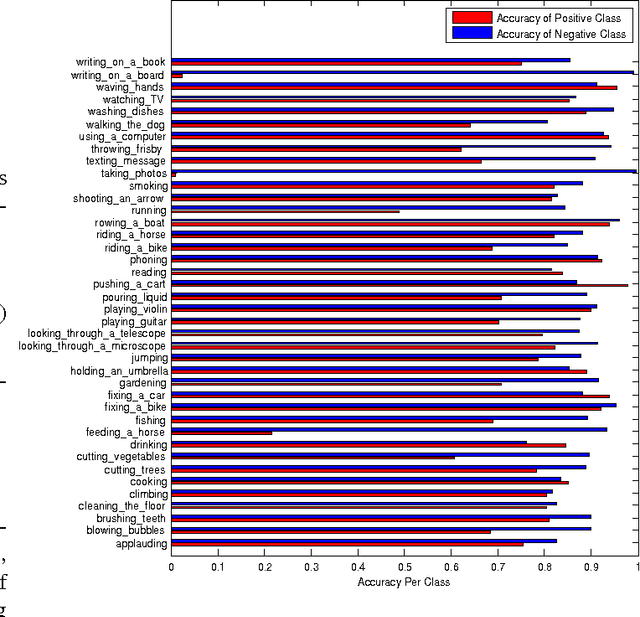
Action recognition from still images is an important task of computer vision applications such as image annotation, robotic navigation, video surveillance and several others. Existing approaches mainly rely on either bag-of-feature representations or articulated body-part models. However, the relationship between the action and the image segments is still substantially unexplored. For this reason, in this paper we propose to approach action recognition by leveraging an intermediate layer of "superpixels" whose latent classes can act as attributes of the action. In the proposed approach, the action class is predicted by a structural model(learnt by Latent Structural SVM) based on measurements from the image superpixels and their latent classes. Experimental results over the challenging Stanford 40 Actions dataset report a significant average accuracy of 74.06% for the positive class and 88.50% for the negative class, giving evidence to the performance of the proposed approach.